
Keywords: Synthetic Data, Retrieval-Augmented Generation (RAG), Small Language Models (7B LLM), Large Language Models (LLM like GPT-4o or GPT4.5), Model Adaptation, Efficient Model Tuning, Low-Resource Fine-Tuning, Synthetic Fine-Tuning.
1. Introduction
In the context of our Research & Innovation efforts at Berger-Levrault, we are exploring how large language models (LLMs) can enhance customer support through intelligent, domain-specific ChatBots. One such application is to assist customer support by quickly providing accurate, contextualized answers and references relevant to their daily tasks.
LLMs have shown remarkable capabilities across a wide range of text generation tasks, a trend confirmed by our own internal evaluations. However, transitioning from experimental prototypes to production-ready solutions demands more than just raw performance. For our ChatBots to serve various products and business units (BUs) effectively, the underlying model must be adaptable, controllable, and aligned with our strategic priorities—including model sovereignty.
The initial version of our assistant relies on response generation via the OpenAI API, which, while effective, raises concerns regarding data governance and long-term operational autonomy. To address this, we are actively working on a new architecture powered by open-source generative models.
Since most open-source LLMs currently fall short of state-of-the-art (SOTA) proprietary models in terms of zero-shot performance, our approach focuses on synthetic fine-tuning: we enhance these models using domain-specific synthetic data generated by larger, high-performing LLMs like GPT-4. This technique allows us to specialize smaller models (e.g., 7B parameter LLMs) to better fit our use cases while retaining full control over deployment and adaptation.
In addition to strategic and functional considerations, the use of small language models (SLMs)—whether commercial or custom fine-tuned—also contributes to sustainability. Recent studies have quantified the environmental benefits of deploying compact models. For instance, Nguyen et al. (2024) analyzed the performance and energy consumption of LLaMA models with 1B, 3B, and 7B parameters, highlighting the potential for optimizing sustainable LLM serving systems by considering both operational and embodied carbon emissions simultaneously. Similarly, Jegham et al. (2025) introduced a benchmarking framework revealing that certain compact models, like Claude-3.7 Sonnet, exhibit high eco-efficiency, consuming markedly less energy per query compared to larger models. These findings underscore the potential of deploying smaller, specialized models to meet business needs while aligning with sustainability goals.
This blog post presents our ongoing work, methodology, and preliminary results in building sovereign, efficient, and domain-optimized generative AI solutions tailored for real-world, business-critical applications.
2. Methodology Overview
The complete pipeline we developed to adapt open-source LLMs to our domain-specific chatbot is depicted in Figure 1. Our goal is to produce a high-quality supervised dataset tailored to our business context—without relying on manually labeled data. To achieve this, we exploit synthetic data generation, orchestrated through the interplay of chunked documents, a commercial LLM (OpenAI), and a lightweight open-source model (Mistral 7B provided by Mistral AI).
