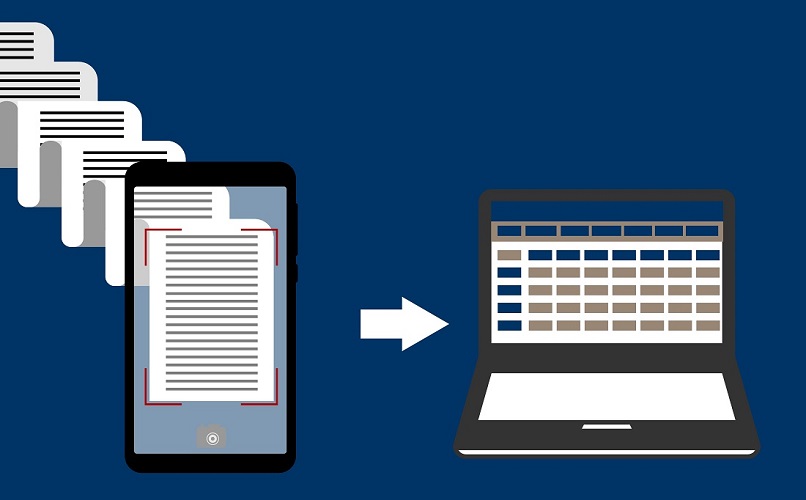
Notre époque est de plus en plus marquée par la prévalence de grands volumes de données. Ces données cachent le plus souvent une grande intelligence humaine. Cette connaissance intrinsèque, quel que soit le domaine, permettrait à nos systèmes d'information d'être beaucoup plus efficaces dans le traitement et l'interprétation des données structurées et non structurées. Par exemple, le processus de recherche de documents pertinents ou de regroupement de documents pour en tirer des sujets n'est pas toujours facilité, lorsque les documents sont issus d'un domaine spécifique. De même, la génération automatique de textes pour informer un chatbot ou un voice bot sur la manière de répondre aux besoins de leurs utilisateurs rencontre le même problème : le manque de représentation précise des connaissances de chaque domaine spécifique potentiel qui pourrait être exploité. Ainsi, la plupart des systèmes de recherche et d'extraction d'information reposent sur l'utilisation d'une ou plusieurs bases de connaissances externes, mais ils ont la difficulté de développer et de maintenir des ressources spécifiques à chaque domaine.
Les éléments les plus fondamentaux de la Web sémantique sont les ontologies, qui ont gagné en popularité et en reconnaissance car elles sont considérées comme une réponse aux besoins d'interopérabilité sémantique des systèmes informatiques modernes. Ces bases ontologiques sont des outils très puissants pour la représentation des connaissances. Aujourd'hui, la structuration et la gestion des connaissances sont au cœur des préoccupations des communautés scientifiques. L'augmentation exponentielle des données structurées, semi-structurées et non structurées sur le Web a fait de l'acquisition automatique d'ontologies à partir de textes un domaine de recherche très important. Les ontologies sont largement utilisées dans la recherche d'information (RI), les questions/réponses et les systèmes d'aide à la décision. Une ontologie est une manière formelle et structurelle de représenter les concepts et les relations d'une conceptualisation partagée. Plus précisément, une ontologie peut être définie avec des concepts, des relations, des hiérarchies de concepts et de relations, et des axiomes présents pour un domaine donné. Cependant, la construction de grandes ontologies est une tâche difficile, et il est impossible de les construire pour tous les domaines possibles. Concrètement, la construction manuelle d'une ontologie est une tâche qui demande beaucoup de travail. Bien que les données non structurées puissent être transformées en données structurées, cette construction implique un processus très long et coûteux, surtout lorsque des mises à jour fréquentes sont nécessaires. Par conséquent, au lieu de les développer à la main, la tendance de la recherche s'oriente actuellement vers l'apprentissage automatique des ontologies pour éviter le goulot d'étranglement dans l'acquisition des connaissances.
Les ontologies et Graphiques de connaissances (KG) qui peuvent être déduits apparaissent comme une solution à l'interprétation des vocabulaires hyper-spécialisés. Pour parler de ces vocabulaires, il faut savoir que notre groupe Berger-Levrault propose actuellement plus de 200 livres et des centaines d'articles avec des expertises juridiques et pratiques sur la Portail Légibases. Ce portail couvre 8 domaines :

De plus, les collections d'ouvrages sont thématiques, partiellement annotées, et le résultat d'un important travail éditorial entre Berger-Levrault et de nombreux experts. Comme mentionné au début de cet article, les connaissances qui peuvent être extraites de données volumineuses (dans notre cas, la base éditoriale de Berger-Levrault rédigée en français) sont très utiles pour toute une série d'applications possibles, allant de l'extraction d'information (IE) et de la recherche documentaire à l'enrichissement des connaissances des agents conversationnels afin de répondre au mieux aux besoins des utilisateurs.
