

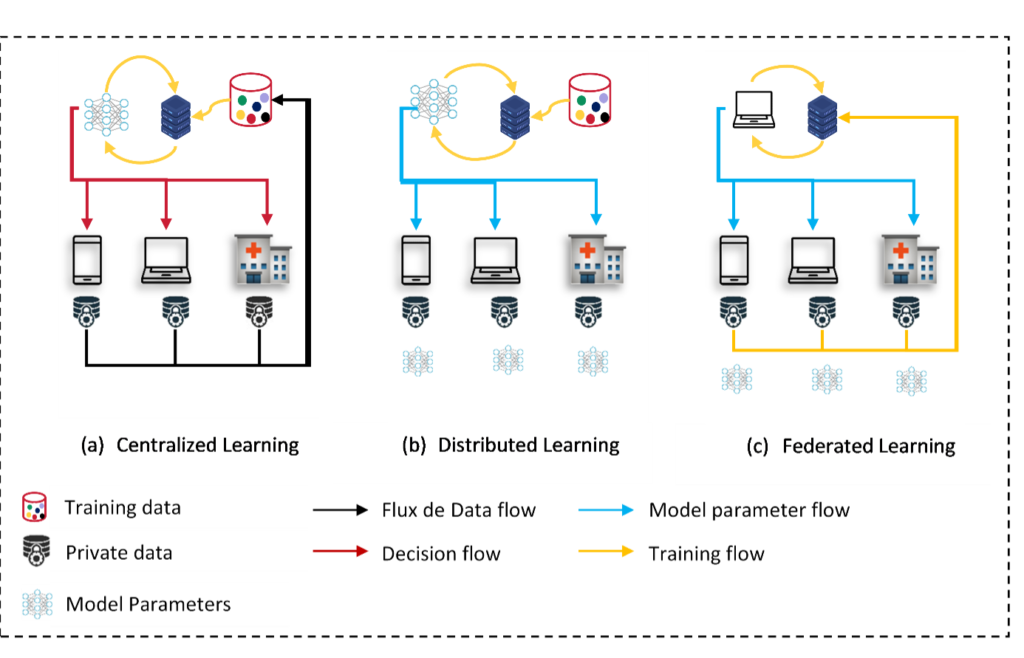
Nowadays, a massive amount of data is generated by devices such as smartphones and connected objects (IoT). This data is used to train high-performance machine learning (ML) models, making artificial intelligence (AI) present in our daily lives. Data is generally sent to the cloud, where it is stored, processed, and used to train models in a centralized manner. Centralized AI is the most common architecture. However, the repetitive transfers of huge volumes of data generate a high cost in terms of network communication and give rise to many questions about data privacy and security. From a security point of view, sensitive data is highly exposed to attacks and cyber-risks. Among the most serious violations recorded in the 21st century, Equifax with 147.9 million customers affected in 2017, Marriott with 500 million customers affected in 2018, and eBay with 145 million users affected in 2014. In this context, a new European Union regulation, called the “General Data Protection Regulation“, has been applied. The goal is to secure and protect personal data by defining rules and limitations, which complicates the process of training and adapting centralized machine learning models.

Distributed learning approach has been proposed to handle this problem. It consists of bringing the code back to the data. Each edge-device (cell phone, IoT device, etc.) trains its model locally without benefiting from the data and experience of others. This approach guarantees users privacy but models are far from being efficient mainly due to the lack of data in the device, the limited storage, and computing capacity.
Federated Learning aims at solving privacy issues caused by the centralization of data in large databases. When you apply a federated learning approach, your data stays on your devices (or server), it’s the AI which moves (and learn) from one database to another rather than learning on one single large database.
Google published (in 2016) a new learning architecture called Federated Learning to address the limitations of the existing centralized and distributed approaches. So, what is federated learning?
Tell me…what is Federated Learning?
