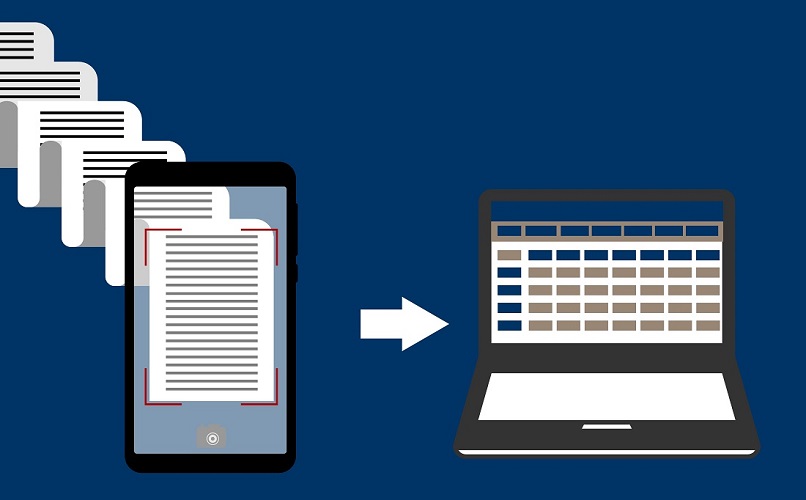

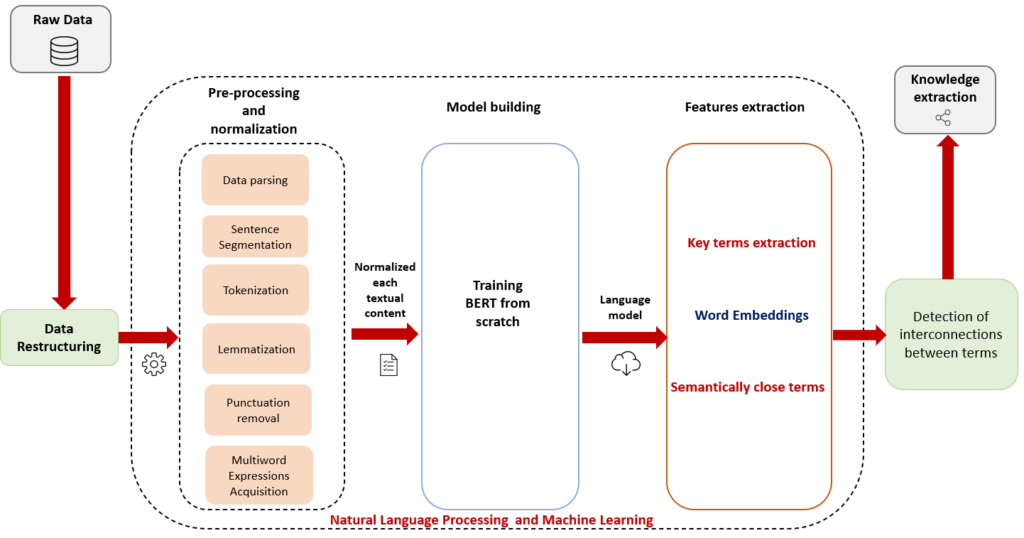
Il existe une série d'options disponibles pour exécuter le modèle BERT avec Pytorch et Tensorflow. Mais pour faciliter la prise en main de notre modèle, nous avons opté pour Bert-as-a-service : une bibliothèque Python qui nous permet de déployer des modèles BERT pré-entraînés dans notre machine locale et de lancer l'inférence.
Nous exécutons un script Python à partir duquel nous utilisons le service BERT pour encoder nos mots dans le word embedding. Pour cela, il nous suffit d'importer la bibliothèque BERT-client et de créer une instance de la classe client. Une fois cela fait, nous pouvons alimenter la liste des mots ou des phrases que nous voulons encoder.
Maintenant que nous avons les vecteurs de chaque mot de notre fichier texte, nous allons utiliser l'implémentation scikit-learn de la similarité en cosinus entre l'incorporation des mots pour aider à déterminer leur degré de parenté.
Voici un aperçu de la distribution de fréquence pour certains termes présents dans notre base éditoriale :

Après avoir obtenu les scores de similarité Cosine entre deux termes donnés, nous construisons un fichier CSV qui contient les 100 termes clés les plus fréquents de notre base éditoriale, leurs 50 mots les plus proches, ainsi que leurs scores de similarité. La figure ci-dessous montre les 100 termes les plus fréquents :

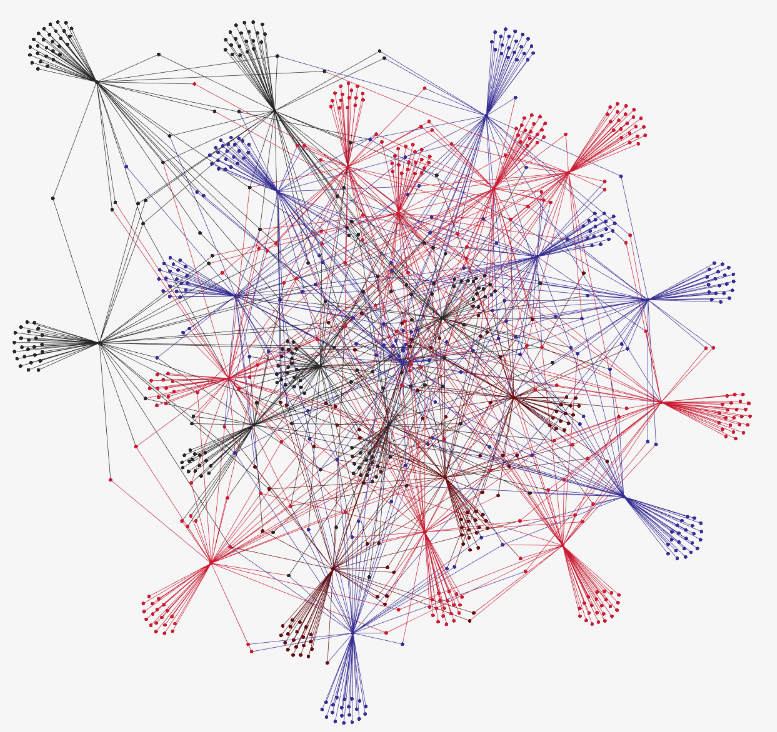
Le fichier est ensuite présenté comme une entrée pour créer le graphe étiqueté suivant représentant les dépendances sémantiques obtenues lors des étapes précédentes :