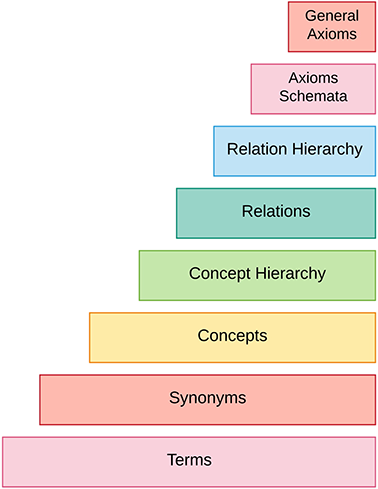
Le processus d'acquisition d'ontologies à partir de textes passe par plusieurs étapes : il commence d'abord par l'identification des termes clés et de leurs synonymes, puis ces termes et synonymes sont combinés pour former des concepts. Ensuite, les relations taxonomiques et non-taxonomiques entre ces concepts sont extraites, par exemple par des méthodes d'inférence. Enfin, les schémas d'axiomes sont instanciés, et les axiomes généraux sont déduits. L'ensemble de ce processus est connu sous le nom de l'apprentissage de l'ontologie en couchescomme le montre la figure ci-dessous.
L'avantage dont nous disposons est que tous les documents de notre base éditoriale (livres et articles) ont une représentation semi-structurée, c'est-à-dire que chaque paragraphe de chaque document est annoté par des experts avec des termes clés. Ces annotations peuvent nous amener à construire des bases ontologiques de bonne qualité lorsque nous constatons que l'identification des termes clés est une étape essentielle de la création d'ontologies.
L'approche que nous proposons consiste à suivre l'évolution de ce processus ci-dessus et à l'appliquer aux domaines du secteur public. Cependant, il faut noter que pour satisfaire chaque étape de ce processus, plusieurs techniques et modèles ont été proposés dans la littérature. Concrètement, notre approche mettra l'accent sur l'apprentissage avec peu de supervision. Le principe consiste à intégrer automatiquement dans une ontologie les instances de concepts et de relations ayant un score de confiance jugé élevé et à valider manuellement les instances ayant un score de confiance faible. Ces validations manuelles nous permettront d'apprendre de nouvelles règles que nous proposons d'intégrer dans le système d'apprentissage afin de limiter au maximum la supervision.
Les progrès récents offerts par les incorporations de mots avec des méthodes de vectorisation telles que Word2Vec, Gant (Vecteurs globaux pour la représentation des mots) ou même BERT (Représentations d'encodeurs bidirectionnels à partir de transformateurs) offrent un potentiel d'analyse de l'information textuelle qui a déjà fait ses preuves dans de nombreuses applications, comme les assistants vocaux et les moteurs de traduction. Pour nos expériences, nous avons choisi de travailler avec BERT pour entraîner un modèle de langage sur la base éditoriale. Ce modèle nous permet ainsi de disposer d'embeddings de mots contextualisés (vecteurs de mots continus contextualisés) pour tous les termes clés que les experts ont sélectionnés.
