
Cuando los equipos de nuestros clientes necesitan una intervención de mantenimiento por cualquier motivo, pueden solicitarla a través de Carl Source, nuestro software de GMAO.
Estas intervenciones consultas será recibido por el servicio técnico que lo analizará, lo precalificará y asociarlo a un tipo de intervención antes de programarlo. Algunas intervenciones son más urgentes que otras y algunos necesitan una especificidad técnica o una habilidad especial. Puede convertirse fácilmente en un rompecabezas. Por lo tanto, si el número de consultas se vuelven realmente importantes, el responsable puede verse rápidamente desbordado en su trabajo.
Para facilitar su trabajo y hacer más eficiente su intervención en el horario, trabajamos en un algoritmo para analizar y clasificar la intervención consultas y proporcionar información de ayuda a la persona encargada de programar la intervención de mantenimiento.
Nuestra solución se compone de tres unidades principales. La primera unidad está dedicada a recogida y explotación de datosla segunda unidad extraer conocimientos y transformar los datos brutos recogidos en datos útilesy en la última unidad, los datos transformados se clasificarán por tipo de intervención (en algunos casos, el algoritmo puede sugerir diferentes tipos de la intervención). Con esa información, el responsable puede decidir para asociar la consulta a una intervención con el técnico adecuado.
En este proyecto, es muy importante saber en qué consiste el mantenimiento. El mantenimiento puede ser necesario en varias áreas de negocio como la industria, la energía, el transporte, etc. y por diferentes razones. Puede ser por razones correctivas cuando se produce un fallo en el equipo, por razones preventivas para evitar un fallo futuro debido al tiempo, por ejemplo, o por mantenimiento predictivo cuando la actividad de la máquina se mide con la tecnología IoT y puede prevenir su propia avería.
Comprensión de los datos
Desde nuestra red privada, recogimos la intervención consultas datos de 22 clientes. Es importante saber que la intervención consultas Los formularios pueden ser personalizados por cada cliente, en función de sus necesidades. Por eso hay que seleccionar los requisitos más indicativos y comunes.
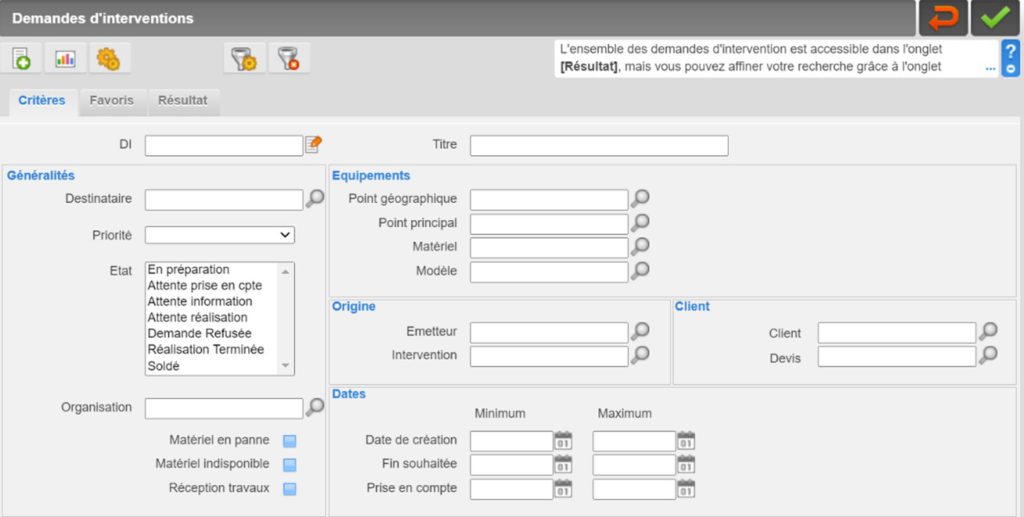
Una vez exportados, los datos se ven como en la figura 3 presentada a continuación.

Para uniformar esos datos, seleccionamos la información más relevante y comunitaria para clasificar las consultas de intervención. Las informaciones seleccionadas son: el nombre de los clientes, consulta de intervención ID, el grado de prioridad, el estado actual de la consulta, la fecha de creación, el equipo afectado, la consulta título y su descripción.
