
Introduction
The Language Server Protocol (LSP) is a standard that defines how code editors communicate with language-specific servers to provide advanced development features such as autocompletion, go-to-definition, find references, and diagnostics (errors and warnings). Before LSP, each editor had to implement its own support for every programming language, leading to duplicated effort and inconsistent feature quality across tools.
LSP addresses this by decoupling the editor experience from language-specific logic. Instead of embedding language intelligence directly into each editor, this logic is centralized in language servers and reused across multiple editors. In practice, the editor (client) sends requests such as completion or definition queries, over a JSON-RPC channel, the language server processes them using language-specific analysis, and then returns results that the editor displays.
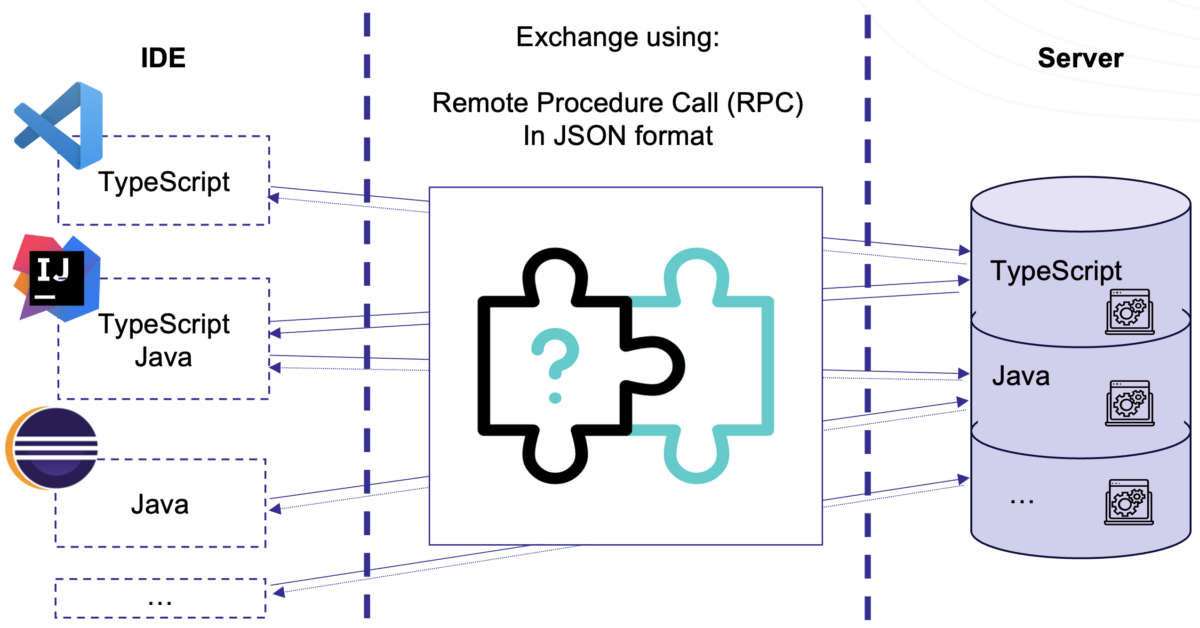
This approach significantly reduces duplication while ensuring more consistent behavior across development environments. Many robust language servers already exist and are widely used in tools like VS Code. Popular examples include tsserver for TypeScript/JavaScript and Pyright for Python.
At Berger-Levrault, we decided to build on top of these existing language servers, an internal rule layer tailored to our needs. This layer enforces company standards and best practices (such as limiting the number of classes per package) as well as project-specific architectural constraints (such as maintaining layered designs with DTOs and preventing direct database access). To support this, we developed our own LSP-based solution called Duck, currently available in VS Code, with IntelliJ and Eclipse support in progress.
Approach
Our approach is based on creating a separate server developed using the Pharo Language. In addition to this core server, we developed extensions separately for each Integrated Development Environment (IDE). For example, for Visual Studio Code (VSCode), we use TypeScript to create these extensions, ensuring compatibility and leveraging the strengths of the respective development environments.