A titre d'exemple, si l'on prend uniquement les articles des Légibases et uniquement les annotations provenant du thésaurus des 8 domaines, on a en termes d'annotation les éléments suivants :
| Domaine | Nombre de termes clés | Nombre d'articles | Nombre d'annotations |
| État civil et cimetières | 642 | 2767 | 2169 |
| Élections | 108 | 152 | 150 |
| Ordre public | 876 | 1354 | 1201 |
| Urbanisme | 327 | 1357 | 554 |
| Comptabilité et finances locales | 981 | 1971 | 1957 |
| RH régionales | 293 | 361 | 122 |
| Justice | 1447 | 3980 | 870 |
| Santé | 491 | 896 | 830 |
Pour vous donner un aperçu de notre premier travail de traitement de texte sur la base éditoriale, ci-dessous, une figure résumant le traitement effectué pour faire ressortir des termes clés sémantiquement proches :
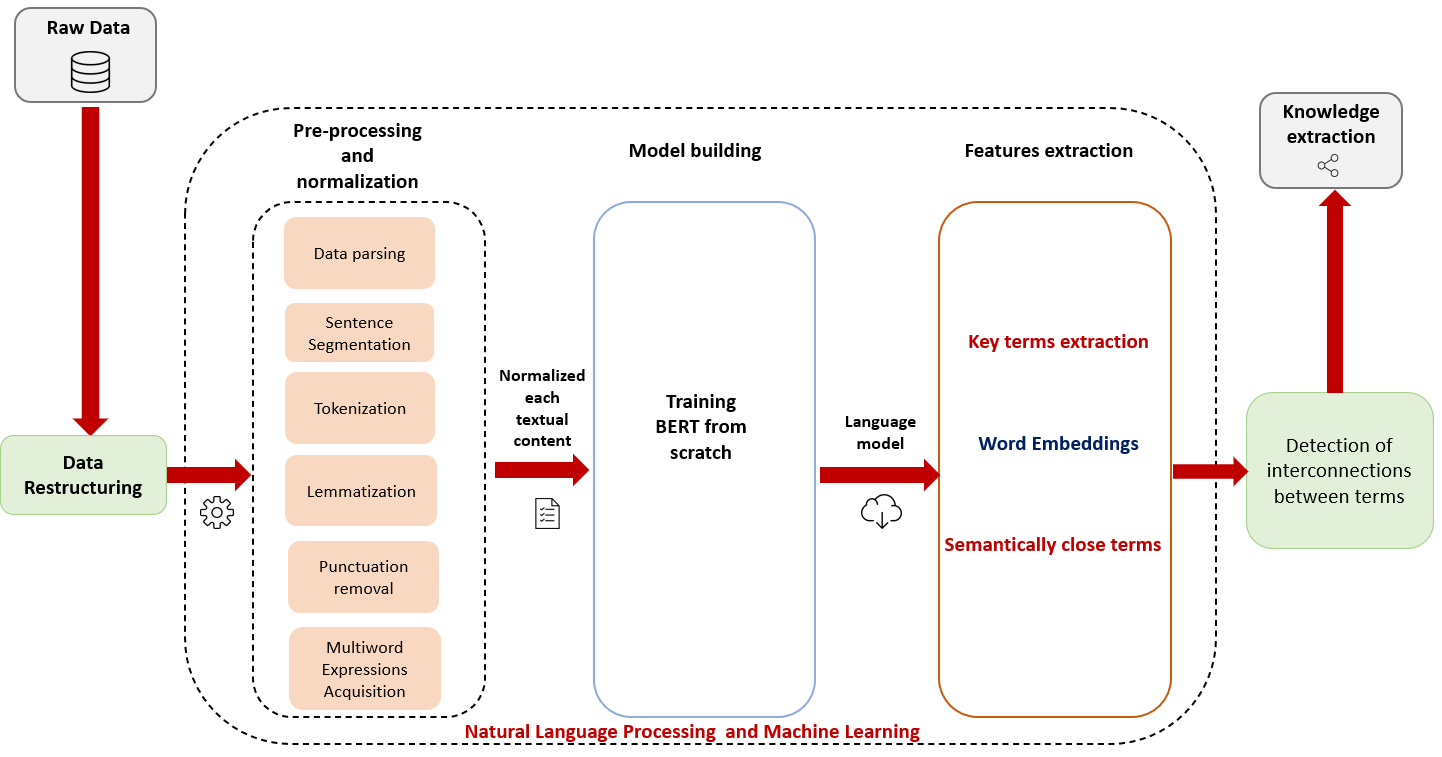
Étape 1 : Pré-traitement et normalisation
Comme première étape de notre approche, nous avons repris les données brutes (RD) stockées dans notre base de données SQL et effectué une tâche de restructuration afin d'obtenir un ensemble organisé de documents HTML, et donc de pouvoir exploiter son contenu. Notez qu'à ce stade, nous identifions les termes nécessaires à notre processus d'apprentissage d'ontologie comme les termes clés annotés par les experts dans chaque paragraphe de chaque document.
Une fois le format requis obtenu, nous lançons le pipeline de prétraitement qui se déroule comme suit :
- Analyse syntaxique des données et segmentation des phrases : analyse les documents HTML et décompose le texte en phrases distinctes.
- Lemmatisation : Dans la plupart des langues, les mots apparaissent sous différentes formes. Regardez ces deux phrases :
" Les députés votent l'abolition de la monarchie constitutionnelle en France. "
" Le député vote l'abolition de la monarchie constitutionnelle en France. "
Les deux phrases parlent de "député"mais ils utilisent des inflexions différentes. Lorsque vous travaillez sur des textes dans un ordinateur, il est utile de connaître la forme de base de chaque mot afin de savoir si les deux phrases parlent du même sens et du même concept ".député". Cela s'avérera particulièrement utile lors de la formation d'intégrations de mots. - Acquisition d'expressions multi-mots (MWE) : remplacement des espaces dans les expressions à plusieurs mots par un trait de soulignement "_", de sorte que le terme soit considéré comme un seul jeton et qu'un seul vecteur d'intégration soit généré pour lui au lieu de deux vecteurs ou plus pour chaque mot qui en fait partie.