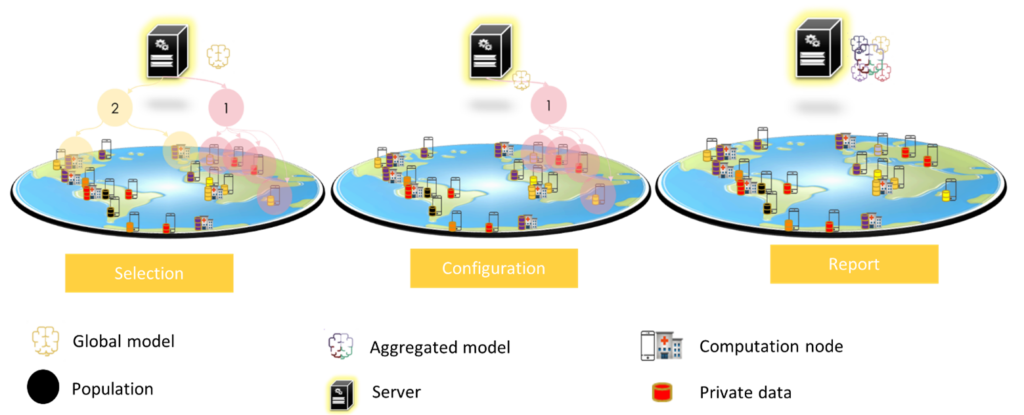
Federated learning comes mainly to solve the problem of privacy. This learning approach consists of training a model collaboratively based on each participant’s local data by sharing only its encrypted parameters instead of sharing data. This approach was first proposed by Google to predict user text input on tens of thousands of Android devices while keeping the data on the devices (Brendan McMahan et al. 2017). To achieve this goal, Google defined three main steps for communication between the device and the server (Bonawitz et al. 2019):
- Selection: devices that meet the eligibility criteria (e.g., on load and connected to an unlimited network) are registered in the server. The server selects a subset of the participants (population) to perform a task (training, evaluation) on a model.
- Configuration: the server sends a plan to the population that contains the training information of the model for the device and the aggregation information for the server.
- Report: in this phase, the server waits for device updates, to aggregate them using the federated averaging algorithm.
Federated learning has rapidly developed in the literature, we find several architectures (Aledhari et al. 2020) that depend mainly on applications. However, the authors of (Q. Yang et al. 2020) have been able to categorize federated learning architectures according to data distribution. These architectures differ in terms of structure and definition:
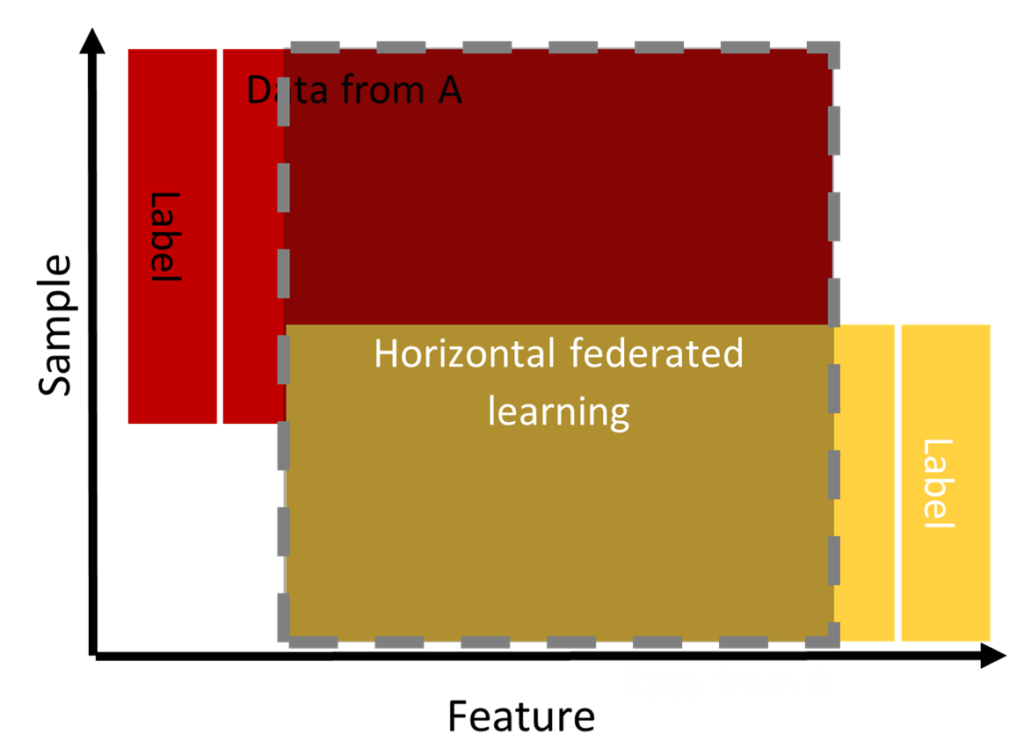
Horizontal federated learning (HFL)
Data follows a horizontal partitioning. For this, we find that the data overlap in “features space” but differ at the “sample space” level as shown in Figure 3 (Aledhari et al. 2020; Q. Yang et al. 2019, 2020). This learning is used when the population belongs to the same domain. For example, two banks in the same region can collaborate to detect users maliciously borrowing from one bank to pay the loan at another bank.