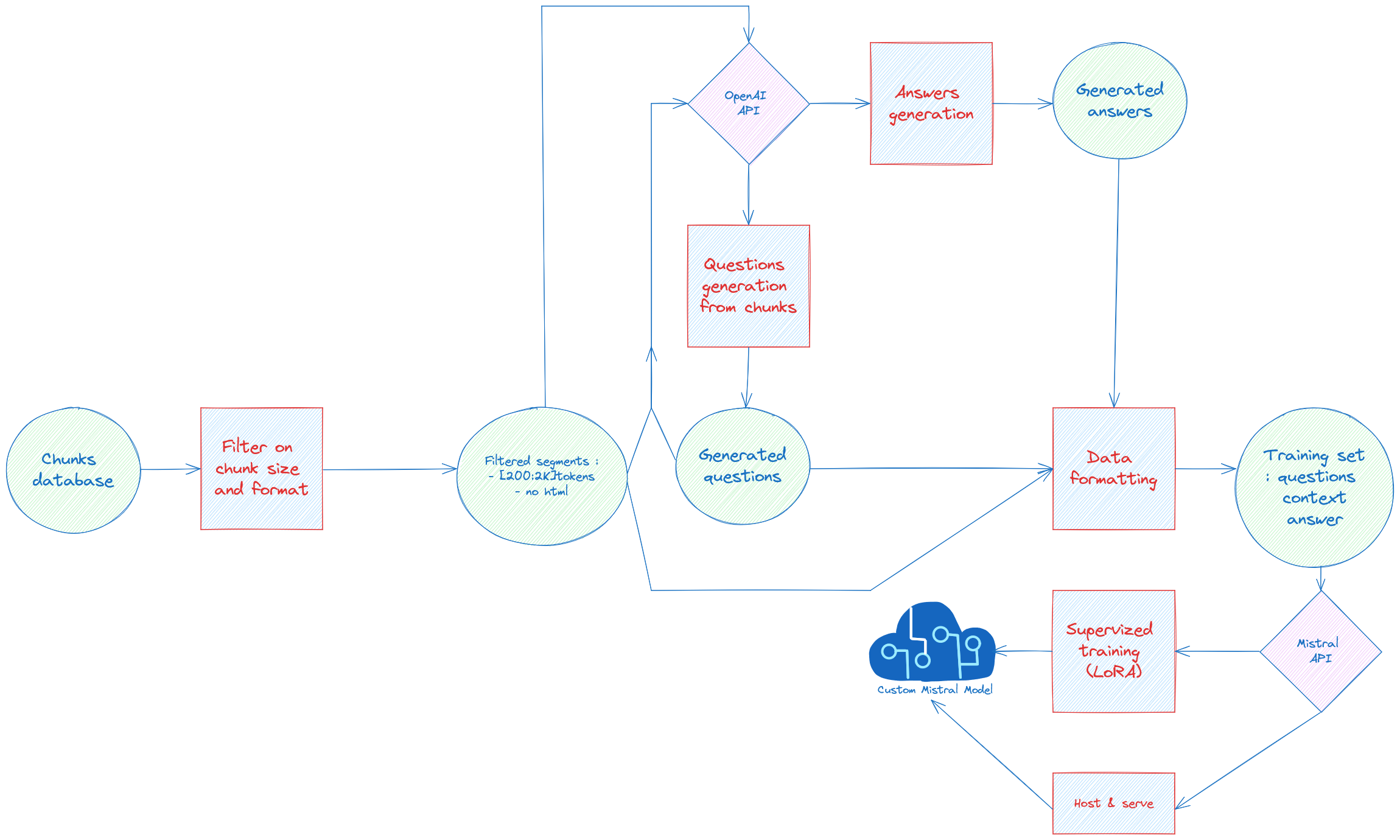
Step-by-Step Pipeline Explanation
- Chunks Preparation
We start with a structured database of textual chunks, extracted from internal documentation. These chunks undergo a filtering process based on size and format constraints to ensure they are clean, well-formed, and semantically complete. We retain only those segments that contain fewer than 1200 tokens and exclude noisy or irrelevant content (e.g., HTML artifacts). - Synthetic Question Generation
For each filtered segment, we generate relevant questions using a prompted OpenAI GPT 3.5 model. This step ensures that the questions are well-aligned with the context of each chunk, mimicking how a user might query the system in a real-world scenario. - Synthetic Answer Generation
The GPT-4 model proposed by OpenAI is then used to generate answers for the previously generated questions. These answers leverage the chunk context, producing high-quality QA pairs that simulate supervised annotations. - Training Set Construction
The generated question-answer pairs, together with their associated source context (i.e., the chunk), are then formatted into a supervised dataset. This forms a robust training set in the structure:question | context (target segment + others bad segments) | answer - Fine-Tuning via LoRA
This dataset is used to fine-tune a customized Mistral 7B model, applying a LoRA (Low-Rank Adaptation) technique. This efficient fine-tuning strategy enables us to inject domain knowledge into the model without retraining it from scratch, significantly reducing computational requirements. - Deployment & Serving
The fine-tuned model is finally hosted and served as the core of our domain-specific assistant, ready to answer user queries in production with both speed and relevance.
