
Introduction
In modern software development, application reliability relies on effective testing strategies. Altough unit and integration tests secure internal consistency, functional testing remains essential for validating user-facing behaviors.
For large-scale applications like Alpha Tool, running thousands of functional tests is challenging: it consumes vast resources, slows down delivery, and complicates analysis.
This article explores the challenge of large-scale functional testing in Alpha Tool and shows how selecting only needed test can streamline PR validation, highlight coverage gaps, and optimizes resource usage.
Project stack and context
Functional testing in Alpha Tool relies on a combination of interconnected technologies. Alpha Tool itself is a web application developed in java composed of multiple modules and thousands of classes. User behavior and workflows are captured as BDD stories and scenarios, written in Gherkin syntax in a separate project. These stories are executed using JBehave, a Behavior-Driven Development (BDD) framework that drives Selenium to automate interactions with the application, eliminating the need for manual scenario recording. Each scenario step interacts directly with the application to validate behavior.
The Challenge: Scale, Workflow Bottlenecks, and Failure Analysis
Functional testing in Alpha Tool is limited by three main factors:
Execution Time
Running more than 3,000 functional stories sequentially on a modern workstation takes 48 hours, as shown in Figure 1. Sometimes, tests might fail due to failed steps, and a single failed step often skips the rest of the scenario, leaving gaps in validation. Whithout parallelisations, merging PR takes time because one need to wait for test to run for every PR.
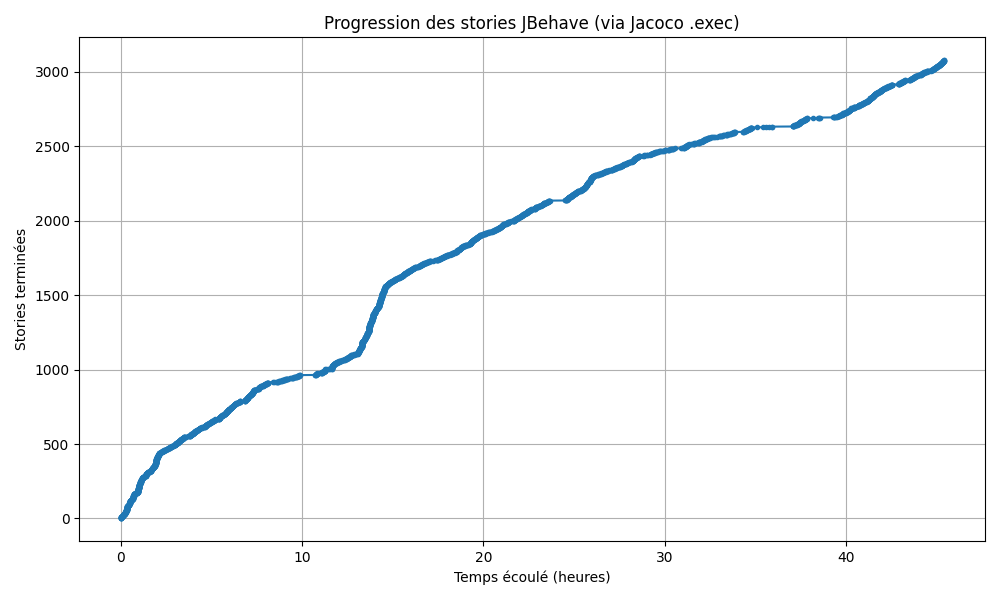
Release Workflow Delays
Long execution times become especially problematic during the PR workflow. With 20–30 PRs submitted daily, functional tests must run before merging, creating major bottlenecks, as illustrated in Figure 2. Even with partial parallelization, validation may take 8+ hours, consuming cloud resources and delaying developers and reviewers.