According to (Q. Yang et al. 2020), we can implement horizontal federated learning by following two types of architecture: a client-server architecture or a peer-to-peer (P2P) architecture. These architectures differ in training and aggregation processes.
Client-server architecture
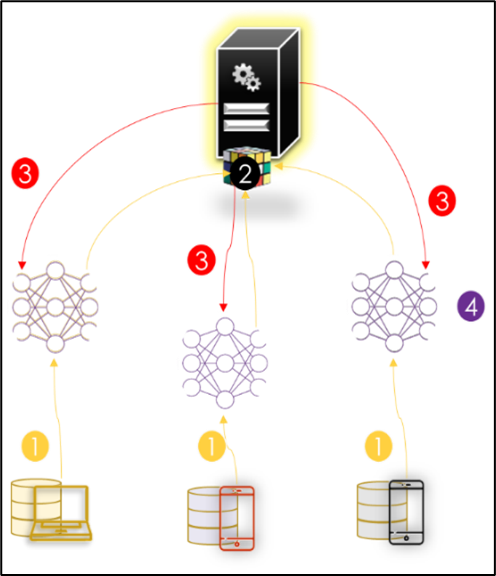
The client-server architecture is illustrated in the Figure below. In this system, participants (also called clients or users or parties) with the same data schema collaboratively drive a global model (also called a parameter server or aggregation server or coordinator).
FedAVG (Federated Averaging) is the algorithm used by Google to aggregate participant data. This algorithm orchestrates the training via the central server that hosts the global model. However, the actual optimization is performed locally on the clients using, for example, the Decent Stochastic Gradient (SGD). The FedAvg algorithm starts by initializing and selecting a subset of clients to train the global model. A Communication round consists of the following two steps:
- Step 1: After updating its local model, each client partitions its local data into B size batches and performs E epochs of the SGD, then uploads its local trained model to the server.
- Step 2: The server then generates the new global model by calculating a weighted sum of all local models received.
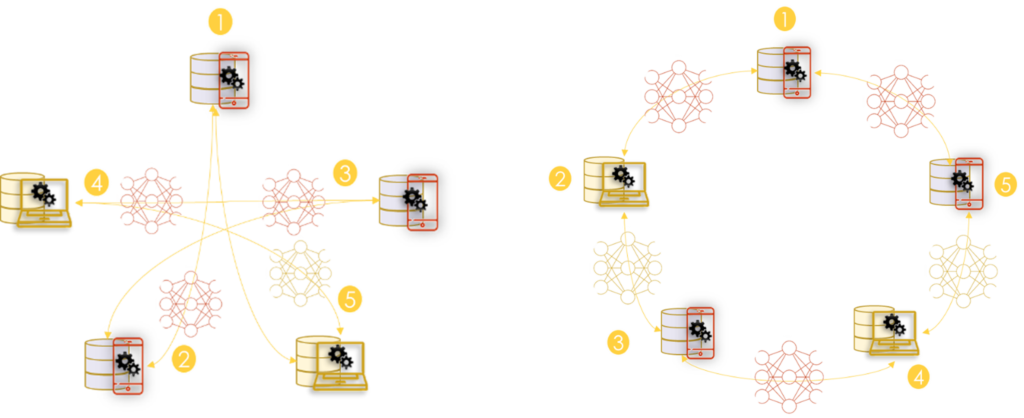
Peer2Peer architecture
P2P is the second proposed architecture for horizontal learning (Q. Yang et al. 2020). In this architecture, devices organize themselves to train a global model without serving as a central server. (Roy et al. 2019) presents algorithms for this architecture. The solution is fault-tolerant and there is no need to have a central server that everyone trusts. Thus, a random client can start an update process at any time.
