
The extensive use of Large Language Models (LLMs) for summarization tasks brings new challenges. One of the most important is related to the LLMs’ tendency to generate hallucinations, i.e., texts that give the impression of being fluid and natural, despite their lack of fidelity and nonsensical nature. Hallucinations can be factual: a source of knowledge, such as an expert, an ontology or a knowledge base, can indeed certify their veracity.
Most of the current works on hallucinations aim at deleting, reducing or correcting non-factual hallucinations through dedicated models or post-processing approaches. Another line of work also tries to control factual hallucinations through the use of external knowledge, while keeping low the number of non-factual hallucinations. This last line of research is particularly of interest while considering specific domains such as the legal field. Indeed, summaries of legal documents written by experts often contain contextual information as well as former laws that help the readers to fully understand them. This is illustrated in Figure 1 through an example of legal document with its associated reference summary, extracted from the EUR-Lex-Sum dataset.

Figure 1: Example of EUR-Lex-Sum legal document with its reference summary (excerpts) produced by experts. Law entities are marked in bold, abstractive entities of the reference summary are colored: blue ones are present in the dataset (in-dataset entities) whereas the red one is an out-dataset entity.
In this example, we focus on entities of interest (in bold). The reference summary mentions laws Regulation 2019/979, Regulation 2020/1273, and Regulation 2020/1272 (colored in blue or red on Figure 1) that do not appear in the source document. Such entities of interest have been added to the summary by experts in order to track all the amendments made to the Regulation 2019/980 presented in the document. They are named abstractive entities, in opposition to extractive or faithful entities. Abstractive entities, as they are written by experts, are de facto factual. Figure 2 proposes a taxonomy of the different types of hallucinations and abstractions, and summarizes all definitions.
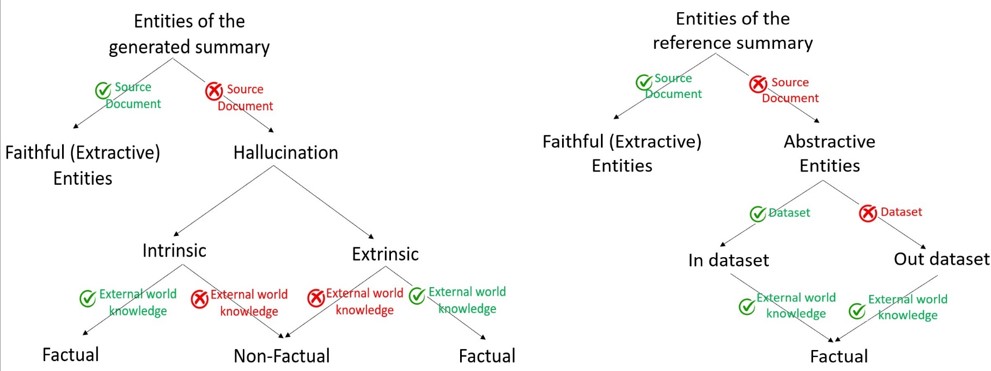
Figure 2: Taxonomy of entities of interest in the generated summary and reference summary.
In this article, we focus on abstractive summarization of legal documents, with the main objective to produce enriched, useful, and factual summaries which will lighten the task of information monitoring by legal experts. To do so, we aim at controlling factual hallucinations by knowledge arisen from the source dataset. In other words, we propose approaches which aim at fulfilling a two-objectives task: (1) retrieve factual hallucinations, i.e., the abstractive entities written by experts in reference summaries; and (2) keep very low the number of non-factual hallucinations.
Legal Summaries Specificities
Our aim here is to study the characteristics of reference summaries in terms of entities of interest as well as abstractions. To this end, we analyzed two legal datasets for summarization: EUR-Lex-Sum and our corpus Légibase. The EUR-Lex-Sum dataset comprises 1 504 documents, retrieved using web scraping from the Europa European law platform text website. We also used Légibase, a private business dataset of Berger-Levrault composed of 8 485 legal and regulatory documents for French local authorities and public administrations.
Figure 3 presents the distribution of entities of interest (i.e., Law, Organization, Location, and Person) across the datasets. As legal entities are written in very specific and repetitive patterns, we used a set of regex to extract them from the text. All other entities were extracted using a NER model fine-tuned on the Indian Court Judgements dataset. We can see from the histograms that legal entities are, not surprisingly, by far the most present, both in source documents and in reference summaries. They are followed by the Organizations and Locations, which are present in roughly equivalent numbers. Finally, Persons are barely present in the reference summaries of EUR-Lex-Sum.