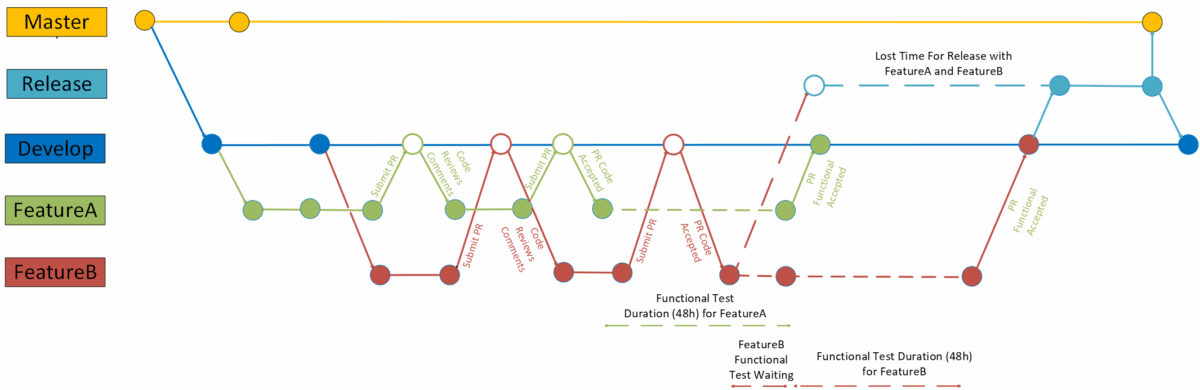
Summary of the Challenges: Running the full functional suite for every PR is inefficient and incomplete, too slow for continuous delivery and still leaving coverage gaps. It is necessary to be able to select only interesting test based on code changes in a PR.
Methodology: Pertinent Test Selection
Our approach focuses on executing only functional tests relevant to a given PR, while maintaining coverage awareness and optimizing execution time. The methodology consists of four integrated stages:
Step 1 – Collect Coverage Data
The first stage involves collecting detailed coverage data by executing functional test stories written in Gherkin syntax. These stories run sequentially via JBehave steps, which drive Selenium to interact with the application (Figure 3). To determine which classes are affected by each story, we use Jacoco in TCP mode. This configuration allows coverage counters to be initialized before the first story, updated continuously during execution, and exported into separate .execfiles after each run—functionality that the traditional Jacoco file mode cannot provide, as it only calculates coverage when the JVM process stops. Counters are reset between stories to ensure clean, precise per-story coverage, establishing a reliable foundation for the story-to-class mapping.

Step 2 – Build the Story ↔ Class Matrix
After collecting coverage data, it is converted to XML and analyzed to construct a bidirectional story ↔ class matrix. This matrix maps each story to the classes it affects and is version-aware, reflecting the state of the application at the time the feature branch is created. Serving as the primary reference for both test selection and coverage monitoring, the matrix enables precise identification of which parts of the application are exercised by each story. Figure 4 illustrate the sub-process.
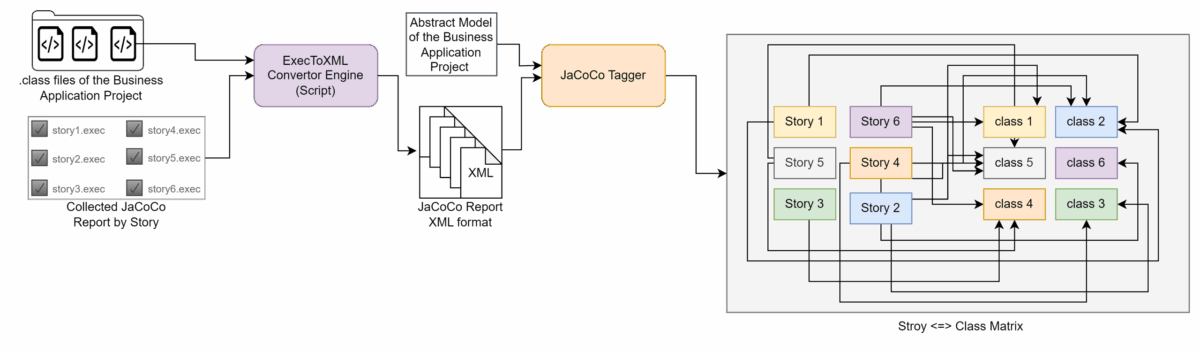
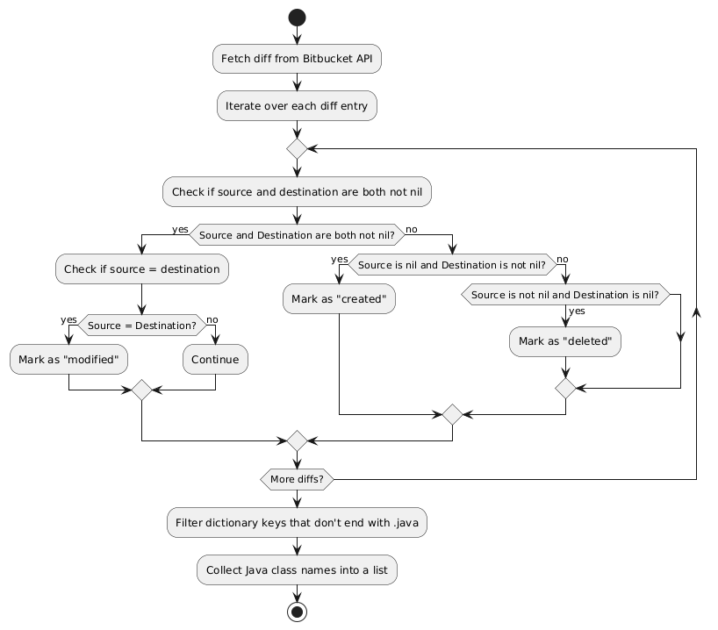