The training process is done in 3 steps:
- Step 1: Each participant trains a model locally.
- Step 2: A random client from the environment starts the global training process. It sends a request to the rest of the clients to get their latest versions of the generated model.
- Step 3: all participants send their weights and learning sample size to the client.
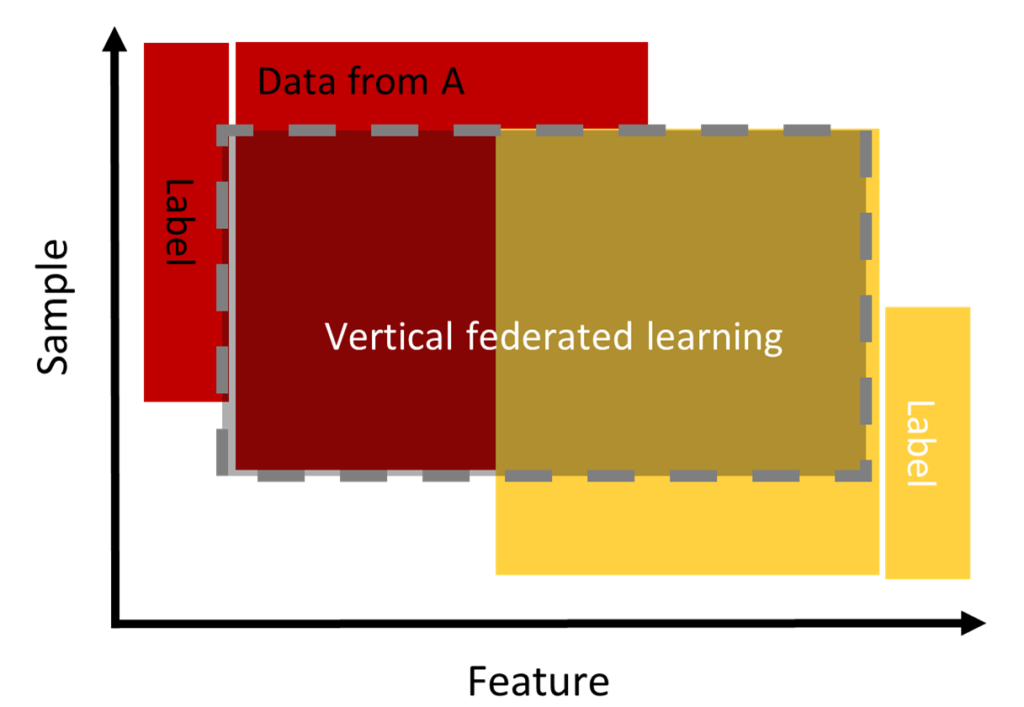
Vertical federated learning (VFL)
In this category and contrary to the horizontal approach, the population data overlap in “sample space” but differ in “feature space”. It is applicable for two entities belonging to two complementary domains. For example, two different companies in the same city: one is a bank and the other is an e-commerce company. Their “sample space” contains most of the residents of the area; thus, the intersection of their “sample space” is very wide. However, because the bank records user behavior in terms of income and spending and e-commerce retains user and shopping navigation, their feature spaces are very different.
The VFL can aggregate the features of both parties in order to obtain a model for forecasting product purchases based on user and product information. (Q. Yang et al. 2019).