Al revisar estos datos brutos, observamos que hay cierto ruido en ellos. Llamamos ruido a las diferencias lingüísticas observadas, como errores ortográficos, palabras en otro idioma, siglas, nombres de marcas, etc. Por eso tenemos que preparar los datos antes de tratarlos.
Preparación de los datos
Para seleccionar la información correcta de los datos recogidos, los clasificamos en dos grupos.
A primer grupo con características variables: el nombre del cliente, la consulta el código, su estado, el grado de prioridad, la fecha y la identificación del equipo en cuestión. A segundo grupo para las variables informativas que son en nuestro caso: el título, la descripción de la consulta y el nombre del equipo.
Ahora, tenemos que preparar los datos para su tratamiento. Para ello, tenemos que pasar por los siguientes pasos de "limpieza":
Tokenización: Esta primera etapa es el punto de entrada de cualquier proceso de PNL. Consiste en transformar la consulta de intervención en una serie de palabras individuales llamadas "tokens".
Supresión de signos de puntuación, símbolos, espacios adicionales y dígitos: Esos elementos no aportan información útil, aunque pueden ser perturbadores en el tratamiento.
Supresión de palabras clave: Las palabras de parada, también llamadas palabras vacías, son términos frecuentes que no aportan información valiosa a la frase. Las eliminamos para reducir el vocabulario del modelo.
Corrección ortográfica: Necesitamos palabras correctamente escritas para interpretarlas. Para corregir las faltas de ortografía, utilizamos Pyenchant que sugieren correcciones para las palabras mal escritas.
Detección y supresión de nombres propios
Detección y supresión de códigos de clientes internos y prueba de consulta de intervención
Reconocimiento del nombre de la entidadcomo ciudades, lugares, marcas, etc.
Identificación de acrónimos
Lemmatización para identificar el mismo expresión con diferentes formas (forma plural, forma conjugada, etc.)
Gestión de sinónimos para reducir el vocabulario del modelo.
Detección y procesamiento de N-gramas: Los N-gramas son asociaciones de palabras que tienen una precisión importante para contextualizar una consulta de intervención. Por ejemplo, el término "fuga de agua" es más preciso que "fuga" por sí solo para determinar el tipo de intervención. Para detectarlos, utilizamos bibliotecas establecidas.
Modelización: Clasificación por dominio de vocabulario
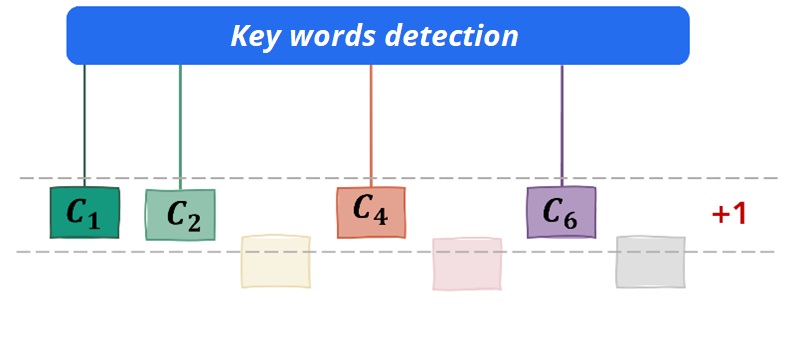
Una vez preparados los datos, podemos clasificar las consultas de intervención analizando el vocabulario utilizado. En el análisis buscamos palabras clave distintivas para clasificar la intervención. Estas palabras clave están en léxicos definidos de antemano y describir cada tipo de intervención.
En este proyecto, tenemos ocho tipos de intervenciones:
- Fontanería: Este tipo de intervención requiere un fontanero con conocimientos específicos y debe realizarse rápidamente en la mayoría de los casos
- Mantenimiento de la propiedad: Requiere un técnico multitarea para hacer todo tipo de mantenimiento general y no es urgente en general
- Electricidad: Estas intervenciones sólo pueden ser realizadas por un electricista y pueden requerir habilidades específicas
- Informática y telefonía: Generalmente son subcontratados o gestionados por un equipo específico.
- Seguridad contra incendios: Por lo general, se subcontrata con un vínculo directo con un gestor
- Mantenimiento de las máquinas: Requiere un técnico especial. Lo más difícil en este tipo de intervención es averiguar la urgencia de la intervención y la importancia del equipo afectado
- Administrativo: Puede ser informe, órdenes, proceso de venta y compra...
