In the world of programming, creating efficient and functional software is a top priority, but it’s not just about writing lines of code. An essential part of the software development process is documentation, which includes the creation of explanatory comments that help to understand the operation and logic of the source code.
However, writing these comments can often be tedious and time-consuming for developers. Not only do they have to ensure that the code is well documented, they also have to ensure that the comments are clear, concise, and relevant. In a world of tight deadlines and high demands, this task can become a major obstacle to the productivity of development teams.
This is where the need for an automatic comment generation system for code comes in. Such a system would enable developers to save precious time by automating the comment-writing process. A great deal of research and study has gone into proposing methods using Machine Learning, Deep Learning, and other techniques for building code comment generation systems. However, to date, no method has been developed that can generate code comments in a completely reliable and satisfactory manner.
The recent success of LLMs, such as ChatGPT, is opening up new prospects. Their ability to understand and produce natural language makes them particularly well suited to the complex task of automatically and efficiently commenting on code.
However, challenges remain. LLMs can frequently generate erroneous or incomplete comments, and their performance can fluctuate depending on various factors such as the complexity of the code, its structure, the language used, and other elements.
Experimentation
To improve the results obtained by the LLMs, we have developed experimentation strategies aimed at providing additional information that enriches the context of the method and clarifies its ambiguous points.
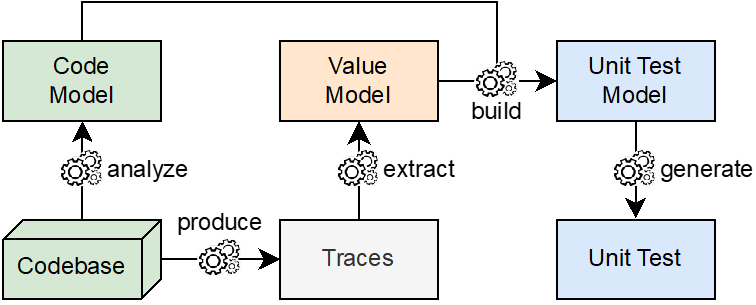
To retrieve this information, we use the Pharo tool, which is an open-source development environment and software platform that can be used to generate a Moose model for a project (an application, software, etc.). The model is a representation that shows the relationships between classes and methods, as well as other information describing the structure of the project, as shown in the image below.
Strategies
We have put in place four improvement strategies based on adding information to the prompt:
- Naïve strategy: We only provide instructions on the format of the comment to be generated, with no additional information on the method to be commented. This method is used as a reference to evaluate the basic performance of the LLM without any improvements.
- Incoming strategy: As well as instructions on the format, we include the body of all methods invoking the method to be commented.
- Outgoing strategy: In addition to the format instructions, we add the body of all the methods invoked by the method to be commented.
- Both strategy: This is a combination of the last two strategies, providing the methods invoking and invoked by the method to be commented.
Assessment and results