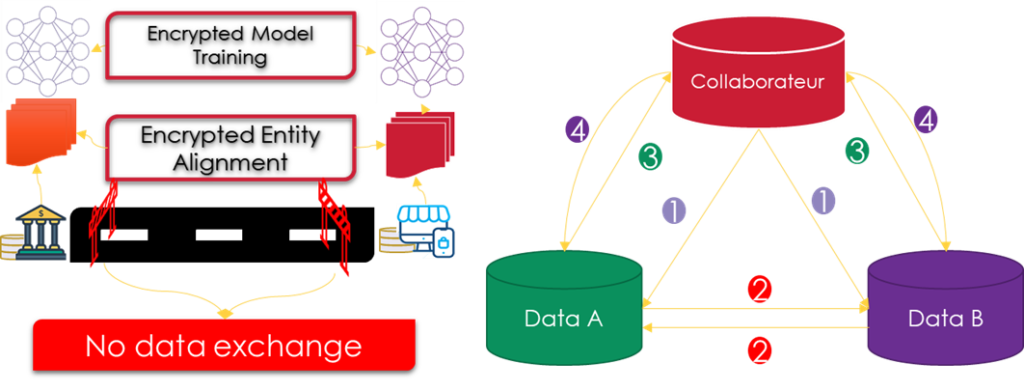
Suppose two companies A and B collaborate with each other to train a common model, the training process forces us to add an honest third-party C to ensure a secure calculation. The training of the model is done in two steps:
- Alignment of identifiers: The Identifier Alignment technique is used to confirm common users shared by both parties without exposing their respective raw data.
- Encrypted model training: After determining the common entities, we can use the data from these common entities to train a common ML model. The training process can be divided into four steps:
- Step 1: C creates encryption pairs and sends the public key to A and B.
- Step 2: A and B encrypt and exchange the intermediate results for gradient and loss calculations.
- Step 3: A and B calculate numerical gradients and add an extra mask, respectively. B also calculates the numerical loss. A and B send numerical results to C.
- Step 4: C decrypts the gradients and losses and sends the results back to A and B. A and B unmask the gradients and update the model parameters accordingly.
Federated transfer learning
The HFL and VFL require that participants must share either the feature space or the sample space to collaboratively train the model. However, in the real world user data may only share a small number of samples or features, and the data may also be distributed in an unbalanced way between users, or not all data is labeled. Faced with these limitations, the work of (Y. Liu et al. 2018; Q. Yang et al. 2019, 2020) has proposed combining federated learning with learning transfer techniques (Pan et al. 2011) which involves moving knowledge from one domain (i.e. the source domain) to another domain (i.e. the target domain) to achieve better learning outcomes. This combination is called federated transfer learning.
The work (Y. Liu et al. 2018) proposes an implementation based on the FATE platform. The architecture implemented is the same as VFL with two hosts containing the data and the arbiter that ensures, on the one hand, the aggregation of gradients and check if the loss converges, and on the other hand the distribution of public keys for the two hosts to avoid data exchange. To train the model the two hosts first calculate and encrypt their intermediate results locally using their data, which are used for the gradient and loss calculations. Then they send the encrypted values to the arbiter. Finally, the guest and host get the decrypted gradients and losses from the arbiter to update their models.
What are the applications of federated learning?
Federated learning is a subject of growing interest in the research and AI community. The association of this approach with confidentiality has led researchers and industry to apply it in many areas. Several applications are currently being studied.
Virtual keyboard word-prediction
This is the first project proposed for FL. The work (T. Yang et al. 2018) uses global federated learning to train, evaluate and deploy logistic regression mode to improve the quality of virtual keyboard search suggestions without direct access to the user’s underlying data. There are various requirements that clients must meet to validate their eligibility to participate in the FL process, such as, environmental requirements, device specifications, and language restrictions. On the other hand, other constraints on the FL tasks are defined by the server, which includes the number of target clients to participate in the process, the minimum number of clients required to initiate around, the frequency of training, a time threshold for waiting to receive client updates, and the fraction of clients that must report initiating around. In the work of (Hard et al. 2018), they trained a neural network to show that the federated approach performs better than the central approach. In this context, there is other work elaborated to adapt LF to this type of application such as the loss of emojis (Ramaswamy et al. 2019).
