Chez Berger-Levrault, plusieurs de nos logiciels intègrent en eux-mêmes un moteur de recherche pour faciliter l'accès à l'information. Ces informations peuvent être encodées dans des fichiers ayant des formats divers et variés. Par exemple, des fichiers Word, PDF, CSV, JSON ou même XML. Les moteurs de recherche actuels, tels que Lucene, se concentrent la plupart du temps sur la recherche par mots-clés. Cela limite en fait les recherches approfondies, par exemple pour trouver des liens sémantiques entre les mots exprimés par l'utilisateur et les mots contenus dans la base de données à indexer. Ces liens sémantiques peuvent faire référence à plusieurs relations lexico-sémantiques telles que la synonymie, la spécification, la généralisation ou encore le raffinement sémantique. Cela dit, une recherche approfondie peut améliorer la couverture des réponses retournées et favoriser une recherche intelligente qui va au-delà de la simple recherche de mots-clés. C'est ce que nous allons vous présenter dans cet article, un nouveau composant de moteur de recherche plus intelligent qui se met au service des produits Berger-Levrault. Nous avons appelé ce composant DEESSE : Moteur de recherche sémantique profonde. Pour ce projet de recherche et d'innovation technologique, nous nous sommes intéressés à proposer des méthodes de recherche sémantique de documents tout en considérant les mots et leurs contextes dans une base de données à indexer.
Un premier exercice a déjà été réalisé sur des documents d'actes produits dans "BL.Actes-Office (BLAO)". Avant d'entrer dans les détails de l'approche fondamentale de DEESSE, puisque ce nouveau système a reçu de bons retours, le BLAO utilise déjà notre service DEESSE et nous pouvons nous en féliciter. Cependant, nous aimerions mentionner que pour BLAO, une API java a été utilisée pour communiquer avec Lucene (l'ancien système). Pour des raisons d'interopérabilité, DEESSE est actuellement proposé comme un composant java (JAR) avec une API. Bien que DEESSE ait été développé à l'origine pour BLAO, nous avons envisagé des utilisations futures dans des contextes professionnels différents. Par conséquent, l'API proposée est générique. Enfin, des travaux sont en cours pour proposer une API REST et ainsi offrir DEESSE comme un service d'indexation et de recherche en ligne. Par ailleurs, nous tenons à mentionner que DEESSE indexe les documents plus rapidement que son prédécesseur, l'ancien système Lucene, et utilise beaucoup moins d'espace disque.
Contexte scientifique
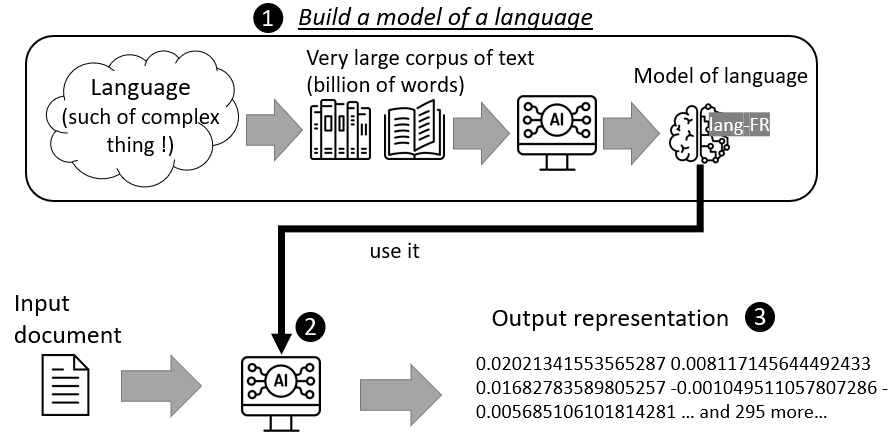
Les machines ne sont pas capables de comprendre le contenu textuel comme un humain, il est donc très difficile de concevoir un programme capable de comprendre toutes les subtilités d'une langue. C'est pourquoi nous parlons de "représentation" et de "modèle". Une représentation est une forme de contenu textuel lisible par une machine. Comme le codage binaire, les représentations sont souvent incompréhensibles pour les humains. Par exemple, dans la figure 1, ❸ est une représentation d'un document. Ces représentations sont calculées par un processus mathématique qui cherche la représentation la plus simplificatrice tout en conservant le maximum de détails ❷. Cependant, pour que cette représentation soit cohérente avec un langage, le processus est paramétré par un modèle décrivant ce langage source ❶.
