
Introduction
Retrieval-Augmented Generation systems [Li et al., 2025], called RAG, rely heavily on how documents are segmented before indexing. This preprocessing step, known as chunking, directly affects retrieval quality and, consequently, the performance of downstream question-answering systems.
In practice, chunking strategies [Jain et al., 2025] hardly take into account the document structure; instead, documents are usually split into fixed-size segments without considering their semantic content or modality. Some more advanced strategies, for example recursive chunking, propose adapting this window size so that it avoids cutting text mid-sentence. While these one-size-fits-all approaches are easy to implement, they are not well suited for heterogeneous, real-world corpora that include text, tables, and images. This is especially true for domain-specific, production-ready solutions.
This article presents the design and evaluation of a dynamic chunking strategy tailored for a multimodal RAG pipeline. The objective is twofold:
- Develop a generic, adaptive chunker that can handle diverse document types.
- Quantitatively evaluate its impact on retrieval performance in realistic settings.
The Practical Challenges of Multimodal Data
The documents used in this work originate from several domain-specific datasets, including assistance materials for the use of management software, documentation related to the CMMS Carl Software (CMMS Software | CARL Berger-Levrault), and the Légibase Platform(Légibase Collectivités, votre portail d’informations juridiques), all of which are derived from real Berger-Levrault products. These documents span multiple formats, including plain text, HTML pages, and PDF/DOCX files.
These documents can be broadly categorized into three types based on the modality of the data they contain:
- Text-only documents, with no embedded structure beyond paragraphs.
- Web pages, often containing complex tables and structured layouts.
- Rich documents (PDF/DOCX), which may include images, diagrams, and mixed content.
To ensure a robust evaluation, a balanced dataset of approximately 850 documents, evenly distributed across document sources and modality, was constructed. This dataset reflects both the diversity of formats and the variability of real-world use cases.
A Dynamic and Generic Chunking Strategy
Rethinking the Need for Chunking
Previous experiments suggested a counterintuitive result: in some cases, the best chunking strategy is not to chunk at all. Splitting already short documents can introduce unnecessary fragmentation and degrade coherence. This is true as long as the total token size is lower than the maximum token window of the embedding model used [Opitz et al., 2025].
Based on this observation, the proposed method first distinguishes between:
- Short documents, which are kept intact (up to 8,000 tokens).
- Long documents, which require segmentation.
Structure-Aware Segmentation
For long documents, the chunker applies a set of rules designed to preserve semantic coherence:
- Tables and image descriptions are isolated into dedicated chunks.
- Longer tables are further chunked into multiple parts to ensure each chunk respects the maximum size.
- Tables are converted into Markdown format [Yu et al., 2025] using the pandas library (GitHub – pandas-dev/pandas: Flexible and powerful data analysis / manipulation library for Python, providing labeled data structures similar to R data.frame objects, statistical functions, and much more).
- Headers are extracted and appended to each table chunk.
- These specialized chunks are enriched with surrounding text context to improve interpretability.
- The remaining textual content is segmented using either recursive or direct chunking, with a maximum size of approximately 1,200 tokens.
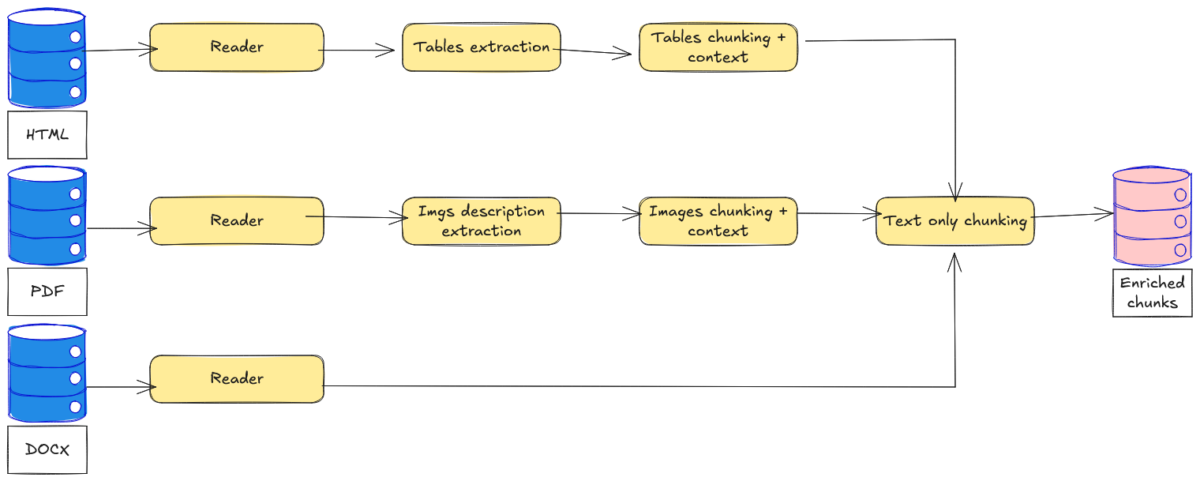
Our approach is presented in Figure 1, where we can see how each modality is handled by a specific data pipeline.
