
Adherence to legal mandates is crucial for businesses, as failure to comply can lead to substantial penalties. In an environment where legal documents are constantly evolving, companies increasingly rely on automated processes to streamline analysis and to ensure ongoing compliance. The full automation process typically involves: (1) extracting legal terms and their relationships, and (2) formalizing these extractions into a structured model. In this paper, we introduce Scribe, an open-source web tool designed to extract and formalize legal rules. Scribe merges previous research on legal term extraction and rule formalization, leveraging Large Language Models (LLMs) to initiate extraction from untrained domains before refining the output with a BERT classifier. The extracted information is then structured in a graph database using a semantic model. Scribe facilitates the automatic extraction of legal rules while reducing the need for expert involvement, allowing legal professionals to focus on more complex, high-value tasks.
Introduction
The legal industry is characterized by a vast and continuously evolving document, including contracts, legislation, court rulings, and regulatory filings. These documents are dense, complex, and rich in specialized terminology, making their analysis and processing both time-consuming and susceptible to human error. Automated processing of such documents is essential for various applications, such as legal research, compliance monitoring, and contract analysis. Automation not only accelerates the analysis process but also enhances compliance, accuracy, and accessibility of legal information. Furthermore, as laws and regulations are frequently updated, automated systems ensure that analyses remain current with the latest legal standards. Compliance with the law is mandatory for companies, and failure to do so can result in severe penalties. As emphasized by Sassier et al., the legal landscape in France alone includes “more than 10,500 laws, 120,000 decrees, 7,400 treaties, 17,000 community texts, and tens of thousands of pages across 62 different codes, with some being modified as frequently as six times per working day in the 2006 Tax Code.”
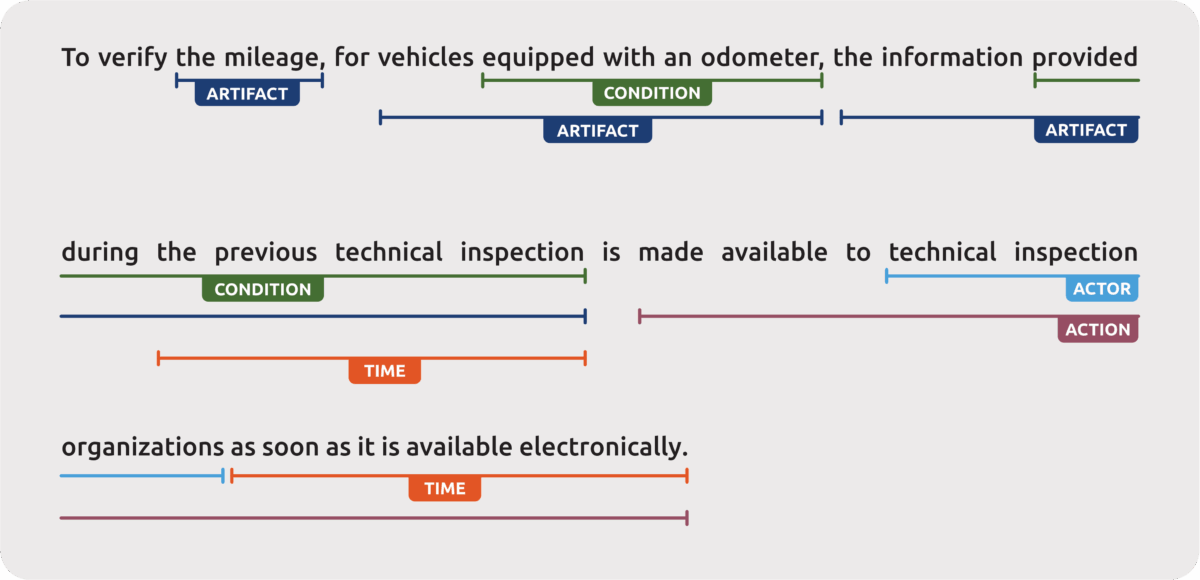
The backbone task for the automation of legal rules relies on formalizing them in a structured manner. Therefore, two primary tasks can be identified: the extraction of legal entities and the extraction of relations between these entities. This paper focuses on the extraction of legal terms, as illustrated in the previous figure from the Luxembourg traffic law, highlighting the multi-class and multi-label task.
Our objective was to develop a web tool, Scribe, aimed at extracting and formalizing legal rules from raw documents, with an initial focus on legal term extraction. This article outlines prior research and the methods used to integrate these findings into Scribe. The first step involves using SEMLEG, our semantic model, to formalize legal rules. The second step involves the pipeline, which trains BERT models on datasets generated by LLMs and refined through rule-based methods. This approach lays the groundwork for full automation of legal rule extraction, minimizing expert involvement while enhancing the interpretability of the results, thereby offering clearer insights into the extraction process and the structure of the training dataset.
Previous works
We present our previous research efforts that laid the foundation for the development of Scribe. First, we describe the creation of a semantic model (SEMLEG) aimed at storing and formalizing legal rules. Then, we outline the zero-shot extraction pipeline for legal terms.