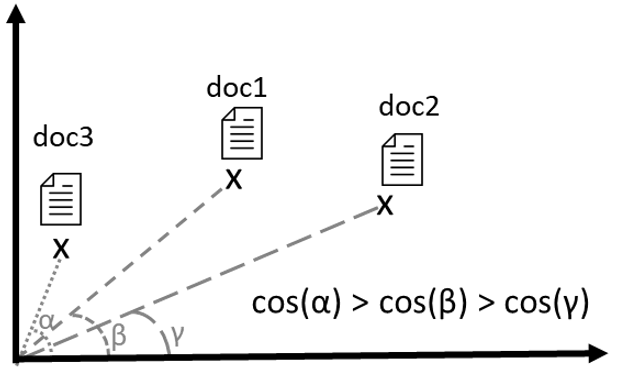
Avec ces représentations et dans un modèle donné, il est possible de comparer les représentations. La figure 2 en donne une illustration. L'une de ces comparaisons est basée sur une métrique appelée cosinus. Une façon de représenter cela est de visualiser les documents à certains moments d'un cycle de vie. n-un espace à plusieurs dimensions. Il suffit de mesurer un angle entre ces documents, le cosinus, pour connaître leur proximité sémantique.
Les techniques utilisées dans ce travail appartiennent à la fois à l'intelligence artificielle (IA), au traitement du langage naturel (NLP) et à la recherche d'information (IR). Ces trois domaines scientifiques et technologiques ont beaucoup en commun : ils traitent tous des textes exprimés en langage naturel. La représentation des documents dans un système de RI et le calcul de la similarité entre ces représentations sont deux questions différentes que nous avons traitées dans ce projet de recherche et développement. Par ailleurs, la force du système DEESSE est de donner à l'utilisateur la possibilité d'exprimer sa requête (query) en langage naturel (comme le fait Google).
L'objectif principal de ce travail est de proposer un modèle de représentation sémantique, d'une part, de la base de documents à indexer et, d'autre part, de la requête exprimée par un utilisateur dont le but est d'interroger sémantiquement une base de données. Pour donner une représentation sémantique qui porte le sens des documents, nous nous sommes basés sur un modèle de langage entraîné sur un très large corpus provenant de la base de données de Domaine .fr que nous détaillons ci-dessous (dans la section suivante). Ce même modèle a été utilisé pour donner une représentation sémantique à la requête. Quant à la mesure de similarité utilisée pour comparer la représentation de la requête aux représentations des documents, nous avons utilisé la très populaire mesure du Cosinus.
Comment cela fonctionne-t-il en profondeur ?