Experimental Evaluation
Objectives and Setup
The evaluation aims to measure the impact of dynamic chunking on an information retrieval system within a controlled environment.
To simulate realistic usage, queries are automatically generated from document content using an LLM (Large Language Model). For each document, we extract 5 random text excerpts and prompt Mistral Large (Introducing Mistral 3 | Mistral AI) to generate user-like questions based on each of these excerpts, thus ensuring coverage across different sections of the text.
Two indexing strategies are compared:
- A baseline using fixed-size chunks (naive chunking).
- The proposed dynamic chunking method.
Both are implemented using vector databases, with Weaviate (The AI database developers love | Weaviate), and evaluated across multiple retrieval modes: lexical (BM25), semantic (vector search), and hybrid approaches. Performance is assessed using standard metrics, including Mean Reciprocal Rank (MRR), Normalized Discounted Cumulative Gain (nDCG at 10), and Recall.
Results
Global Performance
We aggregate results by computing the mean across all questions for all three metrics used. We report these aggregated numbers in Figure 2. The results show that dynamic chunking performs comparably to the baseline. In some configurations, especially hybrid search, slight improvements are observed, but the differences remain moderate.
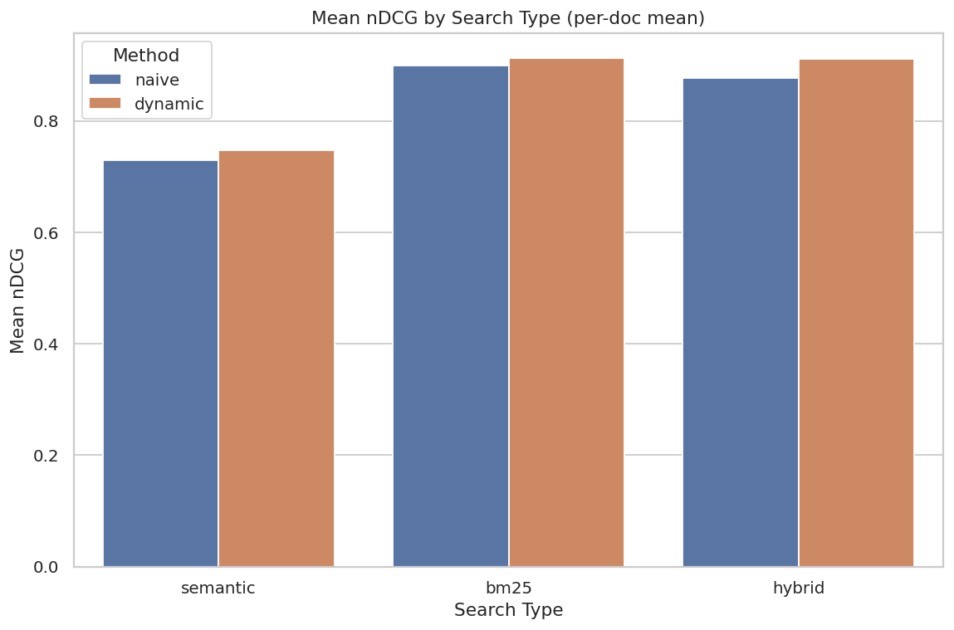
Importantly, increasing the number of chunks per document does not degrade retrieval performance. This indicates that finer-grained segmentation, when applied carefully, does not dilute the relevance signal.
Impact on Difficult Documents
A more detailed analysis reveals a key advantage of the dynamic approach. Documents that perform poorly under naive chunking benefit significantly from the proposed method.