- Sin clasificar: Cuando no hay suficiente información en la consulta de la intervención, las palabras utilizadas no están en los léxicos, hay competencias entre diferentes tipos de intervención, etc.
De esas informaciones, el algoritmo busca palabras clave que coincidan con la consulta de intervención y los léxicos. A continuación, aplicamos una puntuación mediante dos métodos.
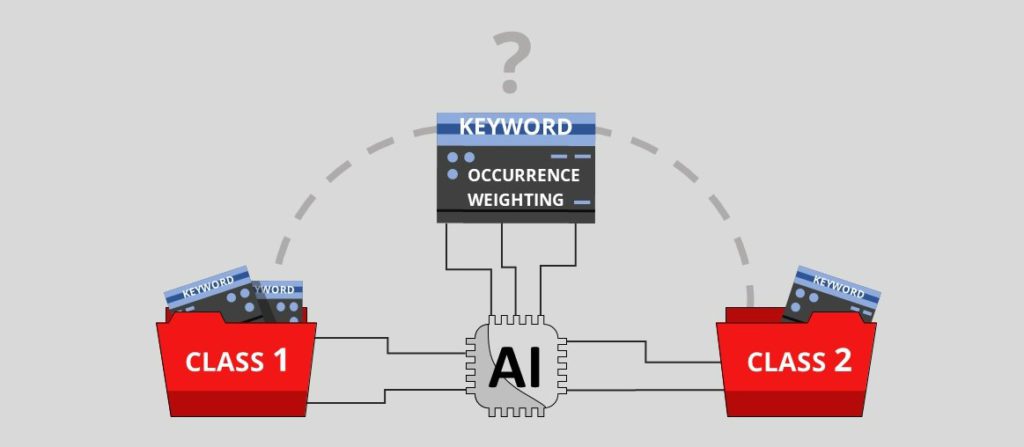
El primer método es cálculo de ocurrenciaPara cada palabra clave que coincida, otorga un punto al tipo de intervención en cuestión y se propondrá al usuario la que tenga la mayor puntuación.
También utilizamos un método de ponderaciónAtribuimos un coeficiente de importancia a algunas palabras y, cuando aparecen en una consulta de intervención, el algoritmo las reconoce como más importantes que otras. Una misma palabra puede aparecer en diferentes léxicos con una puntuación de peso diferente.
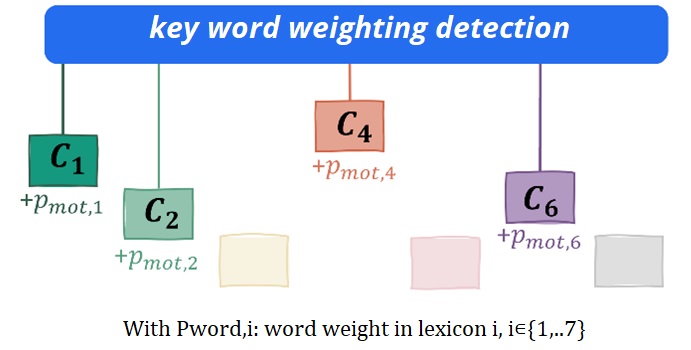
Al mezclar estos dos métodos, la clasificación del algoritmo es más precisa.
Los léxicos se construyen manualmente, pero se enriquecen y su puntuación de ponderación es ajustada por el algoritmo con un proceso de aprendizaje automático basado en la frecuencia de las palabras en una clase, su especificidad y su puntuación de ponderación original. Es importante contar con léxicos bien informados y con las características de puntuación adecuadas para obtener una clasificación precisa.
Evaluación de la clasificación
Después de recoger, comprender y preparar los datos de la consulta de intervención, pudimos clasificarlos gracias a nuestros léxicos bien informados y a los métodos de ocurrencia y ponderación. Un último paso, pero no menos importante, es la evaluación, en la que valoramos los resultados obtenidos por nuestros métodos.
La matriz de confusión es una famosa herramienta de medición en el proceso de aprendizaje automático. Resume los resultados de la clasificación como se puede observar en la Figura 6.

