L'identification des relations dans les documents fait partie d'un projet sur les graphes de connaissances.
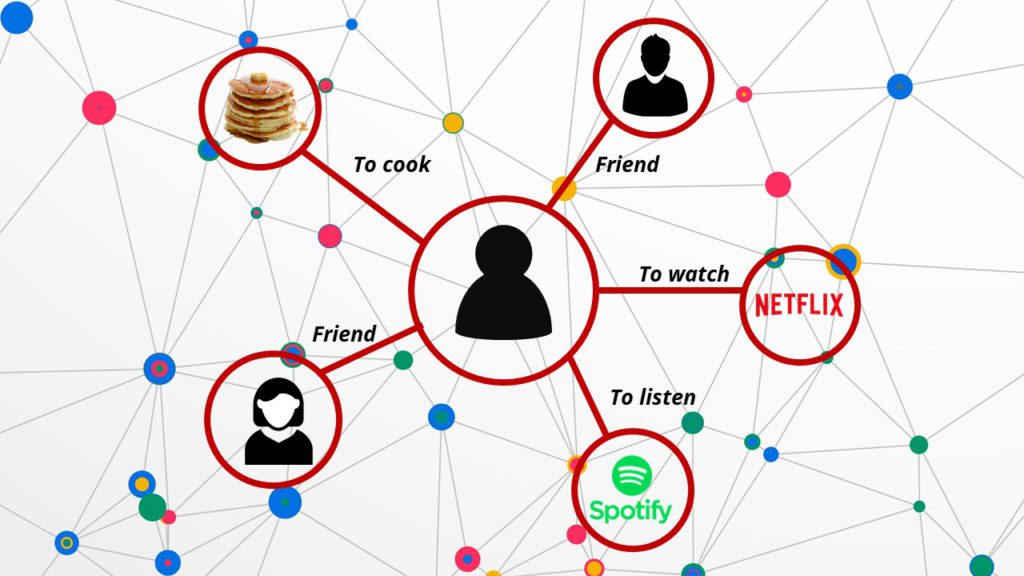
Un graphe de connaissances est un moyen de présenter graphiquement la relation sémantique entre des sujets tels que des personnes, des lieux, des organisations, etc. qui permet de montrer synthétiquement un ensemble de connaissances. Par exemple, la figure 1 présente un graphe de connaissances de médias sociaux, nous pouvons y trouver quelques informations sur la personne concernée : son amitié, ses hobbies et ses goûts.
L'objectif principal de ce projet est d'apprendre de manière semi-automatique des graphes de connaissances à partir de textes selon le domaine de spécialité. En effet, les textes que nous utilisons dans ce projet proviennent de huit domaines du secteur public qui sont : Etat civil et cimetière, Election, Ordre public, Urbanisme, Comptabilité et finances locales, Ressources humaines locales, Justice et Santé. Ces textes édités par Berger-Levrault sont issus de 172 livres et 12 838 articles en ligne d'expertise judiciaire et pratique.
Pour commencer, un spécialiste du domaine analyse un document ou un article en parcourant chaque paragraphe et choisit de l'annoter ou non avec un ou plusieurs termes. Au final, il y a eu 52 476 annotations sur les textes des livres et 8 014 sur les articles qui peuvent être des mots multiples ou un seul terme.
A partir de ces textes, nous voulons obtenir plusieurs graphes de connaissances en fonction du domaine comme dans la figure ci-dessous :
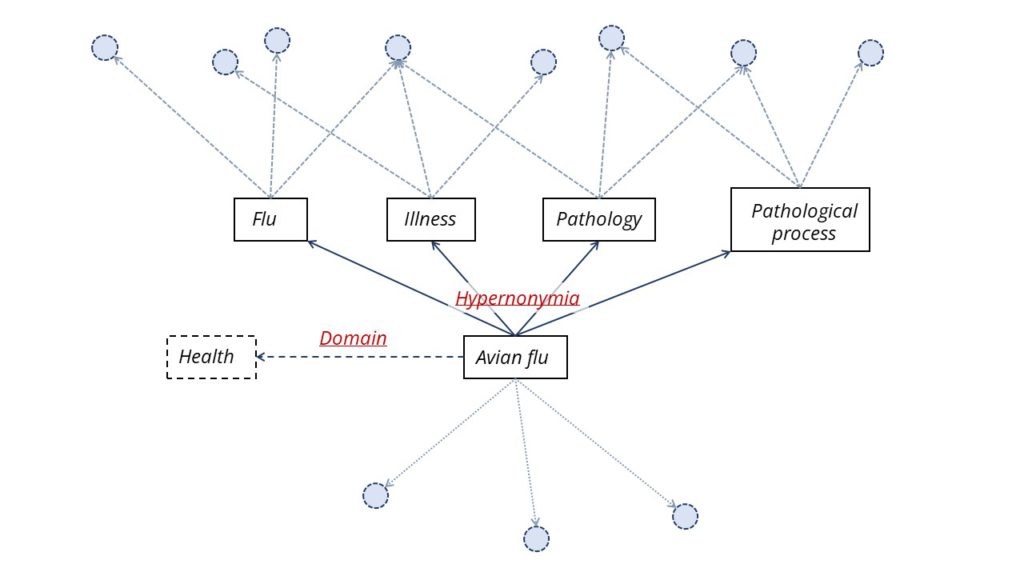
Comme dans notre graphique de médias sociaux (figure 1), nous pouvons trouver des liens entre les mots de spécialité. C'est ce que nous cherchons à faire. À partir de toutes les annotations, nous voulons identifier les relations sémantiques pour les mettre en évidence dans notre graphe de connaissances.
