
Lorsque les équipements de nos clients ont besoin d'une intervention de maintenance pour quelque raison que ce soit, ils peuvent en faire la demande via Carl Source, notre logiciel de GMAO.
Ces interventions demandes de renseignements sera reçu par le service technique qui l'analysera, le préqualifiera et l'associer à un type d'intervention avant de la programmer. Certaines interventions sont plus urgentes que d'autres et certaines nécessitent une spécificité technique ou une compétence particulière. Il peut facilement devenir un casse-tête. Par conséquent, si le nombre de jours demandes de renseignements deviennent très importants, le responsable peut rapidement être dépassé par son travail.
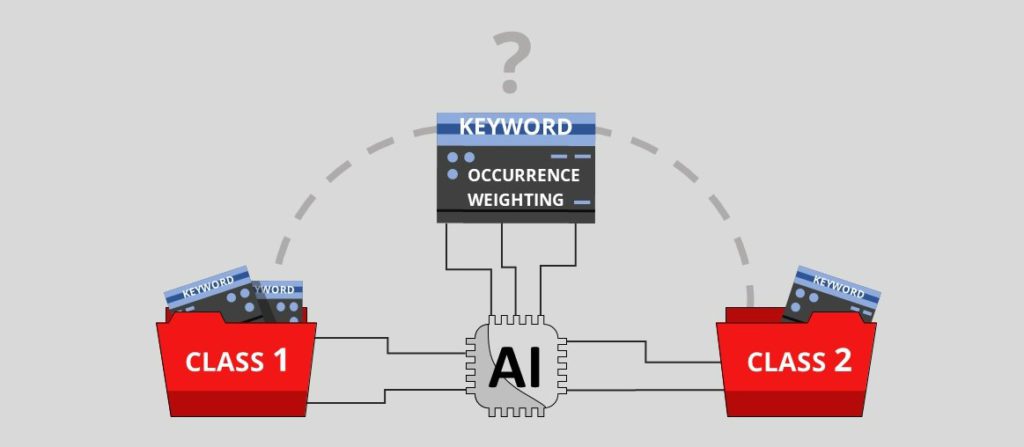
Pour faciliter leur travail et rendre plus efficace leur intervention sur le calendrier, nous avons travaillé sur un algorithme pour analyser et classer l'intervention demandes de renseignements et fournir des informations d'aide à la personne chargée de programmer l'intervention de maintenance.
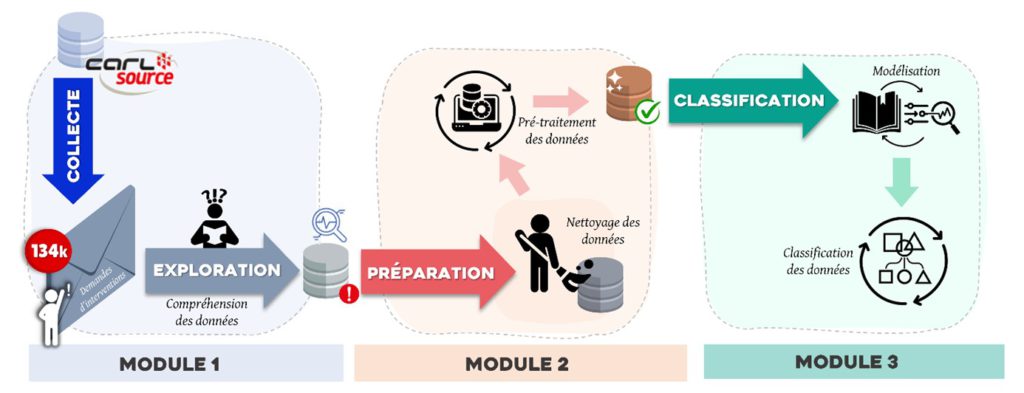
Notre solution est composée de trois unités principales. La première unité est dédiée à collecte et exploitation des donnéesla deuxième unité extraire des connaissances et transformer les données brutes recueillies en données utilespuis dans la dernière unité, les données transformées seront classés par type d'intervention (dans certains cas, l'algorithme peut suggérer différentes types d'intervention). Avec ces informations, la personne en charge peut décider pour associer la requête à une intervention auprès du bon technicien.
Dans ce projet, il est vraiment important de savoir ce qu'est la maintenance. La maintenance peut être nécessaire dans différents secteurs d'activité comme l'industrie, l'énergie, le transport, etc. et pour différentes raisons. Il peut s'agir d'une maintenance corrective lorsqu'une défaillance se produit sur un équipement, d'une maintenance préventive pour éviter une défaillance future due au temps, par exemple, ou d'une maintenance prédictive lorsque l'activité de la machine est mesurée par la technologie IoT et qu'elle peut prévenir sa propre panne.
