
CONTEXTO
Los documentos de los mercados públicos manifiestan una importante heterogeneidad y similitudes. Por otra parte, estos documentos contienen generalmente información típica como el nombre del organismo público, su código SIRET, su localización geográfica, las fechas, los criterios y las modalidades de selección de los candidatos, etc. Sin embargo, estos datos se presentan generalmente sin ningún formato estructurado y se expresan de varias maneras.
El objetivo es construir un sistema que permita a un usuario lanzar una solicitud de búsqueda y recuperar un conjunto de documentos de mercados públicos pertinentes en relación con la solicitud realizada. A continuación, a partir de los resultados obtenidos, se realiza una fase de extracción de información, entidades y conocimientos.
Además, esta aplicación ilustra la demostración de un motor de búsqueda, la clasificación automática de documentos por su tipo de mercado y, finalmente, la extracción de información y entidades de interés.
El enfoque utilizado coincide con varios ámbitos científicos como la búsqueda de información, le tratamiento del lenguaje natural y l'apprentissage automatique.
Las tecnologías implicadas se basan principalmente en el lenguaje Python y sus librerías (por ejemplo Frasco, Whoosh, Scikit-learn).
Démo 1: MOTEUR DE RECHERCHE D'APPEL D'OFFRE
El objetivo es permitir a un usuario interesado en los documentos de los mercados públicos la posibilidad de lanzar solicitudes y recuperar los documentos pertinentes en relación con dichas solicitudes. Este sistema de búsqueda se basa en la indexación de documentos y se refiere como resultados a un conjunto de documentos clasificados por una puntuación de pertinencia (p. ej. Okapi BM25).
Démo 2: EXTRACCIÓN DE INFORMACIONES
¿Cómo funciona?
Tras la fase de búsqueda de documentos, se requiere una fase aún más importante. Esta última corresponde a la extracción automática de información y entidades (por ejemplo, la fecha límite de entrega de las ofertas, el tipo de mercado, los criterios de atribución de un mercado).
La extracción se realiza siguiendo el siguiente esquema:
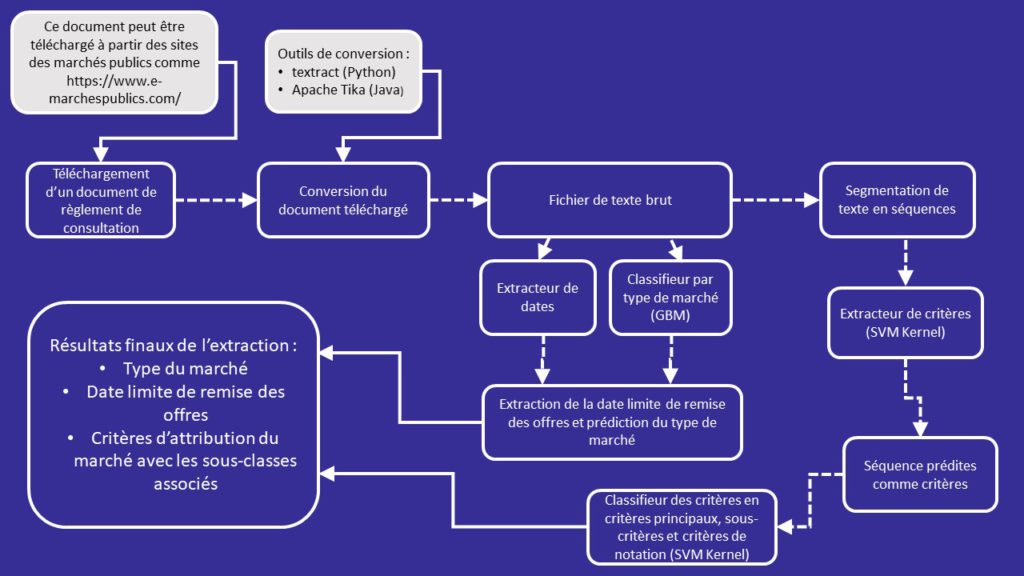
Para ello, hemos construido tres robots:
- El primero, que se basa en una investigación local con un patrón de extracción de datos muy general;
- La segunda, que es una máquina inteligente de tipo GBM y que intenta clasificar cada documento en función de su tipo de mercado;
- El último que combina dos máquinas inteligentes, de tipo SVM, dentro de un marco de clasificación en cascada:
- La primera máquina recibe un documento de texto en bruto y devuelve un fragmento de texto con los criterios ;
- La segunda máquina tomará como entrada la parte del texto que se ha propuesto como criterio y aplicará una clasificación más fina detectando los criterios principales, los subcriterios y las frases que especifiquen la notación aplicada.