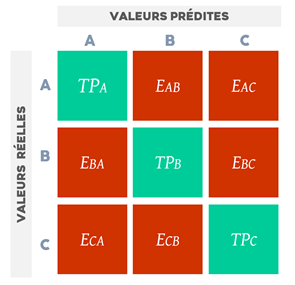
Con esta matriz, podemos evaluar el precisión: el número de consultas bien clasificadas en comparación con el número total de consultas; precisión: el número de consultas bien clasificadas o mal clasificadas en una misma clase; recuerdo o sensibilidad: el número de consultas clasificadas correctamente en una categoría en comparación con el número de consultas que pertenecen a ella; Puntuación Fmedia armónica de la precisión y la recuperación.
Fase de aprendizaje
Para evaluar el rendimiento de aprendizaje de nuestra solución, recogimos 999 consultas de intervención de forma aleatoria. Las categorizamos manualmente para comparar nuestra categorización con el resultado generado.
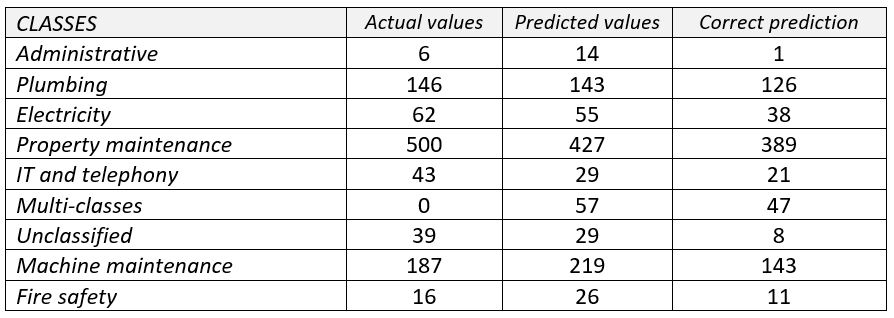
El resultado muestra una precisión de 78,2% de nuestro modelo. En él, hubo 5,7% de consultas de intervención multiclase con 82,46% de ellas correctamente categorizadas. Hemos observado una tasa de precisión realmente baja en la clase administrativa debido a los datos de aprendizaje desequilibrados que la hacen genérica. Sin embargo, otras categorías tienen resultados bastante buenos. El resultado de precisión es de 60,6% y el de recall es de 61,85%.
Fase de pruebas
Para evaluar su capacidad de generalización, recogimos 922 consultas de intervención de cinco nuevos clientes y las clasificamos manualmente para compararlas con la generación.
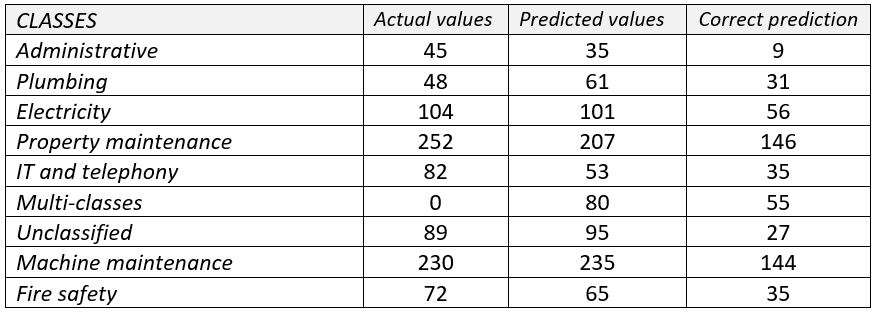
El índice de exactitud se redujo a 58,3% en la fase de prueba, con un resultado de precisión de 52% y un resultado de recuerdo de 54,8%. El modelo tiene una mejor supervisión en algunos clientes que en otros, lo que puede explicarse por las diferencias de las áreas de negocio. Estos resultados permiten constatar la incapacidad de nuestro modelo para detectar e integrar otras clases que las ya establecidas.
Con este proyecto, proponemos una herramienta de ayuda a la decisión para asistir al equipo técnico sobre el tratamiento de la consulta de intervención. Nuestro algoritmo permite la intervención consulta precalificación automática proponer una clasificación al gestor, que puede asociarla a una intervención real. Le ayuda en la gestión del flujo de consultas y en la optimización de la programación. Nuestra solución tiene buenos resultados para consultas claras con términos específicos gracias al método de ocurrencia, pero se puede mejorar trabajando en los léxicos y estableciendo un equilibrio adecuado entre los glosarios para no confundirlos.