Healthcare
LF presents a new opportunity for this area. The new regularizations have begun to prevent the centralization of sensitive data such as patient data at hospitals. In this context, a multitude of works has already proposed an adaptation of this approach to the health field. The table in the appendix shows some applications. The prediction of mortality represents one of the most common applications in this field. The authors of (D. Liu et al. 2018) have proposed a new strategy to train a neural network in a way that is personalized to each hospital. For this purpose, the first layer will be trained in a collaborative way while the others will be constituted locally according to the stored data. This strategy has shown a high performance compared to the centralized method. (Huang et al. 2019) propose a community-based LF algorithm to predict mortality and length of hospital stay. Electronic medical records are grouped into groups within each hospital based on common medical aspects. Each group learns and shares a particular LF model, which improves efficiency and performance, and is customized for each community rather than being a general global model shared across all hospitals and therefore patients. Another type of application in this field is the recognition of human activity (Chen et al. 2019) proposed a strategy to train models based on data from portable medical devices. Device data may be distributed in different clouds depending on the provider and not exchanged due to imposed regulations. The authors proposed to apply federated transfer learning to share knowledge. In addition, this practice allows for the necessary customization of models because different users have different characteristics and business models.
Internet of Things (IoT)
The number of connected objects is increasing every year (Lueth 2018). These objects send a massive amount of data which increases the cost of communication, calculation, and storage. FL is a new implementation of device-based learning (Dhar et al. 2019) to ensure on one hand privacy and on the other hand to minimize the consumption of computing and communication. In the scientific literature, we already find a good number of applications of FL in this field. The work (Nguyen et al. 2019) proposes an intrusion detection system based on anomaly detection for IoT. This system consists of different security gateways, each of which monitors the traffic of a particular type of device, and at the same time drives the Gated Recurrent Unit model according to a federated process that relies on the local recovery and training of the model and then sends updates to an IoT security service to perform aggregation. Such a system works without users and is able to detect new attacks.
| Area | Training Device Type | Goal | Trained Model | Aggregation Algorithm |
| Gboard App | Mobiles phones | Language Modeling: Keyboard search suggestion Language Modeling: Next-word prediction Language Modeling: Emoji Prodiction Language Modeling: Out-of-Vocabulary Learning | Logistic Regression RNN RNN – LSTM RNN – LSTM | FedAvg FedAvg FedAvg FedAvg |
| Healthcare | Hospitals Scenario 1: Hospitals Scenario 2: Patients Phones connected to patients’ devices Organizations Conters Institutions Electreencephalography (EEG) Devices | Mortality Prediction Mortality & Hospital time stay Prediction Hospitalization Prediction Anomaly Detection in Medical Sy stems Human Activity Recognition Analysis of brain changes in neurological discases Brain Tumour Imaging Classification HEG Signal Classification | Neural Network Deep Learning Sparse SVM Neural Network Deep Neural Networks Feature Extraction CNN: U-Net Deep Neural Networks CNN | A proposed FADL FedAvg A proposed CPDS Average (not weighted) of parameters n/a Alternating Direction Method of Multipliers FedAvg FedAvg FedAvg |
| loT Systems | Gateway’s monitoring loT devices loT Objects or Coordinator (Cloud Server Edge Device) loT Devices Mobile Phones & Mobile Edge Computing Server | Anomaly Detection Lightweight Learning for resource-constrained devices Computation Offloading Improvement of loT Manufacturers services | RNN GRU Deep Neural Notworks Double Deep Q Learning Partitioned Doep model training | FedAvg n/a n/a n/a |
| Edge Computing | User Equipment Edge nodes | Computation Offloading Edge cashing | Reinforcement Learning | n/a |
| Networking | Machine Type Devices (MTD) | Resource block allocation & Power transmission | Markov Chain | Aggregation of MTDs Traffic Modbls |
| Robotics | Robots | Robots Navigation Decision | Reinforcement Learning | A proposed Knowledge Fusion Algorithm |
| Grid-world | Agents | Building Q-network Policies | Q-network | Multilayer Perceptron |
| FL Enhancement | Edge nodes | Determination of the aggregation frequency | Gradient-descent- based ML modols | FedAvg |
| Recommender System | Any user dev ice (e.g. laptops, phones) | Generation of personalized recommendations | Collaborative Filtering | Gradients Aggregation to update factor vectors |
| Cybersecurity | Gateways monitoring Desktop nodes | Anomaly Detection | Autoencoder | FedAvg |
| Online Retailers | Customers AR-enabled users | Click-Stream Prediction Edge cashing | RNN – GRU Autoencoder | FedAvg n/a |
| Wireless Communication | Radios Entities in the core network | Spectrum Management 5G Com Network | a spectrum utilization model n/a | n/a n/a |
| Electric Vehicles | Vehicles | Failure Prediction of EVs | RNN LSTM | Weighted Average based on loss function |
References
- S. Dhar, J. Guo, J. Liu, S. Tripathi, U. Kurup, and M. Shah, “On-device machine learning: An algorithms and learning theory perspective,” arXiv. 2019.