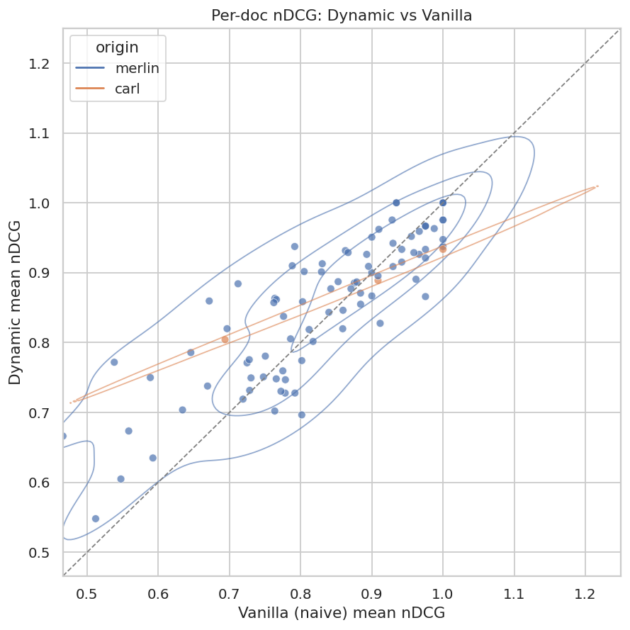
To evaluate this, we compute, for each question, the difference (delta) in retrieval performance between naive chunking and dynamic chunking. We then analyze these differences separately for the questions that perform best and worst under the baseline method, allowing us to understand where dynamic chunking brings the most benefit. These results are presented in Figure 3. By Merlin, we refer to our use case dedicated to assistance for management software, and by Carl, to a use case focused on CMMS.
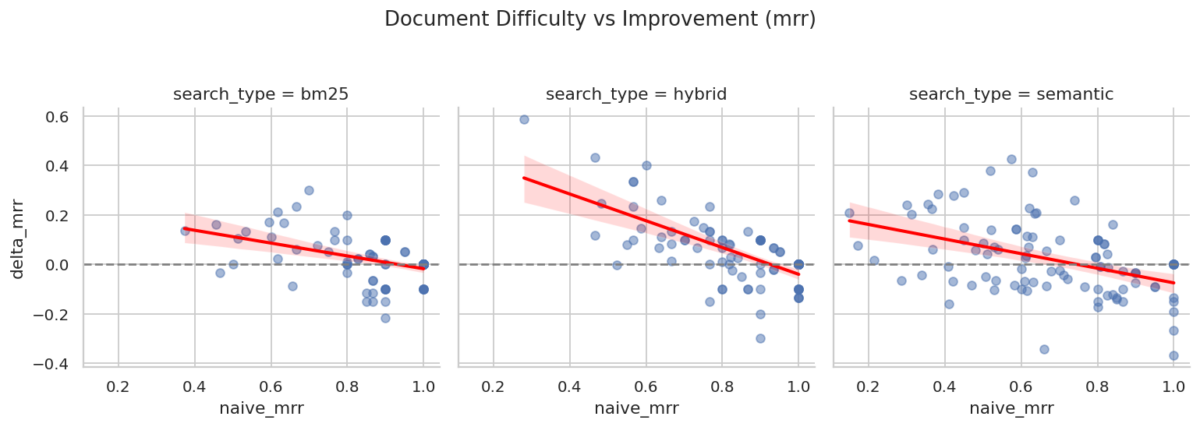
Statistical analysis, via a slope metric presented in Figure 4, confirms this trend. This slope is obtained by fitting a linear relationship between baseline retrieval performance and the improvement observed with dynamic chunking. A negative correlation indicates that lower-performing cases benefit more from the proposed method: the lower the initial retrieval quality, the greater the gain from dynamic chunking. This effect is particularly strong for hybrid search, where both lexical and semantic signals are combined.
Effect of Chunking Complexity
Dynamic chunking introduces additional complexity, including:
- A higher number of chunks per document.
- The presence of specialized chunks (e.g., tables, image descriptions).
- Greater variability in chunk size and structure.
To assess whether this complexity negatively impacts retrieval, several indicators were analyzed (e.g., chunk inflation ratio, proportion of specialized chunks). The chunk inflation ratio measures how the number of chunks produced by dynamic chunking compares to the baseline, defined as the ratio between the number of chunks generated by the dynamic method and the number generated by naive chunking for the same document. The results, presented in Figure 5, show weak to non-significant correlations with retrieval performance.