Compréhension des données
Depuis notre réseau privé, nous avons recueilli l'intervention demandes de renseignements données provenant de 22 clients. Il est important de savoir que l'intervention demandes de renseignements Les formulaires peuvent être personnalisés par chaque client, en fonction de ses besoins. C'est pourquoi nous devons sélectionner les exigences les plus indicatives et les plus communes.
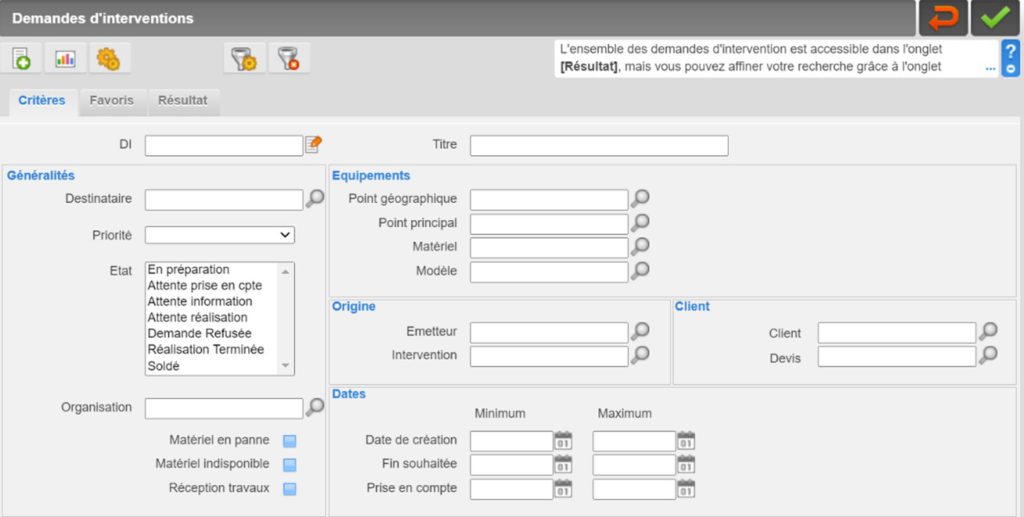
Une fois exportées, les données ressemblent à la figure 3 présentée ci-dessous.

Pour uniformiser ces données, nous sélectionnons les informations les plus pertinentes et les plus communes pour classer les requêtes d'intervention. Les informations retenues sont : le nom des clients, la requête d'intervention ID, le degré de priorité, le statut actuel de la requête, la date de création, l'équipement concerné, la requête le titre et sa description.
En parcourant ces données brutes, nous avons remarqué qu'elles contenaient du bruit. Nous appelons bruit les différences linguistiques observées comme les fautes d'orthographe, les mots dans une autre langue, les acronymes, les noms de marque, etc. C'est pourquoi nous devons préparer les données avant de les traiter.
Préparation des données
Pour sélectionner les bonnes informations à partir des données collectées, nous les classons en deux groupes.
A premier groupe avec des caractéristiques variables: le nom du client, la requête le code, son statut, le degré de priorité, la date et l'ID de l'équipement concerné. A deuxième groupe pour les variables informatives qui sont dans notre cas : le titre, la description de la requête et le nom de l'équipement.
Maintenant, nous devons préparer les données à leur traitement. Pour ce faire, nous devons passer par les étapes de "nettoyage" suivantes :
Tokenization: Cette première étape est le point d'entrée de tout processus NLP. Elle consiste à transformer la requête d'intervention en une série de mots individuels appelés "tokens".
Suppression de la ponctuation, des symboles, des espaces supplémentaires et des chiffres.: Ces éléments ne fournissent pas d'informations utiles, mais ils peuvent perturber le traitement.
Suppression des mots d'arrêt: Les mots d'arrêt, également appelés mots vides, sont des termes fréquemment utilisés qui n'ajoutent pas d'informations précieuses à une phrase. Nous les supprimons pour réduire le vocabulaire du modèle.
Correction orthographique: Nous avons besoin de mots correctement orthographiés pour les interpréter. Pour corriger les fautes d'orthographe, nous utilisons Pyenchant qui suggèrent des corrections pour les mots mal orthographiés.
Détection et suppression des noms appropriés
Détection et suppression des codes clients internes et test de requête d'intervention
Reconnaissance du nom de l'entitécomme les villes, les lieux, les marques, etc.
Identification des acronymes
Lemmatisation pour identifier le même expression avec différentes formes (forme plurielle, forme conjuguée, etc.)
Gestion des synonymes pour réduire le vocabulaire du modèle.
Détection et traitement des N-grammes: Les N-grams sont des associations de mots qui apportent une précision importante pour contextualiser une requête d'intervention. Par exemple, le terme "fuite d'eau" est plus précis que "fuite" seul pour déterminer le type d'intervention. Pour les détecter, nous utilisons des bibliothèques établies.