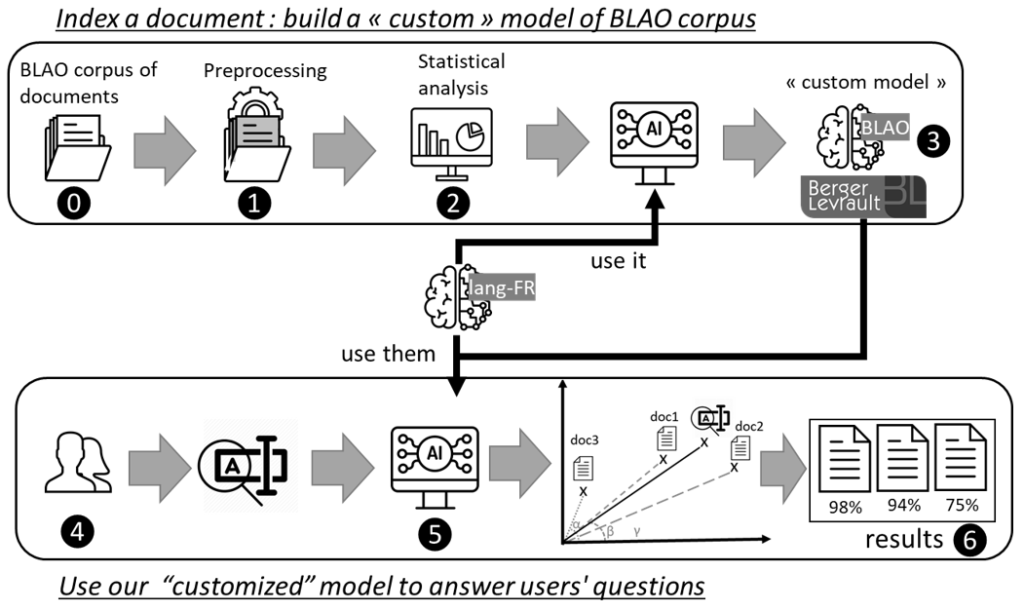
Nous détaillons ici l'architecture de notre approche pour créer des représentations sémantiques ainsi que la manière de retourner les documents les plus proches sémantiquement. La figure 3 décrit les principales étapes. Pour tester notre proposition DEESSE, nous avons travaillé sur un sous-corpus de la base BLAO : il s'agit d'un ensemble de documents de délibération pour la ville de Draguignan ⓿. Ces documents sont d'abord, ❶, prétraités pour trouver les mots porteurs de sens (noms, adjectifs, adverbes et verbes) et les mots d'arrêt (ex : déterminants, prépositions, etc.). Ensuite, ❷ une description statistique est réalisée. Pour chaque mot ayant un sens, son nombre d'occurrences est compté (fréquence des termes - TF) puis sa fréquence inverse des documents (IDF). Avec les résultats de la deuxième étape, le document est indexé ❸, c'est-à-dire qu'une représentation du document est construite. Pour cela, des ressources externes sont utilisées (familles morphologiques et modèle de langue).
Pour la recherche, les utilisateurs expriment leurs requêtes en langage naturel ❹. Comme pour les documents, lors de l'indexation, une représentation de la requête est construite ❺. Elle est ensuite comparée aux représentations des documents précédemment indexés pour déterminer quels documents sont sémantiquement les plus proches ❻.
La figure 4 ci-dessous présente plus en détail les différentes étapes de notre approche.
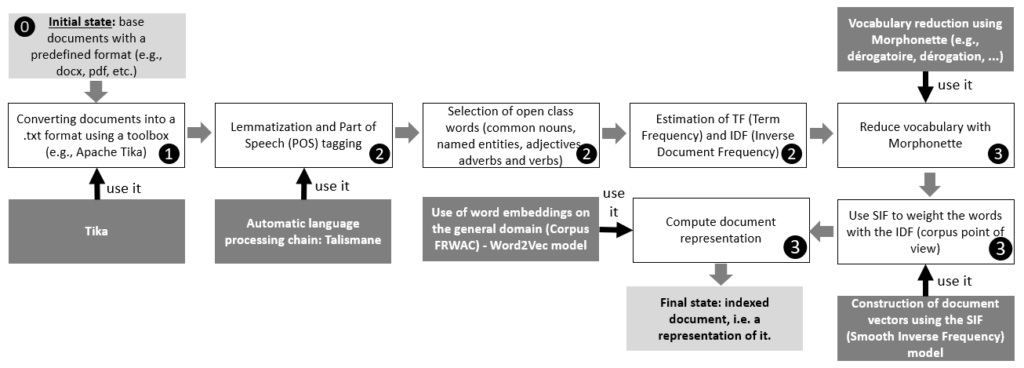
Tout d'abord, les documents ⓿ sont convertis en format texte brut (*.txt) ❶. Ce dernier format de texte est passé à Talismane dont l'idée ici est d'extraire les mots significatifs (mots de classe ouverte) ❷. L'idée par la suite est de mesurer le degré de fréquence en termes d'occurrences (Term Frequency) ainsi que l'inverse document frequency (IDF) de tous les mots des documents à indexer.