To evaluate the performance of each of the established strategies. Three experienced developers were asked to rank in order of preference four comments generated by the different strategies for seven distinct Java methods. The LLM chosen for the generation was Model CodeLlama version 13B.
Points were awarded to the strategies according to the rankings of their comments, and the results are shown in the following graph:

In our graph, we can see that the naive method received fewer points than the other methods, and the best performances were observed for the Incoming and Outgoing strategies.
The following graphs represent the number of times a method has appeared in each position of the ranking, and we can see that the naive strategy very often comes last:
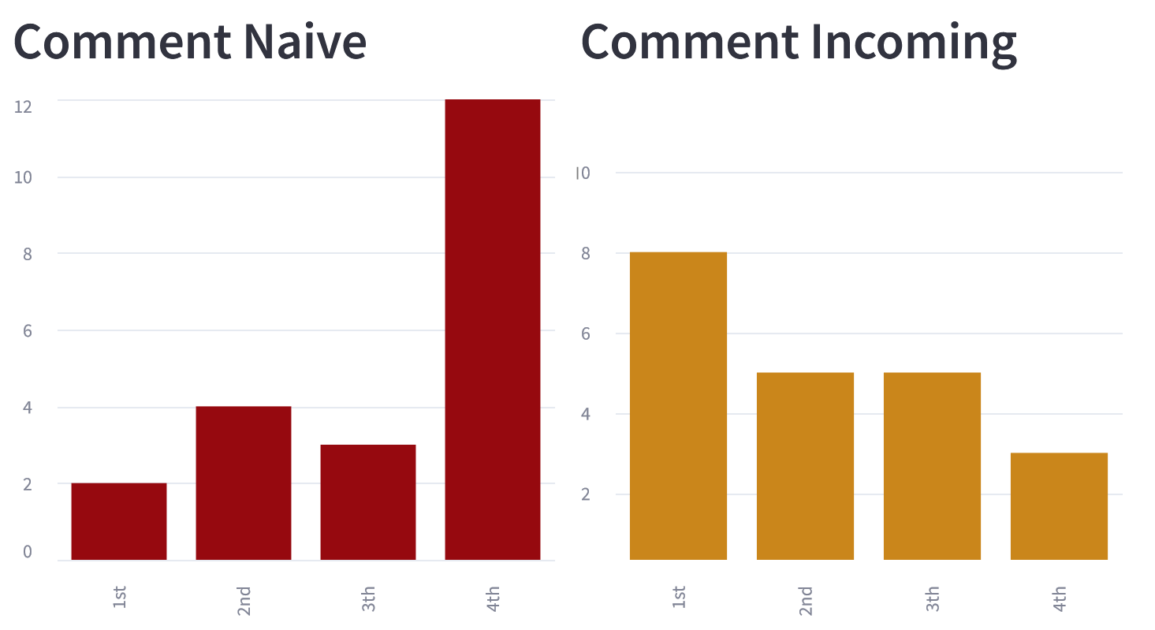
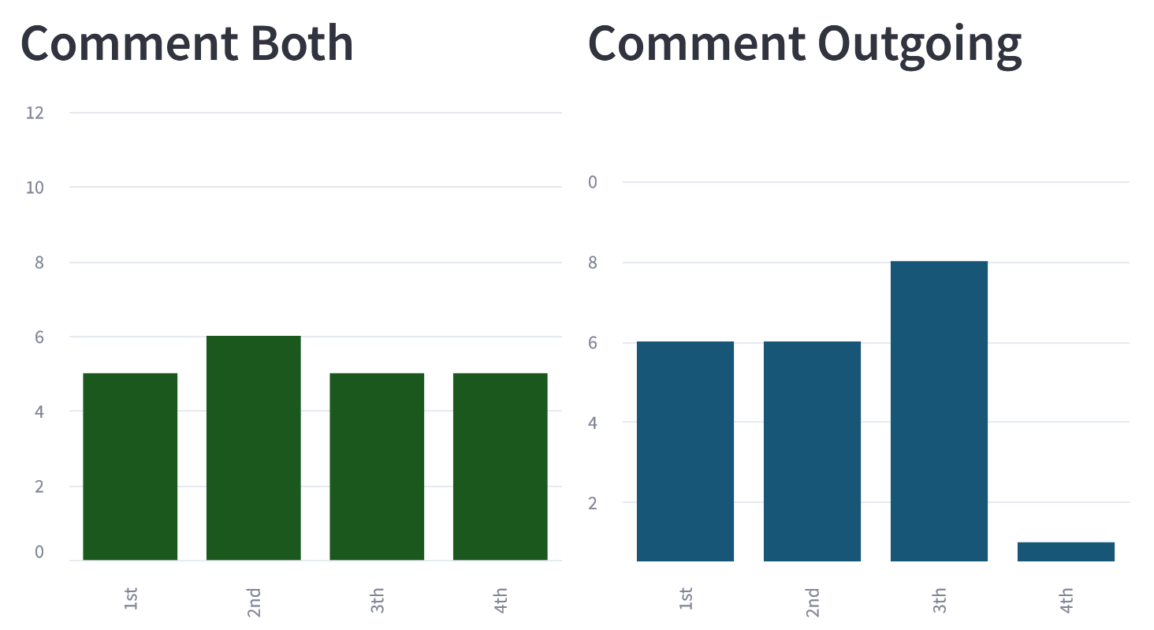
These initial results suggest that our improvement strategies have a positive impact on LLM performance. This reinforces the hypothesis that adding additional information from a Moose model linked to the method to be commented can be effective.
Nevertheless, limitations relating to this test prevent us from being able to draw definitive conclusions. Here are the limitations identified:
- Reading and understanding the code to be commented on and the comments for their assessment is a time-consuming task, requiring great concentration and a rigorous analytical sense. It must therefore be carried out by professionals. This limits the number of participants, the number of methods they can be asked to evaluate, and the number of times the test can be repeated.
- Although instructions on the desired comment format have been added to the prompt, the LLM frequently generates comments in a non-compliant form, sometimes adding code or text that does not correspond to the Javadoc format. This may have influenced the evaluators’ decisions.
- The fact that the comments have to be sorted does not give any indication of their quality. If the comments are all bad, the evaluator is nevertheless forced to sort them without being able to express an opinion on their value.
Conclusion
In this first experiment, we defined three strategies aimed at increasing the effectiveness of an LLM in comment generation, in addition to the naive generation that served as a point of comparison. We then conducted an evaluation test of the strategies developed, the results of which reinforced our hypotheses on the effectiveness of adding information from a Moose model to improve the comment generation performance of an LLM. In addition, we identified the limitations of this experiment.
The study as a whole suggests several areas for improvement, and points us in the direction of future work:
- Exploring the addition of other information to the prompt, such as the objects called by the method or the methods linked directly or indirectly to it, is a promising avenue to test.
- Using a more powerful LLM could prevent comments from being generated in an inappropriate format.
- One approach to consider is to carry out syntax tests to assess the format of the comments generated.
- Find less time-consuming evaluation methods that can be automated and used as heuristics.
- To improve the evaluation, it would be appropriate to ask participants to rate the comments rather than rank them. This approach would give us more information about their qualities.