Modélisation : Classification par dominance de vocabulaire
Une fois les données préparées, nous pouvons classer les requêtes d'intervention en analysant le vocabulaire utilisé. Dans l'analyse, nous recherchons des mots clés distinctifs pour catégoriser l'intervention.. Ces mots clés sont dans lexiques définis à l'avance et décrire chaque type d'intervention.
Dans ce projet, nous avons huit types d'interventions :
- Plomberie: Ce type d'intervention nécessite un plombier ayant des connaissances spécifiques et doit être effectué rapidement dans la plupart des cas.
- Entretien de la propriété: Il faut un technicien polyvalent pour faire tout type d'entretien général et ce n'est pas urgent en général.
- Électricité: Ces interventions ne peuvent être réalisées que par un électricien et peuvent nécessiter des compétences spécifiques.
- Informatique et téléphonie: Généralement, elles sont sous-traitées ou gérées par une équipe spécifique.
- Sécurité incendie: Généralement en sous-traitance avec un lien direct avec un manager
- Entretien des machines: Elle nécessite l'intervention d'un technicien spécialisé. Le plus difficile dans ce type d'intervention est de déterminer l'urgence de l'intervention et l'importance de l'équipement concerné.
- Administrative: Il peut s'agir de rapports, de commandes, de processus de vente et d'achat...
- Non classé: Quand il n'y a pas assez d'informations dans la requête d'intervention, les mots utilisés ne sont pas dans les lexiques, il y a des compétences entre les différents types d'intervention, etc.
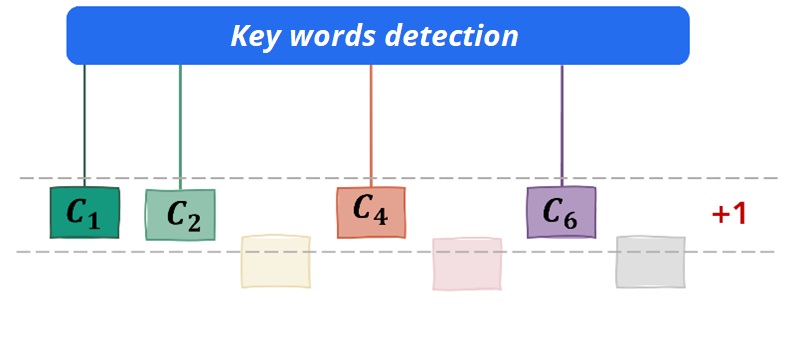
A partir de ces informations, la recherche par algorithme des mots clés correspondants dans la requête d'intervention et les lexiques. Ensuite, nous appliquons une notation par le biais de deux méthodes.
La première méthode est calcul des événementspour chaque mot clé correspondant, il donne un point au type d'intervention concerné et celui qui a le plus grand score sera proposé à l'utilisateur.
Nous utilisons également un méthode de pondérationNous attribuons un coefficient d'importance à certains mots et lorsqu'ils apparaissent dans une requête d'intervention, ils sont reconnus par l'algorithme comme plus importants que les autres mots. Un même mot peut apparaître dans différents lexiques avec un coefficient d'importance différent.
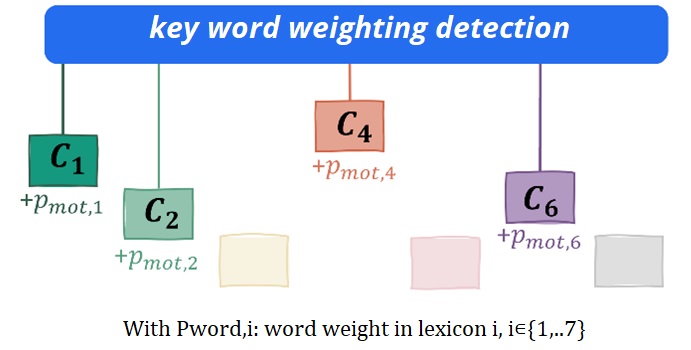
En combinant ces deux méthodes, l'algorithme de classification est plus précis.
Les lexiques sont construits manuellement, mais ils sont enrichis et leur score de pondération est ajusté par l'algorithme grâce à un processus d'apprentissage automatique basé sur la fréquence des mots dans une classe, leur spécificité et leur score de pondération original.. Il est important d'avoir des lexiques bien renseignés et les bonnes caractéristiques de score pour obtenir une classification précise.
Évaluation de la classification
Après avoir collecté, compris et préparé les données des requêtes d'intervention, nous avons pu les classer grâce à nos lexiques bien informés et aux méthodes d'occurrence et de pondération. Une dernière étape, mais non la moindre, est l'évaluation, dans laquelle nous évaluons les résultats obtenus par nos méthodes.