Représentation sémantique des documents ❸
Nous décrivons ci-dessous les deux étapes essentielles de la création d'une représentation sémantique des documents :
- Après avoir obtenu les différents lemmes d'un document donné, nous effectuons une substitution lexicale afin de réduire le vocabulaire, c'est-à-dire que nous utilisons l'expression Morphonette ressource (Hathout, 2008) pour remplacer, si possible, les mots d'un document par les mots les plus fréquents du corpus et appartenant à la même famille morphologique. Par exemple, dérogatoire peut être remplacé par dérogation si elle est plus fréquente que lui.
- Nous construisons des représentations vectorielles continues des documents à partir d'une liste de mots. Pour cela, nous utilisons l'algorithme Smooth Inverse Frequency (SIF) proposé par Arora et al. (2017). Le principe de cet algorithme consiste à prendre la moyenne pondérée de l'incorporation des mots dans un texte afin de ne pas donner trop de poids aux mots qui ne sont pas pertinents du point de vue sémantique. Cette étape consiste à considérer l'IDF associé à chaque mot du corpus.
Pour générer des vecteurs continus pour les documents, nous nous sommes basés sur un modèle de langage permettant de fournir des vecteurs de mots (intégration des mots). Ces vecteurs sont du type Word2Vec (Mikolov et al., 2013) avec une valeur de CBOW (Continuous Bag of Words) type d'architecture. Le site Word2Vec a été formé sur le modèle FRWAC corpus (Fauconnier, 2015).
FRWAC est un corpus français du domaine .fr, il contient près de deux milliards de mots. Fauconnier (2015) a déjà proposé un modèle de langage entraîné sur ce corpus, nous l'avons donc utilisé. Pour le passage de la représentation des mots à la représentation des documents, nous avons choisi d'utiliser un vecteur centroïde pondéré tel que décrit par Arora et al. (2017). Ce vecteur est défini à partir des vecteurs de tous les mots d'un document donné. De plus, la représentation sémantique de la requête est construite de la même manière que la représentation des documents.
Les documents sont indexés principalement par leur représentation sémantique, la requête aussi. Cependant, le modèle de langage ayant été entraîné sur un corpus différent de la base à traiter, le modèle utilisé peut ne pas offrir une représentation pour les mots exprimés dans la requête. Les raisons sont multiples : on peut traiter des codes, des termes trop techniques, ou encore des dates, par exemple. La figure ci-dessous décrit nos choix pour faire face à ce problème, c'est-à-dire les types de représentation des documents utilisés pour interroger la base indexée.
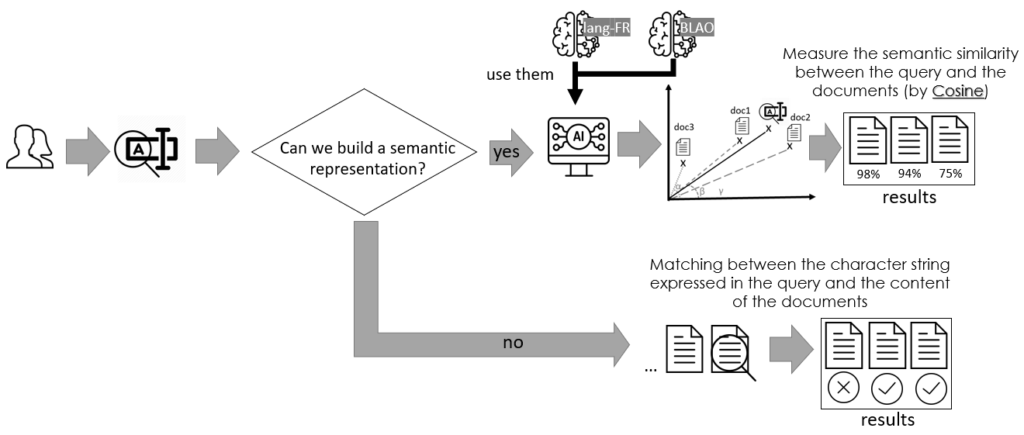
Ainsi, pour améliorer les résultats de recherche, et si l'utilisation d'enchâssements lexicaux issus du Corpus FRWAC ne permet pas de retourner une représentation sémantique pour la requête exprimée par un utilisateur, nous appliquons automatiquement une recherche exacte (sur des textes bruts). Cette approche secondaire consiste à trouver exactement la chaîne de caractères de la requête dans les documents de notre corpus.