This methodology allows us to leverage the intelligence of large, proprietary models like GPT-4 to “teach” smaller, open models in a controlled, cost-effective, and sovereignty-compliant manner. By generating high-quality synthetic training data aligned with our business domain, we achieve a tailored assistant capable of operating within our constraints—while still delivering a high standard of natural language understanding and generation.
3. Synthetic Dataset Generation for Domain Adaptation
To support the development of our domain-specific assistant, we collaborated with several Berger-Levrault business units to collect a diverse and representative corpus of internal documentation. This cooperative effort enabled us to build a comprehensive and up-to-date knowledge base covering various aspects of Berger-Levrault’s products and services, including software usage guides, legal regulations relevant to town halls, and accounting standards.
However, while this document base constitutes a rich source of information, it does not directly translate into usable training data for large language models (LLMs). Raw documents lack the explicit question-answer structure and expert-level supervision needed to guide LLM behavior in a controlled, task-specific way. Following discussions with domain experts, it became clear that manual annotation of QA pairs would be prohibitively costly and time-consuming.
To address this challenge, we adopted a synthetic data generation approach, leveraging LLMs to simulate expert annotations and produce a high-quality, domain-aligned training dataset. The overall pipeline, illustrated in Figure 1, includes automated question generation, answer synthesis, context retrieval, and final formatting into fine-tuning-ready samples. The following describes each step in detail.
3.1. Step 1: Question Generation
We began by preparing the source material: a corpus of 13,767 document segments, each limited to 1,200 tokens. These segments originated from a wide range of formats, including HTML pages, PDFs, and content extracted from WordPress sites. From this pool, we randomly sampled 3,400 segments and generated three questions per segment, yielding approximately 10,000 synthetic questions.
To generate these questions, we used OpenAI’s GPT-3.5 model, which had previously demonstrated strong performance during the initial evaluation phases of our ChatBot customer support. While tools like llamaindex offer built-in support for question generation, they lacked the customization and control we required. As a result, we developed our own dedicated tool for question generation and dataset construction. This allowed us to integrate domain-specific context and adapt prompt templates to align closely with the conversational logic used in the ChatBot.
3.2. Step 2: Answer Generation and Context Retrieval
Once the questions were generated, we used OpenAI’s GPT-4 model to synthesize corresponding answers. This choice was guided by its superior performance in prior expert evaluations. For each question, we retrieved additional context segments using a simple retrieval system based on cosine similarity between embedding vectors, generated with OpenAI’s text-embedding-ada-002 model.
Each question was thus paired with its original source segment and four additional semantically similar segments. We then applied the most effective RAG-style prompt (used internally for the ChatBot) to generate precise, context-aware answers without the need for extended features such as source attributions or visual enhancements.
3.3. Step 3: Data Formatting and Edge Cases
The resulting question-context-answer triplets were then converted into a format compatible with supervised fine-tuning. Each sample was structured using a simple RAG prompt template, preparing the dataset for training lightweight, open-source models (e.g., Mistral 7B).
To enhance the robustness of the model and promote its ability to gracefully handle uncertainty, we also introduced negative examples into the training set. Inspired by the principles of RAFT (Retrieval-Augmented Fine-Tuning) but taking an inverse approach, we deliberately constructed cases where the retrieved segments were irrelevant to the question. In these examples, the correct response was a calibrated fallback such as “I don’t know”. This behavior—acknowledging the limits of model knowledge—is highly valued by experts and critical for deployment in real-world applications where overconfidence can lead to errors.
4. Fine-Tuning a Small Mistral Model via Mistral API
To adapt our synthetic dataset to an open-source language model while preserving efficiency and control, we chose to use the Mistral API platform, which not only provides access to powerful pre-trained models but also recently introduced support for custom training workflows. Specifically, we opted for Parameter-Efficient Fine-Tuning (PEFT), using the Low-Rank Adaptation (LoRA) method, which is particularly well-suited for scenarios with limited training data.