Step 3 – Analyzing PR Impact
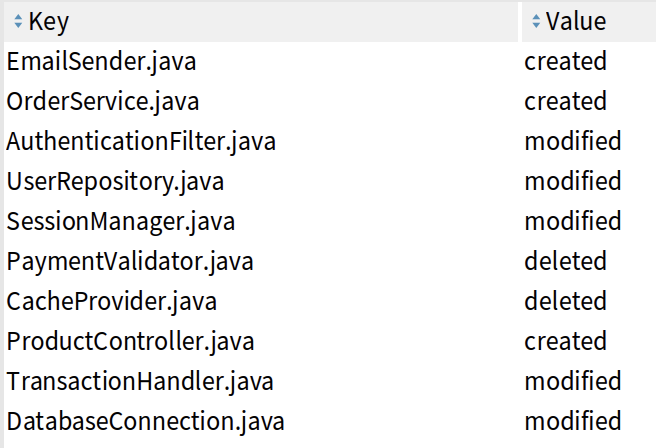
When a PR is submitted, we analyze its impact by extracting the list of created, modified, or deleted classes from the Bitbucket diff. This data is stored in a dictionary for fast lookup, allowing precise identification of which parts of the codebase are affected. A PR that modifies multiple classes can then be quickly matched against the story ↔ class matrix to determine which stories affect those classes, ensuring that only relevant tests are selected for execution.
Figure 5 illustrates the process of identifying impacted classes for a PR, while Figure 6 shows an example of the dictionary output, detailing each impacted class and its change status.
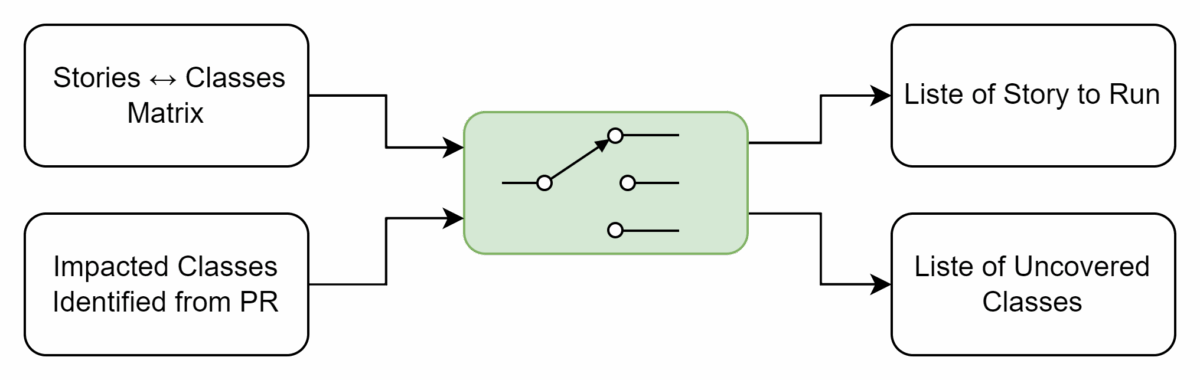
Step 4 – Select Stories and Track Gaps
By combining the story ↔ class matrix with PR impact data, we select only the relevant stories for execution. This approach speeds up PR validation, cuts down unnecessary test runs, and flags any classes that aren’t covered, helping teams quickly spot and address gaps.
Results: Impact of Pertinent Test Selection
Sample PRs – Detailed View
To illustrate the benefits of pertinent test selection, we analyzed a sample of concrete pull requests (PRs) from the Alpha Tool repository. These results demonstrate significant time savings while maintaining full visibility into coverage gaps.
Table 1. Execution Metrics for Sample PRs
| PR | Impacted Classes | Selected Tests | Exec. Time (h) | Time Saved(h) | Total Uncovered Classes |
|---|---|---|---|---|---|
| PR-1 | 28 | 129 | 2 | 46 | 27 |
| PR-2 | 0 | 0 | 0 | 48 | 0 |
| PR-3 | 3 | 88 | 1.5 | 46.5 | 2 |
| PR-4 | 6 | 831 | 13 | 35 | 2 |
| PR-6 | 30 | 3 | 0.5 | 47.5 | 29 |
| PR-7 | 26 | 3,078 | 48 | 0 | 22 |
The pertinent test selection approach links functional tests directly to the modified code within a PR, eliminating the need to execute the entire functional test suite for every submission.