Type de requête
Nous proposons deux façons d'interroger une base de données :
- En utilisant uniquement les mots de la requête originale
- En considérant non seulement les mots de la requête originale mais aussi les trois mots les plus proches sémantiquement de chaque mot de la requête originale. Cette extension de la liste de mots de la requête est basée sur l'utilisation du modèle de langage Word2Vec
La figure ci-dessous décrit avec un exemple comment les mots de la requête originale sont utilisés.
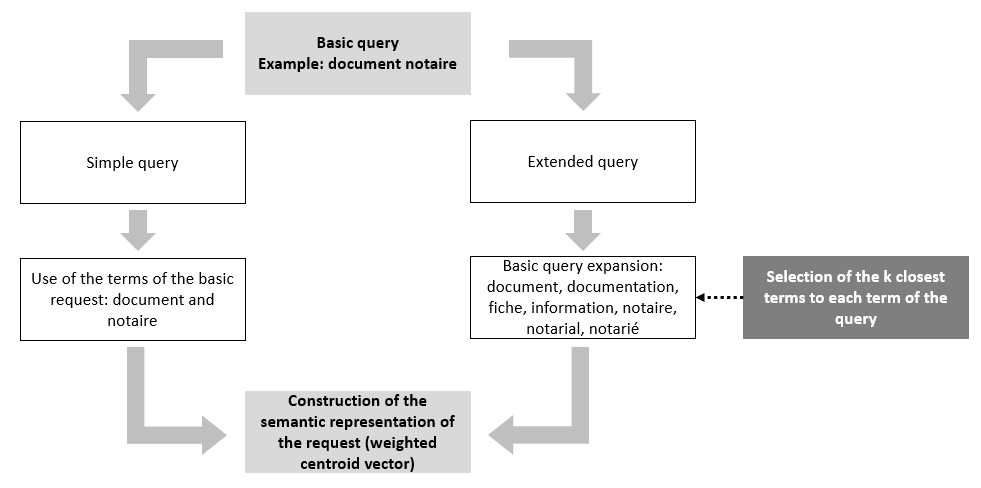
Autre exemple, la requête "Entreprise travaux publics"est exprimé différemment entre les deux types de requêtes. Après avoir traité le texte de la requête, le premier type retourne un sac de mots "entreprise, public ettravail "tandis que la seconde renvoie "entreprise, public, travail, chantier, collectivité, pme, pme-pmi, privé, professionnel, salarié et territorial". Avec une telle combinaison de mots, il est parfaitement logique que le résultat de la recherche sémantique des documents ne soit pas le même lorsqu'on applique les deux types de requête.
