Demostración: La inteligencia artificial y la búsqueda de información al servicio de BL.ActesOffice
El módulo presentado en esta demostración permite buscar documentos en una parte de la base de ActesOffice basándose en técnicas pertenecientes al ámbito de la inteligencia artificial (IA), del tratamiento automático de idiomas (TAL) y de la búsqueda de información (RI). Estos tres ámbitos científicos y tecnológicos tienen mucho en común: tratan todos los textos expresados en lenguaje natural.
La representación de los documentos dentro de un sistema de RI y el cálculo de la similitud entre estas representaciones son dos problemas diferentes que hemos tratado en este proyecto de investigación y desarrollo.
Con el fin de dar una representación semántica a los documentos que tiene su sentido, nos basamos en un modelo de lenguaje elaborado a partir de un corpus de tamaño muy importante procedente del dominio .fr (para más detalles, véase la sección Descripción del enfoque). Este mismo modelo se ha utilizado para dar una representación semántica a la solicitud; cuando se utiliza la medida de similitud para comparar la representación de la solicitud con las representaciones de los documentos, hemos utilizado la medida Cosinus.
Descripción del enfoque: hacia una búsqueda de documentos por similitud semántica y utilización de plongements lexicales (word embeddings)
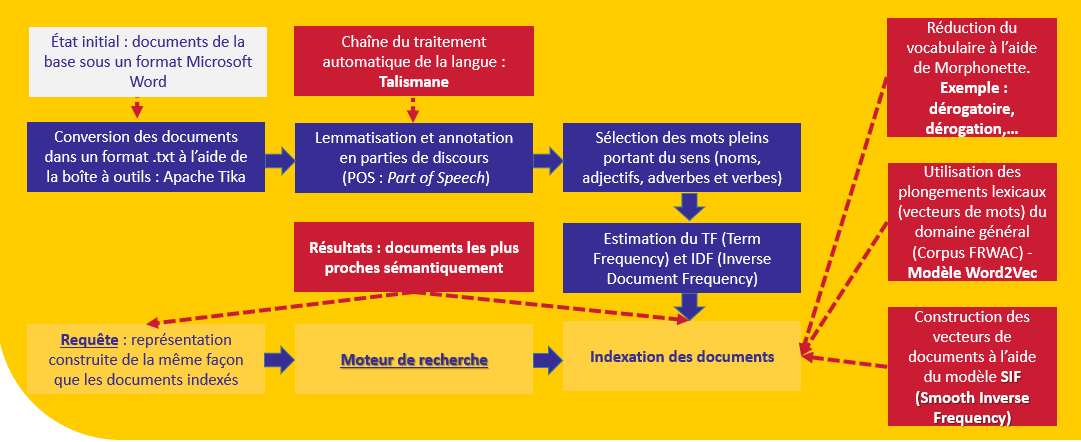
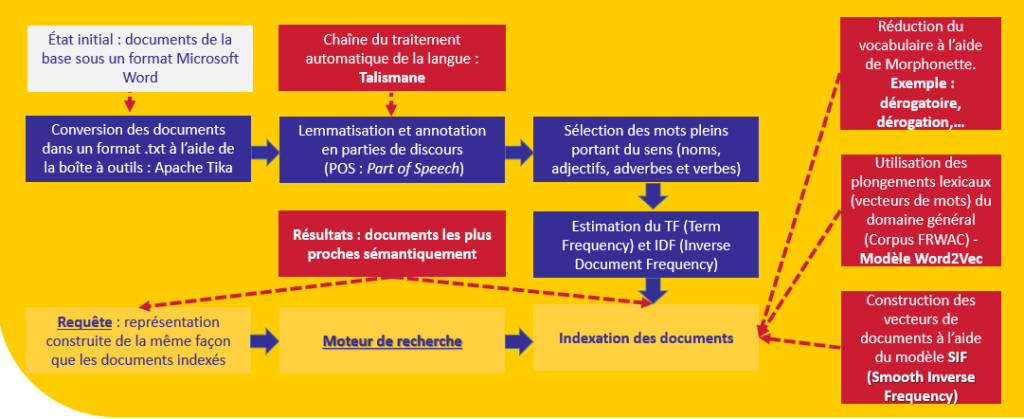
Los documentos de la base están indexados con una representación que permite medir su relación con la solicitud. Nuestro objetivo principal es dar sentido al contenido textual de estos documentos.