In some cases (e.g., PR-2), no tests are executed because only non-Java files, such as HTML templates or configuration assets, were modified. In contrast, updates to core or foundational components (e.g., PR-7) can trigger thousands of tests due to their extensive dependencies across the codebase.
PRs that introduce a large number of new classes (e.g., PR-1 and PR-7) tend to show a higher number of uncovered classes, revealing gaps that may require additional testing effort. Even existing classes can occasionally appear as uncovered, highlighting potential areas for test improvement.
Overall, this selective testing strategy minimizes redundant executions, accelerates feedback loops, and ensures that each PR is validated at a level proportional to its scope and potential impact.
Full Queue Analysis – All 59 opened PRs
Overall Performance Metrics
To evaluate performance at scale, the same methodology was applied to all 59 open PRs in the validation queue.
Table 2. Overall Performance Metrics Across All PRs
| Metric | After | Before |
|---|---|---|
| Total Cumulative Story | 181,602 | 63,972 |
| Average Story per PR | 3,078 | 1,084 |
| Required Total Execution Time | 2832h | 997h |
| Time and Resources Reduction | __ | 65% |
These results confirm that pertinent test selection reduces overall execution time and resource consumption by approximately 65%, while maintaining full coverage visibility—even for large-scale systems. In practical terms, the same workload can now be executed 1 single virtual machine (VM) using the proposed approach, whereas the previous method required parallelization across 3 VM, achieving equivalent results with faster feedback.
Grouped Execution Scenario
In the analysis above (Table 2), tests are executed for each impacted story, even when multiple classes are affected by the same set of stories.
By grouping overlapping cases, for instance, when all 3,078 stories impact several classes, redundant test runs can be avoided, yielding additional efficiency gains.
This approach allows the validation of all PRs whose impacted classes share the same stories within a single execution window.
Table 3. Performance Metrics for Grouped Execution Scenarios
| Metric | Before | After |
|---|---|---|
| Total Cumulative Story | 181,602 | 14,724 |
| Average Story per PR | 3,078 | 342 |
| Total Execution Time | 2,832h | 229h |
| Time and Resources Reduction | __ | 92% |
This grouped execution scenario demonstrates that execution time and resource usage can be reduced by up to 92%, further highlighting the scalability and efficiency of the pertinent test selection approach for industrial-scale functional testing.
In practical terms, under equivalent conditions, the traditional testing approach would require approximately 12 additional virtual machines to achieve the same throughput.
Maintenance Strategy Over Time
The story ↔ class matrix is the backbone of our test selection methodology, but it must evolve with Alpha Tool and its BDD test suite.
- Incremental Updates: After each PR merge, story-class relationships are updated to reflect changes. A story may no longer cover certain classes, and new classes may appear without associated tests.
- BDD Project Incremental Updates: New stories are execute separately and linked to the classes they cover, while deleted stories and their associations are removed to maintain an accurate mapping.
- Abstract Model Recalculation: Periodically, or after major merges, the Alpha Tool abstract model is recalculated to remove deleted classes, incorporate new ones, and refresh all story ↔ class links.
- Batch Updates: Weekly, bi-weekly, or monthly batch updates act as a safety net, catching any discrepancies missed by incremental updates and refreshing metrics for reliable test selection and coverage monitoring.
By combining continuous incremental updates with scheduled batch refreshes, the matrix remains a trustworthy guide for efficient PR validation, even as the application and its test suite grow.
Conclusion
For large-scale applications like Alpha Tool, running the full functional test suite for every PR is impractical. Our pertinent test selection approach provides several key benefits:
- Faster PR validation – developers receive quicker feedback.
- Resource efficiency – fewer tests are executed per PR, saving time and computing resources.
- Coverage awareness – untested classes, redundancies, and skipped steps are clearly identified.
By combining impact analysis, selective execution, and detailed metrics, Alpha Tool is evolving toward a more efficient and adaptive functional testing process, supporting a faster, more reliable CI/CD pipeline and enabling secure, timely delivery.
Acknowledging Contributors : Quentin Capdepon, Christophe Maussier, Nicolas Hlad, Benoit Verhaeghe, Olivier Gatimel, Olivier Debuyzer, Gilles Guyollot, Xavier Griffon.