Nos expériences et résultats: Plus rapide, plus petit, plus efficace
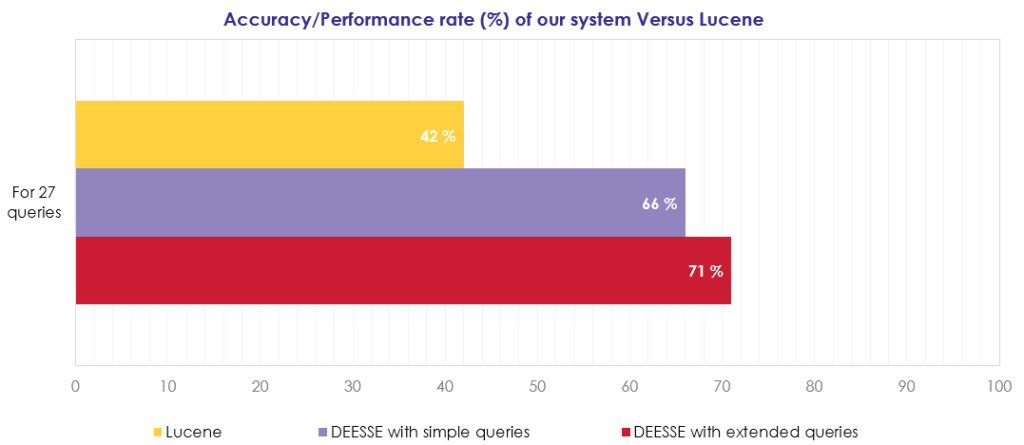
Nous présentons maintenant une évaluation de notre approche en comparaison avec un système qui repose sur l'indexation par mots-clés : le système Lucene. Pour réaliser cette tâche, nous avons pris contact avec un expert du produit BLAO. Cet expert nous a fourni un ensemble de 27 requêtes choisies pour couvrir les formes possibles que peuvent avoir les requêtes exprimées par les utilisateurs (chaînes de caractères, codes, dates, etc.). Une comparaison avec le système Lucene a été mise en place. Il est à noter que Lucene est le système qui a été utilisé principalement par BL. Actes-Office, ce n'est plus le cas aujourd'hui puisque DEESSE l'a remplacé. La figure ci-dessous montre les différentes requêtes prises pour le test.

L'expert a entrepris d'annoter les résultats, c'est-à-dire d'annoter les documents qui sont pertinents pour lui et qui devraient apparaître en première place par le moteur de recherche. La figure ci-dessous montre l'évaluation des résultats obtenus. Nos résultats ont donc montré un taux de performance de 71% pour DEESSE avec des requêtes étendues et 66% pour DEESSE avec des requêtes simples contre 42% pour Lucene. Nous avons donc obtenu +5% avec des requêtes étendues. De plus, sur 8 requêtes, nos systèmes ont retourné de bons résultats contre rien pour Lucene : nous en avons trouvé dans les requêtes suivantes : "Entreprise travaux publics“, “Radiotéléphonique “, “2252129.78“, “18 francs" ou "18“.
Nous avons mené une étude comparative entre l'ancien moteur de recherche, Lucene, et notre moteur DEESSE. Le tableau suivant montre nos résultats pour un corpus réel de 13 500 documents (taille totale du corpus : 405 MB - taille moyenne des documents 30kb).
| Métriques | Moteur hérité (Lucene) | Moteur DEESSE | Gain |
|---|---|---|---|
| Temps total d'indexation (heure) | 184,5 heures | 18,25 heures | 166,25 heures gagné pour le temps d'indexation DEESSE exige 90% moins temps pour l'indexation. |
| Vitesse d'indexation (docs/heure) | 91 docs/heure | 740 docs/heure | 649 docs/heure |
| Vitesse d'indexation (Mo/heure) | 2,73 mb/heure | 22,2 mb/heure | 19,5 mb/heure |
| Taille des index (MB) | 576 000 mb | 260 mb (tous les index) 138 mb (uniquement les index sémantiques) | 575 740 mb Utilisation de DEESSE seulement 0,06% de l'espace disque requis par Lucene. |
| Performance [1] (<0 : pire ; 1 : meilleur) | – 1 397 | 0,35 (tous les indices) 0,66 (uniquement indices sémantiques) |
Les résultats sont impressionnants et démontrent remarquablement bien que DEESSE n'a rien à envier aux moteurs existants, même dans un contexte industriel ! Nous savons que 98% du temps d'indexation est dû à l'analyse morpho-syntaxique. Nous envisageons de remplacer l'analyseur actuel par un analyseur plus rapide, tel que TreeTagger.[2]. On s'attend alors à un gain très important (~50%) de la vitesse d'indexation.
Les mesures de performance étaient si impressionnantes que nous avons dû vérifier nos résultats à plusieurs reprises.