Formalizing Legal Rule with SEMLEG
Before extracting legal terms, it is essential to identify the structured formalization. The state-of-the-art presents various approaches, including legal programming languages and semantic models, as outlined extensively in our previous paper presented at the Semantics 2024 conference.
While legal programming languages, like PROLEG or Catala, enable compliance computation out-of-the-box, we opted for the semantic model due to its explicitness for non-experts and modularity. Reducing the need for expert involvement leads to enhanced input quality. As a result, the semantic model is more accessible for experts to handle, comprehend, and modify.
Our article in Semantics 2024 provides an in-depth study of SEMLEG, including the eight legal concepts, which are redefined in the following table. These concepts form the core elements we aim to extract and represent the primary focus of this study. In their work, Sleimi et al. compiled a set of semantic models for legal applications and proposed a unified version, which we partially adopt and build upon in this research.
| Concept | Definitions |
|---|---|
| Action | the process of doing something |
| Actor | an entity that has the capability to act |
| Artifact | a human-made object involved in an action |
| Condition | a constraint stating the properties that must be met |
| Location | a place where an action is performed |
| Modality | a verb indicating the modality of the action (e.g may, must, shall) |
| Reference | a mention of other legal provision(s) or legal text(s) affecting the current provision |
| Time | the moment or duration associated with the occurrence of an action |
Zero-Shot Legal Term Extraction
In this section, we examine the pipeline implemented in Scribe, illustrated in the next figure, and its capability for zero-shot legal term extraction. As detailed in our previous article, we utilize LLMs to generate the training dataset, which is then refined through a filtering process and distilled into a BERT model. This approach enables term extraction in untrained domains with minimal expert involvement, addressing the challenges posed by the lack of annotated datasets and the time-consuming nature of traditional state-of-the-art methods.
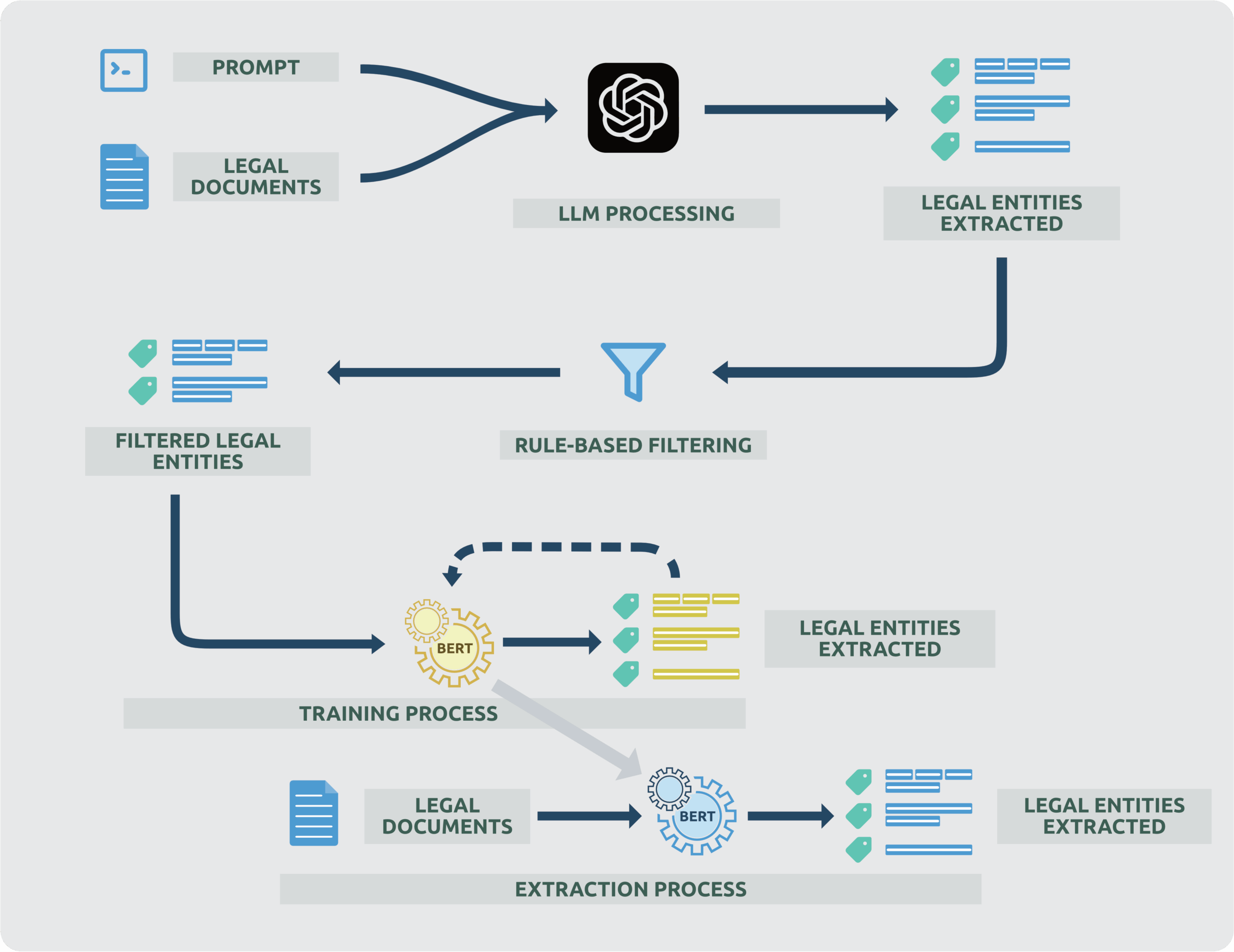
Initially, experts craft a prompt that includes concepts, their definitions, and an example of the expected outcome from a sentence. Subsequently, the LLM performs the extraction using both the provided prompt and the legal documents. The output consists of the legal concepts extracted by the LLM. Following the extraction with GPT-4, we refined the extracted concepts using a rule-based strategy. We aim to enhance the precision of the LLM by incorporating syntactic rules developed by experts. For instance, all artifact concepts can be identified as Noun Phrases (NP), while actions can be identified as Verb Phrases (VP). By applying these syntactic rules, we can tackle the boundary issue and ensure that the extracted entities are both precise and complete. After refining the legal entities with the rule-based approach, we use these legal entities to train the BERT classifier. Upon completing this training phase, the model is ready to perform extractions on incoming documents. By distilling the knowledge from an LLM into a BERT model, we achieve a balance between leveraging advanced AI capabilities and ensuring practical, interpretable, and scalable solutions for industrial applications. This hybrid approach allows us to harness the strengths of both models, resulting in an efficient and effective system for legal entity extraction. This approach is detailed in the following section.