La matrice de confusion est un outil de mesure célèbre dans le processus d'apprentissage automatique. Elle reprend les résultats de la classification comme vous pouvez l'observer dans la Figure 6.

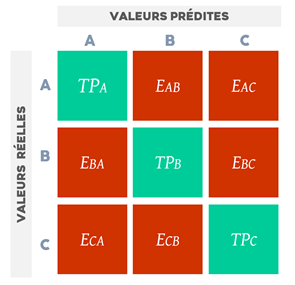
Avec cette matrice, nous pouvons évaluer le précision: le nombre de requêtes bien classées par rapport au nombre total de requêtes ; précision: le nombre de requêtes bien classées ou mal classées dans une même classe ; rappel ou sensibilité: le nombre de requêtes classées correctement dans une catégorie par rapport au nombre de requêtes appartenant à cette catégorie ; F-score: moyenne harmonique de la précision et du rappel.
Phase d'apprentissage
Pour évaluer la performance d'apprentissage de notre solution, nous avons collecté 999 requêtes d'intervention de manière aléatoire. Nous les avons catégorisées manuellement pour comparer notre catégorisation au résultat généré.
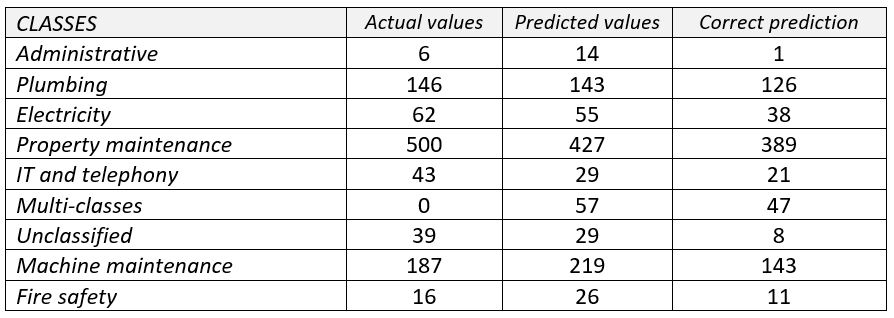
Le résultat montre une précision de 78,2% de notre modèle. Dans celui-ci, il y avait 5,7% de requêtes d'intervention multi-classes avec 82,46% d'entre elles correctement catégorisées. Nous avons remarqué un taux de précision vraiment faible dans la classe administrative en raison des données d'apprentissage déséquilibrées qui la rendent générique. Cependant, les autres catégories obtiennent d'assez bons résultats. Le résultat de la précision est de 60,6% et celui du rappel est de 61,85%.
Phase de test
Pour évaluer sa capacité de généralisation, nous avons collecté 922 requêtes d'intervention de cinq nouveaux clients et les avons classées manuellement pour les comparer à la génération.
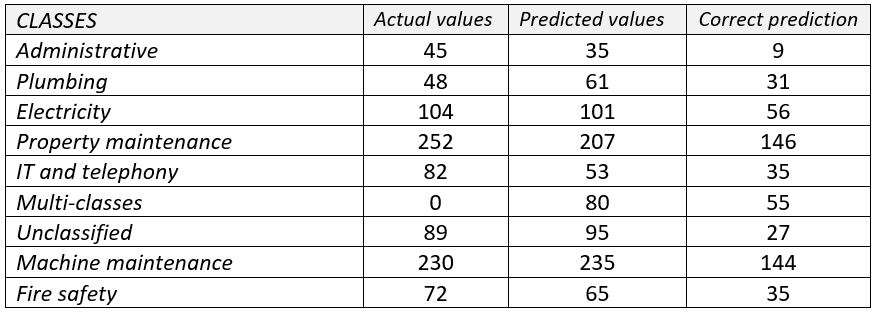
Le taux de précision est descendu à 58,3% lors de la phase de test, avec un résultat de précision de 52% et un résultat de rappel de 54,8%. Le modèle a une meilleure supervision sur certains clients que sur d'autres, ce qui peut s'expliquer par des différences de secteur d'activité. Ces résultats nous permettent de constater l'incapacité de notre modèle à détecter et intégrer d'autres classes que celles déjà constituées.
Avec ce projet, nous proposons un outil d'aide à la décision pour aider l'équipe technique sur le traitement des requêtes d'intervention. Notre algorithme permet l'intervention requête préqualification automatique proposer ensuite une classification au gestionnaire qui peut l'associer à une intervention réelle. Elle l'aide dans la gestion du flux de requêtes et l'optimisation du calendrier. Notre solution donne de bons résultats pour des requêtes claires avec des termes spécifiques grâce à la méthode des occurrences, mais elle peut être améliorée en travaillant sur les lexiques et en établissant un bon équilibre entre les glossaires pour ne pas les confondre.