[1] Performance_Indexation = 1 - (Taille des fichiers indexés/taille du corpus à indexer)
[2] https://www.cis.uni-muenchen.de/~schmid/tools/TreeTagger/
Conclusion et travaux futurs
Dans cet article, nous avons présenté DEESSE : un modèle de recherche sémantique de documents. Ce modèle a été testé sur une des bases de données de produits BLAO. DEESSE est basé sur l'utilisation de techniques d'IA (intégration des mots), le traitement du langage naturel (Talismane) et les méthodes de recherche d'information (comparaison des représentations sémantiques "documents"). contre requête" dans le même espace vectoriel). Nous avons vu que l'utilisation des encastrements de mots peut améliorer la recherche de documents au lieu d'une simple indexation par mots-clés. Nous présentons ci-dessous les avantages de l'utilisation de DEESSE :

Par ailleurs, il faut noter que nous avons mis deux démonstrations du système DEESSE à la disposition de tous nos collaborateurs de Berger-Levrault : la première manifestation reflète les résultats de la performance obtenue avec BLAO ; le second fait référence à la base de données BL BOT. Cela nous permet déjà de penser à la deuxième version de BL BOT.
Pour les travaux futurs, nous aimerions réaliser ce qui suit :
- Une API REST pour DEESSE afin que le système puisse être utilisé sans restrictions technologiques.
- Prise en charge de plusieurs formats de documents (par exemple, XML, JSON, CSV, etc.)
- Pour la recherche scientifique, il serait intéressant d'étendre DEESSE pour apprendre non seulement à partir du contenu des documents mais aussi en considérant les mots exprimés dans la requête de l'utilisateur. Il s'agit de considérer ce que l'utilisateur souhaite avoir le plus souvent et ce de manière sémantique et intelligente sans sortir des contextes proposés dans la base de données.
- Testez DEESSE sur d'autres bases de données de produits comme BL.API, Legibases, Carl, Commune-IT, et bien d'autres encore.
Références
| Apache Tika | https://tika.apache.org/ |
| Talismane | URIELI Assaf (2013). " Analyse syntaxique robuste du français : conciliation des méthodes statistiques et des connaissances linguistiques dans la boîte à outils Talismane ". Thèse de doctorat. Université de Toulouse II le Mirail, France (http://redac.univ-tlse2.fr/applications/talismane.html). |
| Morphonette | HATHOUT Nabil (2008). Acquisition de la structure morphologique du lexique basée sur la similarité lexicale et l'analogie formelle. Proceedings of the 3rd Textgraphs Workshop on Graph-Based Algorithms for Natural Language Processing, p. 1-8. DOI : 10.3115/1627328.1627329 (http://redac.univ-tlse2.fr/lexiques/morphonette.html). |
| FRWAC | BARONI Marco, BERNARDINI Silvia, FERRARESI Adriano et ZANCHETTA Eros (2009). "The WaCky wide web : a collection of very large linguistically processed web-crawled corpora". Dans Language Resources and Evaluation, p. 209-226. |
| Word2Ve | MIKOLOV Tomáš, CHEN Kai, CORRADO Greg et DEAN Jeffrey (2013). " Estimation efficace des représentations de mots dans l'espace vectoriel ". Actes de la Conférence internationale sur l'apprentissage des représentations, p. 1-12 (https://code.google.com/archive/p/word2vec/). |
| Fréquence inverse lisse (SIF) | ARORA Sanjeev, LIANG Yingyu et MA Tengyu (2017). Une base de référence simple mais difficile à atteindre pour les emboîtages de phrases. In International Conference on Learning Representations (ICLR) (https://github.com/KHN190/sif-java). |
| Modèle de langue standard | FAUCONNIER, Jean-Philippe (2015). Embeddings de mots français (http://fauconnier.githubio/#data). |
| Lucene | https://lucene.apache.org/ |
| TreeTagger | SCHMID Helmut (1994). "Le marquage probabiliste de la parole à l'aide d'arbres de décision ". Actes de la conférence internationale sur les nouvelles méthodes de traitement du langage.Manchester, Royaume-Uni. |