- H. Brendan McMahan, E. Moore, D. Ramage, S. Hampson, and B. Agüera y Arcas, “Communication-efficient learning of deep networks from decentralized data,” 2017.
- K. Bonawitz et al., “Towards federated learning at scale: System design,” arXiv. 2019.
- M. Aledhari, R. Razzak, R. M. Parizi, and F. Saeed, “Federated Learning: A Survey on Enabling Technologies, Protocols, and Applications,” IEEE Access. 2020, doi: 10.1109/ACCESS.2020.3013541.
- Q. Yang, Y. Liu, Y. Cheng, Y. Kang, T. Chen, and H. Yu, “Federated Learning,” in Synthesis Lectures on Artificial Intelligence and Machine Learning, 2020.
- Q. Yang, Y. Liu, Tianjian Chen, and Yongxin Tong, “Federated Machine Learning: Concept and Applications,” arXiv. 2019.
- H. B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y Arcas, “Federated Learning of Deep Networks using Model Averaging,” Arxiv, 2016.
- A. G. Roy, S. Siddiqui, S. Polsterl, N. Navab, and C. Wachinger, “BrainTorrent: A peer-to-peer environment for decentralized federated learning,” arXiv. 2019.
- Y. Liu, Y. Kang, C. Xing, T. Chen, and Q. Yang, “A secure federated transfer learning framework,” arXiv. 2018.
- S. J. Pan, I. W. Tsang, J. T. Kwok, and Q. Yang, “Domain adaptation via transfer component analysis,” IEEE Trans. Neural Networks, 2011, doi: 10.1109/TNN.2010.2091281.
- OpenMined, “PySyft,” 2020. https://github.com/OpenMined/PySyft.
- Google, “Tensorflow,” 2020. https://www.tensorflow.org/federated?hl=fr (accessed Jan. 18, 2021).
- Google, “tensor i/o,” 2020. https://www.tensorflow.org/io?hl=fr (accessed Jan. 18, 2021).
- AI Webank’s, “FATE,” 2020. https://fate.fedai.org/ (accessed Jan. 18, 2021).
- T. Yang et al., “APPLIED FEDERATED LEARNING: IMPROVING GOOGLE KEYBOARD QUERY SUGGESTIONS,” arXiv. 2018.
- A. Hard et al., “Federated learning for mobile keyboard prediction,” arXiv. 2018.
- S. Ramaswamy, R. Mathews, K. Rao, and F. Beaufays, “Federated learning for emoji prediction in a mobile keyboard,” arXiv. 2019.
- D. Liu, T. Miller, R. Sayeed, and K. D. Mandl, “FADL:Federated-Autonomous Deep Learning for Distributed Electronic Health Record,” arXiv. 2018.
- L. Huang, A. L. Shea, H. Qian, A. Masurkar, H. Deng, and D. Liu, “Patient clustering improves efficiency of federated machine learning to predict mortality and hospital stay time using distributed electronic medical records,” J. Biomed. Inform., 2019, doi: 10.1016/j.jbi.2019.103291.
- Y. Chen, J. Wang, C. Yu, W. Gao, and X. Qin, “FedHealth: A federated transfer learning framework for wearable healthcare,” arXiv. 2019.
- K. L. Lueth, “Number-of-global-device-connections-2015-2025-Number-of-IoT-Devices,” 2018. https://iot-analytics.com/state-of-the-iot-update-q1-q2-2018-number-of-iot-devices-now-7b/.
- T. D. Nguyen, S. Marchal, M. Miettinen, H. Fereidooni, N. Asokan, and A. R. Sadeghi, “DÏoT: A federated self-learning anomaly detection system for IoT,” 2019, doi: 10.1109/ICDCS.2019.00080.