Our hypothesis is that LoRA, by updating only a small subset of the model’s parameters, can yield significant performance improvements even when fine-tuning with a relatively small dataset—approximately 10,000 examples in our case.
4.1. Experimental Protocol
Our training pipeline, integrated within the overall methodology shown in Figure 1, begins with formatting our QA triplets into a chat-completion format compatible with the Mistral API. The formatting mirrors instruction-following dialogues and helps align the fine-tuning process with how the model will be used in production.
In terms of training configuration:
- We used a Mistral 7B model as the base.
- Training was conducted over 3 epochs.
- The only tunable hyperparameters were the learning rate and number of steps; we kept the learning rate at its default value to maintain consistency across experiments.
4.2. Evaluation Methodology
To assess the effectiveness of our fine-tuned model, we created a manually curated evaluation set comprising 34 representative questions, each with:
- A validated expert answer,
- A reference to the source segments containing the required information.
This evaluation set spans a range of question types:
- Explicit (clearly stated),
- Implicit (requires inference),
- General vs Precise.
Similarly, the document segments retrieved for each question are categorized based on their informational quality—whether they contain direct answers, supportive context, or are irrelevant. For each question, we retrieve the top 5 most semantically similar segments using our internal retrieval system. These are then fed, along with the question, into the fine-tuned model following the same input structure as during training.
Each generated answer is manually assessed by a human expert using a rubric focused on the “Helpful, Honest, and Harmless” (HHH) criteria—an emerging standard in LLM evaluation.
4.3. Results & Insights
The fine-tuned Mistral 7B model demonstrated notable performance gains:
- The percentage of answers flagged as negative (incorrect or unsatisfactory) dropped from 35% with the baseline (vanilla) model to 18% after fine-tuning.
- For comparison, the best version of GPT-4 evaluated under the same conditions achieved a 10% negative rate.
These results confirm that our approach—using synthetic supervision derived from GPT-4 to fine-tune an open-source model—acts as a form of knowledge distillation, effectively transferring capabilities from a stronger model to a more lightweight one.
5. Future Work & Perspectives
Our initial results demonstrate the feasibility and value of synthetic fine-tuning for domain-specific LLMs. Building on this momentum, several promising directions are under active exploration to further improve model accuracy, robustness, and deployability:
5.1. Training Set Optimization via Topic Modeling
We are investigating topic modeling techniques to automatically cluster and analyze the content of our synthetic training data. This will allow us to:
- Detect and eliminate noisy or redundant samples,
- Ensure balanced representation across business-specific themes,
- Identify coverage gaps in underrepresented product areas.
This refinement step is critical to maximize the efficiency of the fine-tuning process and minimize overfitting on low-quality samples.
5.2. Scaling to Larger Mistral Models
While our initial experiments were conducted with Mistral 7B, we are planning to scale to larger-capacity models (e.g., Mistral 8x7B). These architectures:
- Offer higher parameter budgets to internalize more complex domain knowledge,
- Enable better generalization, especially for implicit or ambiguous queries,
- Allow the integration of more sophisticated fine-tuning schemes like Mixture-of-Experts (MoE).
This scale-up is expected to bring us closer to the performance of closed-source leaders like GPT-4, while retaining sovereignty and cost control.
These upcoming developments are part of a broader ambition: to design sovereign, adaptive, and reliable language technologies that meet the operational standards of real-world business environments. Our roadmap continues to bridge the performance gap between open and closed models—while maximizing control, explainability, and alignment with the needs of Berger-Levrault’s clients and users.
6. References
- Nguyen, T. et al. (2024). Efficient Language Models for Sustainable AI Deployment. arXiv:2501.01990
- Jegham, I. et al. (2025). Eco-Efficiency Benchmarking of Large Language Models. arXiv:2505.09598