Explication du processus
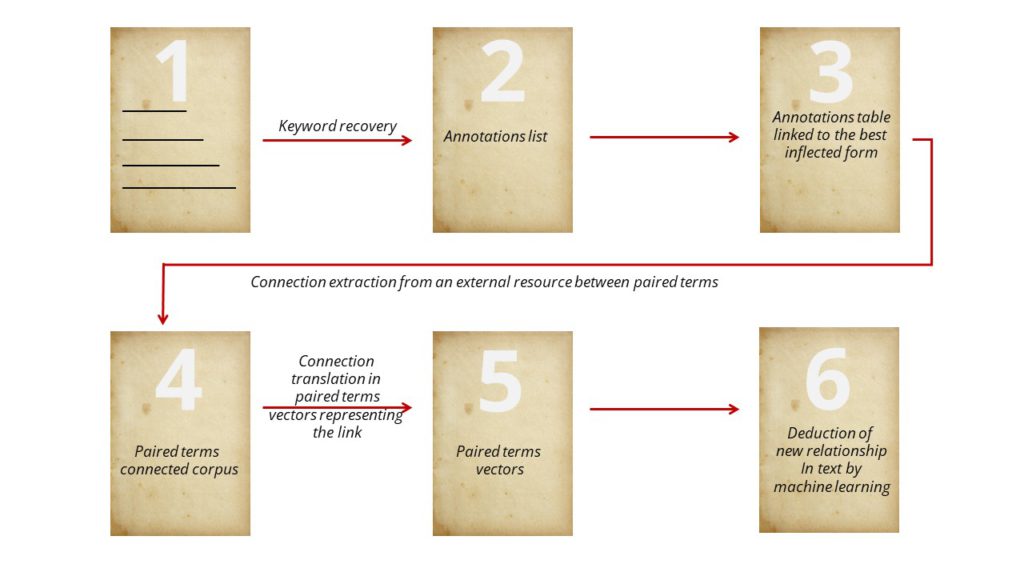
La première étape consiste à récupérer toutes les annotations des experts à partir des textes (1). Ces annotations sont à commande manuelle et les experts n'ont pas de lexique référentiel, alors ils peuvent ne pas utiliser le même terme (2). Les mots clés sont décrits avec plusieurs formes fléchies et parfois avec des informations supplémentaires non pertinentes comme le déterminant ("a", "le" par exemple). Ainsi, nous traitons toutes les formes infléchies pour obtenir une liste unique de mots clés (3).
Avec ces mots clés uniques comme base, nous allons extraire des ressources externes des connexions sémantiques. Pour l'instant, nous nous concentrons sur quatre scénarios : l'antonymie, des termes ayant un sens opposé ; la synonymie, des termes différents ayant le même sens ; l'hypernonymie, représentant des termes qui peuvent être associés aux génériques d'une cible donnée, par exemple, "grippe aviaire" a pour terme générique : "grippe", "maladie", "pathologie" et l'hyponymie qui associe les termes à une cible spécifique donnée. Par exemple, "engagement" a pour terme spécifique "mariage", "engagement à long terme", "engagement social"...
Avec l'apprentissage profond, nous construisons des vecteurs de termes contextuels de nos textes pour déduire les paires de termes présentant un lien donné (antonymie, synonymie, hypernonymie et hyponymie) avec des opérations arithmétiques simples. Ces vecteurs (5) constituent un jeu d'entraînement pour l'apprentissage automatique des relations. À partir de ces mots appariés, nous pouvons déduire de nouvelles connexions entre les mots du texte qui ne sont pas encore connues.
L'identification des connexions est une étape cruciale dans l'automatisation de la construction de graphes de connaissances (également appelée base ontologique) multi-domaines. Berger-Levrault développe et maintient des logiciels de grande taille avec un engagement envers l'utilisateur final, ainsi, la société veut améliorer ses performances dans la représentation des connaissances de sa base d'édition à travers des ressources ontologiques et améliorer les performances de certains produits en utilisant ces connaissances.
Perspectives d'avenir
Notre époque est de plus en plus influencée par la prédominance du volume des big data. Ces données cachent généralement une grande intelligence humaine. Ces connaissances permettraient à nos systèmes d'information d'être plus performants dans le traitement et l'interprétation des données structurées ou non structurées.
Par exemple, le processus de recherche de documents pertinents ou le regroupement de documents pour en déduire des thématiques ne sont pas toujours faciles, surtout lorsque les documents proviennent d'un secteur spécifique. De même, la génération automatique de texte pour apprendre à un chatbot ou à un voicebot comment répondre à des questions rencontre la même difficulté : il manque une représentation précise des connaissances de chaque domaine de spécialité potentiel qui pourrait être utilisé. Enfin, la plupart des systèmes de recherche et d'extraction d'informations se basent sur une ou plusieurs bases de connaissances externes, mais ont des difficultés à développer et à maintenir des ressources spécifiques dans chaque domaine.
Pour obtenir de bons résultats en matière d'identification des connexions, nous avons besoin d'un grand nombre de données, comme c'est le cas pour 172 livres avec 52 476 annotations et 12 838 articles avec 8 014 annotations. Bien que les méthodologies d'apprentissage automatique puissent présenter des difficultés. En effet, certains exemples peuvent être faiblement représentés dans les textes. Comment s'assurer que notre modèle détectera tous les liens intéressants dans ces textes ? Nous envisageons de mettre en place d'autres méthodes pour identifier les relations faiblement représentées dans les textes avec des méthodologies symboliques. Nous voulons les détecter en trouvant des modèles dans les textes liés. Par exemple, dans la phrase "le chat est une sorte de félin"nous pouvons identifier le modèle "est une sorte de". Il permet de lier "chat" et "félin" comme le second générique du premier. Nous voulons donc adapter ce type de modèle à notre corpus.