Why Pharo ?
Pharo is a modern, Smalltalk-based language and integrated IDE. It comes with Moose, a platform for software analysis that provides ready-to-use metamodels and libraries. Moose was created after years of research supported by multiple publications. It supports analyzing TypeScript, Java, and more recently, Python projects. With Moose, teams can perform concrete analyses such as decoupling microservices, verifying architecture consistency, tracking constant usage, customizing coding rules, and validating layer integrity across a codebase. Choosing Pharo for our LSP server lets us leverage Moose’s libraries to parse projects and create our rules on the server side, keeping the editor client lightweight while centralizing analysis and governance in one place.
Tools
To successfully carry out this project, it is necessary to use several different tools:
- LSP library compatible with Pharo: this forms the foundation for any LSP project. We implemented it based on Microsoft’s LSP library. This protocol manages interactions between the IDE and the server.
- We start with metamodels representing the studied languages, grouped into two categories: Famix metamodels (e.g., Famix Java, Famix TypeScript) represent projects open in the IDE, including classes, packages, methods, and their links, essential for applying architectural rules. FAST metamodels (Famix AST, like FASTTypeScript and FASTJava) parse source code per container (e.g., a class) to enable rules related to business logic standards, such as maximum methods per class.
- A link between metamodels relates corresponding entities: Famix and FAST are distinct metamodels but represent the same project entities. It is crucial to identify which FASTEntity corresponds to a FamixEntity, such as a Java class.
- Updaters refresh the models after each change: on every change, a series of heuristics runs, starting with code parsing and ending with IDE actions (e.g., displaying comments). A mandatory heuristic updates the model to track user changes, ensuring a reliable end-user experience.
- Pattern matching tool to create rules: Rules use the MoTion pattern matching library compatible with Pharo. MoTion enables deep searches over ASTs, allowing flexible creation of complex rules requiring detailed entity searches.
- Parsers convert source code into metamodel representations: Parsing transforms source code text into Famix and FAST models. Parsing is challenging in live mode, as each user change triggers parsing to apply relevant rules and provide feedback. We researched safe parsing methods and adopted incremental parsing, which parses the entire file initially, then parses only changes thereafter, updating the generated tree instead of recreating it. This approach saves significant time and ensures reliability for developers. We chose the Tree-Sitter parser and created Pharo-Tree-Sitter to generate FAST metamodels in Pharo using Tree-Sitter.
Server
We ultimately built our own language server using Pharo and made it available online. From a user perspective, there is no need to manually download or install the server, only the client extension is required. The client automatically handles the setup by downloading a Pharo image that includes the BL Language Server. Because the server runs locally on the user’s machine, this approach also ensures faster communication between the client and the server, resulting in a smoother and more responsive experience.
Client
The client can be installed on VSCode and implemented for other IDEs not yet public.
Demos
In the following we show some demos one for architectural and one suggesting a correction.