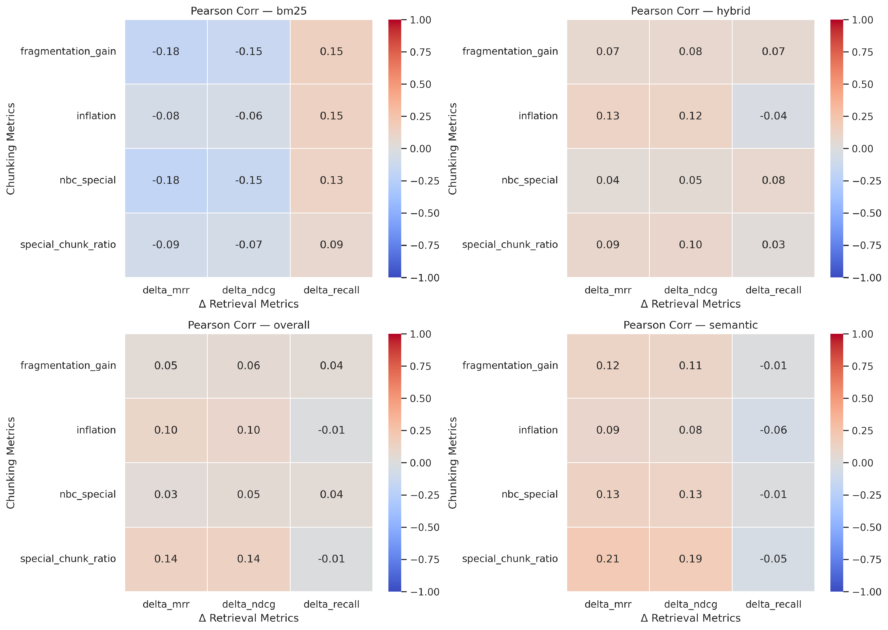
This suggests that the added complexity does not harm the system, provided that the segmentation remains semantically meaningful.
Discussion
The findings highlight an important property of dynamic chunking: it acts as a robust improvement layer rather than a risky optimization.
For straightforward documents, the method behaves similarly to naive chunking, preserving performance. For complex or poorly structured documents, it provides substantial gains by better aligning chunks with semantic units.
This behavior is particularly valuable in production environments, where document quality and structure can vary widely across use cases.
Conclusion
This work introduces a dynamic, structure-aware chunking strategy designed for multimodal RAG systems. The approach integrates several key ideas:
- Avoid unnecessary chunking for short documents.
- Preserve semantic units such as tables and image descriptions.
- Enrich structurally complex elements with contextual information.
Empirical evaluation on a diverse dataset shows that this method improves retrieval performance in challenging cases while maintaining overall stability. Moreover, the increased number of chunks and structural complexity do not introduce measurable drawbacks.
These results support the adoption of dynamic chunking as a reliable and scalable preprocessing step for real-world RAG pipelines, particularly in domains involving heterogeneous and multimodal data.
Bibliography
- Arihant Jain, Purav Aggarwal, and Anoop Saladi. 2025. AutoChunker: Structured Text Chunking and its Evaluation. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 6: Industry Track), pages 983–995, Vienna, Austria. Association for Computational Linguistics.
- Juri Opitz, Lucas Moeller, Andrianos Michail, Sebastian Padó, and Simon Clematide. 2025. Interpretable Text Embeddings and Text Similarity Explanation: A Survey. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 22303–22319, Suzhou, China. Association for Computational Linguistics.
- Yangning Li, Weizhi Zhang, Yuyao Yang, Wei-Chieh Huang, Yaozu Wu, Junyu Luo, Yuanchen Bei, Henry Peng Zou, Xiao Luo, Yusheng Zhao, Chunkit Chan, Yankai Chen, Zhongfen Deng, Yinghui Li, Hai-Tao Zheng, Dongyuan Li, Renhe Jiang, Ming Zhang, Yangqiu Song, and Philip S. Yu. 2025. A Survey of RAG-Reasoning Systems in Large Language Models. In Findings of the Association for Computational Linguistics: EMNLP 2025, pages 12120–12145, Suzhou, China. Association for Computational Linguistics.
- Xiaohan Yu, Pu Jian, and Chong Chen. 2025. TableRAG: A Retrieval Augmented Generation Framework for Heterogeneous Document Reasoning. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 14063–14082, Suzhou, China. Association for Computational Linguistics.