Scribe
We developed Scribe : an open-source tool to implement and extend our research, facilitating a smoother transition from research to practical application. In this way, this section dives deep into the different aspects and capabilities of Scribe, illustrated in the next figure.
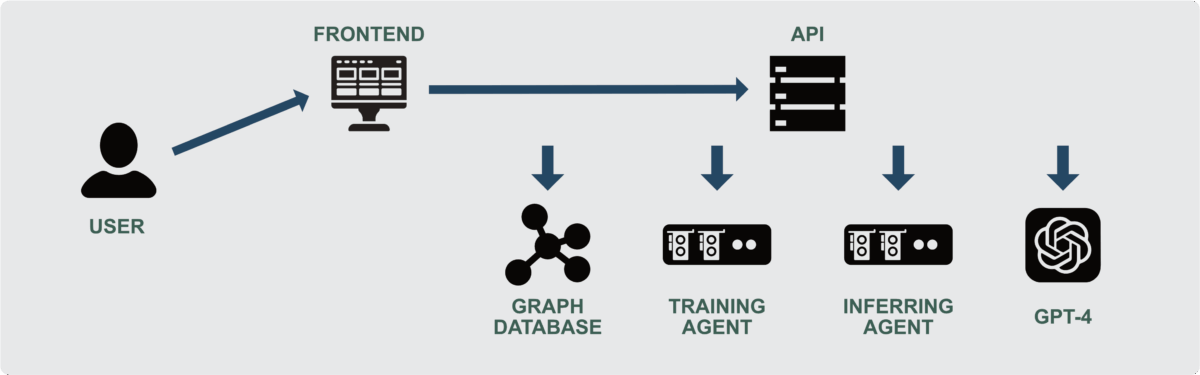
Building upon the pipeline outlined in the previous section, we developed an Application Programming Interface (API) to handle and orchestrate user requests across external systems, including the graph database, training agent, inference agent, and GPT-4. While the frontend offers an accessible solution for non-expert users to insert and retrieve information via a web interface, the API is designed for more advanced use cases.
To begin using Scribe, a document must be submitted either via the interface or API endpoints. Upon receiving this request, Scribe initiates its pipeline by parsing the document using SpaCy to generate Part-of-Speech tags, Lemmas, Dependencies, and Constituents. The parsed document is then added to the Neo4j graph database, adhering to SEMLEG, our semantic model.
Once the document is stored, Scribe proceeds with term extraction based on the current configuration. In bootstrapping mode, Scribe leverages the GPT-4 API to perform initial extractions. At this point, users can extract preliminary annotations and modify them using external tools like Doccano. After any necessary revisions are made, users can initiate fine-tuning of the BERT model for improved performance.
Thanks to Scribe’s microservice architecture, GPU instances can be deployed on demand for training tasks. The API transfers all training data to the training agent, which processes the task before publishing the final model on Hugging Face. The user can then switch to using the inference agent, replacing GPT-4, to perform legal term extraction with the fine-tuned model. The training process can, of course, be repeated after expert intervention to update the model. This iterative approach allows for continuous refinement based on expert feedback, ensuring that the model remains accurate and up-to-date.
Conclusion
Scribe is an open-source tool designed to extract and formalize legal rules from raw documents. In this initial version, we have established the core functionality for entity extraction while minimizing the need for extensive knowledge input and expert involvement. In future work, our goal is to develop the next component: the extraction of semantic relations between legal terms. Achieving this milestone will provide us all the necessary components to generate formalized legal rules. Consequently, we will be able to establish a pivotal system connecting the semantic model to domain-specific languages (DSLs).