Se utilizan varios recursos para llegar a esta indexación:
Sistemas propuestos
El modelo de lenguaje que hemos utilizado (a saber, Word2Vec con una arquitectura CBOW - Bolsa de palabras continua) ha sido introducido en el cuerpo frWaC (corpus français du domaine .fr). Este corpus contiene cerca de dos millones de palabras. Hemos utilizado el modelo Word2Vec propuesto por Jean-Philippe Fauconnier (derecho de acceso).
Es posible que el modelo utilizado no proponga una representación de las palabras expresadas en la solicitud:

Tipos de solicitudes
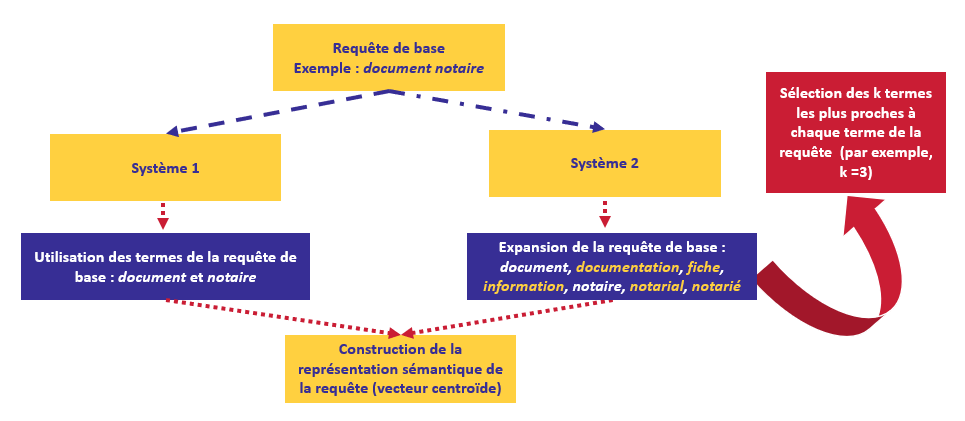
Proponemos dos maneras de investigar la base:
- Sólo se tienen en cuenta las palabras de la solicitud original para integrar la base,
- Tenemos en cuenta no sólo las palabras de la solicitud original, sino también las tres palabras más próximas a cada palabra de la solicitud original.
Comment ça marche ?
El usuario debe proporcionar su solicitud en el campo de búsqueda y el tipo de esta solicitud (simple ou étendu).
Si el tipo elegido para la solicitud es simple entonces la representación de la solicitud tiene en cuenta únicamente las palabras expresadas por el usuario. En caso contrario, si el tipo es étendu además, las palabras que se repiten son eliminadas de la solicitud inicial.
Por ejemplo, si la solicitud inicial es Entreprise travaux publicsLa solicitud ampliada se expresa como sigue: entreprise, público, trabajo, chantier, colectividad, pme, pme-pmi, priver, profesión, salarié y territorial.
El resultado de la investigación se presenta en forma de tabla que permite realizar diferentes manipulaciones (tri, filtrado, por ejemplo).
Este cuadro contiene cuatro columnas, a saber:
- Rang du document : los documentos se trian según la puntuación de similitud semántica (expresada en puntuación de confianza),
- Puntuación de confianza : Expresa la relación entre la puntuación de similitud semántica del primer documento (el primero de la tabla) y la puntuación de similitud del documento a tratar,
- Primeras líneas : un primer fragmento de texto del documento a tratar,
- Texto íntegro : un enlace para consultar el texto en su totalidad.
Si el usuario desea buscar exactamente una cadena de caracteres en la base, puede rellenarla con guillemets (por ejemplo " y ", soit “ y “).
Contacte con
Mokhtar Boumedyen BILLAMI (E-Mail : mokhtarboumedyen.billami@berger-levrault.com)
Christophe BORTOLASO (E-Mail : christophe.bortolaso@berger-levrault.com)