Pour préparer le contenu textuel pour l'entraînement des embeddings, nous générons un fichier texte brut, à partir de documents HTML, contenant une phrase par ligne avec des mots-clés unifiés (même représentation).
Étape 2 : Construction du modèle
Maintenant que nous avons un fichier texte normalisé, nous pouvons lancer l'entraînement du modèle de compréhension du langage naturel BERT sur notre fichier texte en utilisant l'infrastructure d'Amazon Web Services (Sagemaker + S3) comme compagnon :

- Construire le vocabulaire : nous allons apprendre un vocabulaire que nous utiliserons pour représenter notre base éditoriale.
- Générer des données de pré-formation : Avec le vocabulaire dont il dispose, BERT peut générer ses données de pré-entraînement.
- Configuration du stockage persistant : pour préserver nos actifs, nous les ferons persister dans le stockage AWS (S3 dans AWS).
Étape 3 : Extraction des caractéristiques
- Génération d'Embeddings de mots/termes.
- Mesurer la similarité Cosinus entre tous les termes clés et déduire ainsi leurs dépendances sémantiques.
Résultats
Voici un aperçu de la distribution de fréquence pour certains termes présents dans notre base éditoriale :
| Termes très courants | Termes communs moyens | Termes moins courants |
| Termes clés / Fréquence des termes (TF) | Termes clés / Fréquence des termes (TF) | Termes clés / Fréquence des termes (TF) |
| code / 125 912 | jury / 3 290 | intérêt commun / 4 |
| loi / 90 177 | famille / 3 280 | association para-administrative / 4 |
| … | … | |
| permis de construire / 7 268 | démocratie / 2 158 | convention d'encaissement de recettes / 1 |
Après avoir obtenu les scores de similarité Cosine entre deux termes donnés, nous construisons un fichier CSV qui contient les 100 termes clés les plus fréquents de notre base éditoriale, leurs 50 mots les plus proches, ainsi que leurs scores de similarité. La figure ci-dessous montre les 100 termes les plus fréquents :

Le fichier est ensuite présenté comme une entrée pour créer le graphe étiqueté suivant représentant les dépendances sémantiques obtenues lors des étapes précédentes :
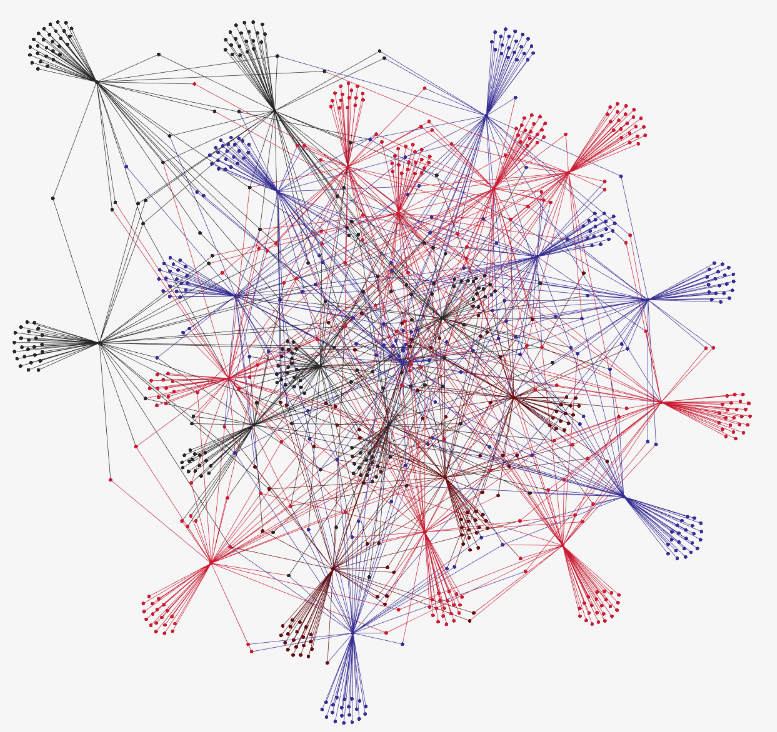
À titre d'exemple, nous vous montrons ci-dessous les termes les plus proches sémantiquement de "droit" :

Nous rappelons que nous présentons ici le premier travail que nous avons réalisé pour l'étude du corpus de la base éditoriale et que la suite de ce travail nous conduira à appliquer des techniques d'extraction de concepts et de relations en utilisant différents niveaux d'analyse, à savoir : le niveau linguistique, statistique et sémantique.