Demo 1
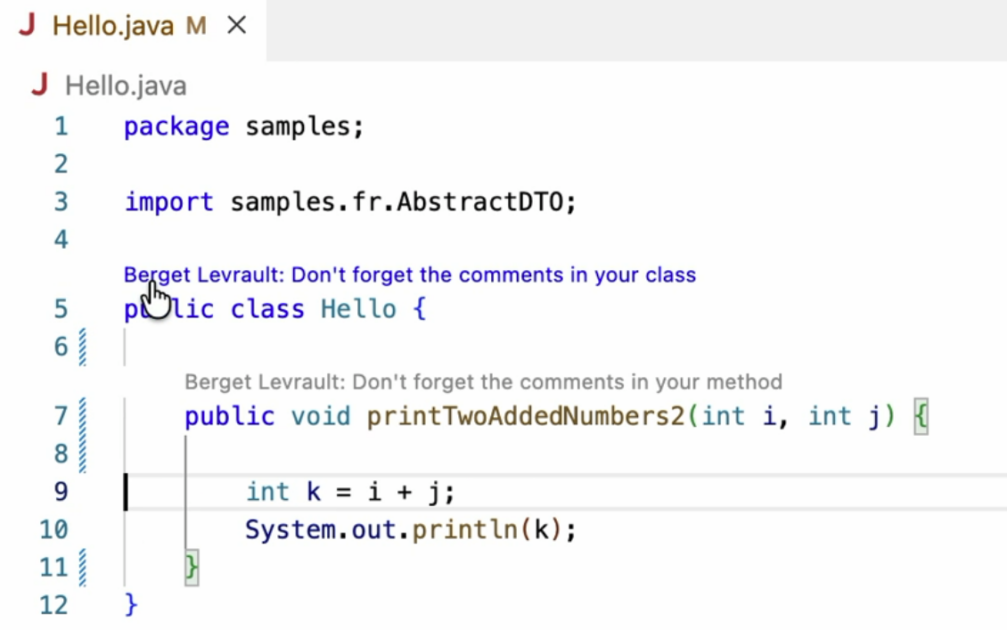
The example below demonstrates a rule that suggests adding comments to Java classes and methods when they are missing. These suggestions appear as messages displayed above the corresponding class or method, prefixed with “Berger-Levrault” to distinguish them from standard LSP messages.
Demo 2
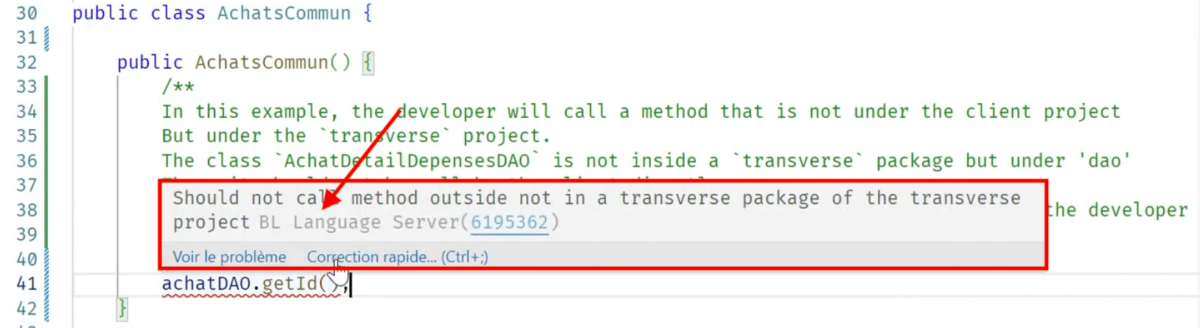
The example below illustrates a rule that prevents calling a method from outside a specific package. This rule is very specific to Berger-Levrault and is designed to preserve the intended project architecture as defined by the architects. When violated, the rule appears as an error message highlighted directly in the code, with an underline indicating the problematic line. The message is shown in a box and can be expanded to display additional details in a panel on the right side of VS Code.
Future work
Future work will focus on extending Duck to support additional programming languages and integrating more rules based on user needs. We also plan to introduce rule customization per team or group of developers, which may require a dedicated administration interface.
Another key direction is supporting polyglot environments by enabling rules that apply across multiple languages (for example for projects that use frameworks like ReactJS), ensuring consistency in complex, multi-technology projects.
Conclusion
Within the DRIT, we actively foster innovation and research as a core part of our mission. This work is the result of several years of research and development, during which we progressively designed and built each component as part of a broader, cohesive vision.
We have also shared our approach with the wider community, notably through a presentation at DevFest Toulouse, where we received positive feedback from participants representing a variety of companies and technical backgrounds. This external validation reinforces the relevance and impact of our work.
To further demonstrate and formalize our contributions, we have engaged in publishing our results at international conferences, ensuring that our work meets both academic and industry standards. Looking ahead, we aim to continue addressing new challenges step by step, by tightly combining Research and Development to drive innovation and deliver practical, high-value solutions.