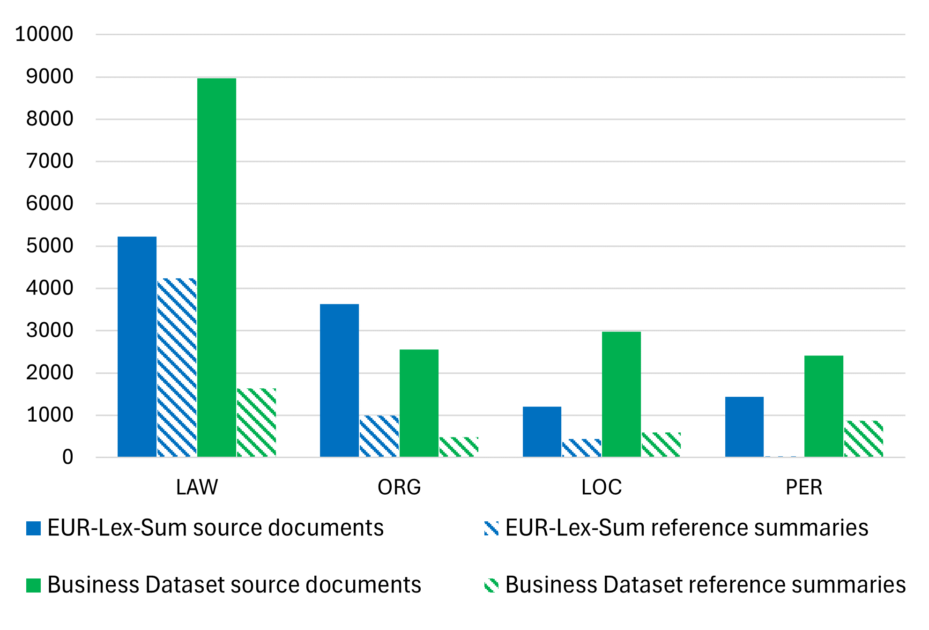
Figure 3: Distribution of the entity types across source documents and reference summaries in the two datasets: EUR-Lex-Sum and French Law Dataset. Distinct occurrences are considered.
Abtractiveness of Reference Summaries
Table 1 shows an analysis of faithful entities (Fri ), as well as in-dataset and out-dataset abstractive entities (Ainri and Aoutri). We observe that a large proportion of the entities present in the summaries are abstractive, 66% and 68% for the EUR-Lex-Sum and Business dataset (Légibase) respectively. This confirms our initial hypothesis and shows that legal experts rely heavily on their external knowledge when writing summaries, in order to contextualize the main entities of the source document and provide a history of them. This external knowledge may or may not be found in other documents in the dataset, as we can see from column Ainri and Aoutri.

Table 1. Total number of faithful and abstractive entities in the reference summaries of the EUR-Lex-Sum and Business datasets. The average number of entities per reference summary is also reported.
Experiments
1. Impact of abstractive entities
As introduced previously, our aim is to see if giving abstractive entities to the summary generation model leads to better summaries in terms of factual hallucinations, without losing the faithful entities.
During training, we fine-tune the summary generation model by providing it the source document as an input and the set of abstractive entities of the reference summary Ainri. The same configuration was used at inference. These summaries can be considered as Oracle summaries, i.e., the best possible summaries that can be obtained by our approach. More precisely, we prepend the set of entities to the source document, using the special token [ENTITYSET] to introduce the entities and separated them with the token (character here) | The source document was introduced using the special token (character here) [DOCUMENT]. For the EUR-Lex-Sum dataset, we consider the 3 entity types: Law, Organization and Location. Person entities were removed since they are not present in the reference summaries (see Figure 3). The 4 entity types were used for the Business dataset.
2. Realistic Setting
In contrast to Experiment 1, in real-life scenarios, the abstractive entities appearing in the reference summaries are not known. Since some abstractive entities are present in the dataset, our aim here is to retrieve them in order to give them to the model at inference.
- Retrieving abstractive entities: We propose to construct two graphs containing respectively the sets of training and inference entities. GDT, Entity Graph of the train dataset (an example of which is shown in Figure 4) is constructed as follows (bearing in mind that the construction of GDI is similar). GDI : Entity Graph of the inference datatest.
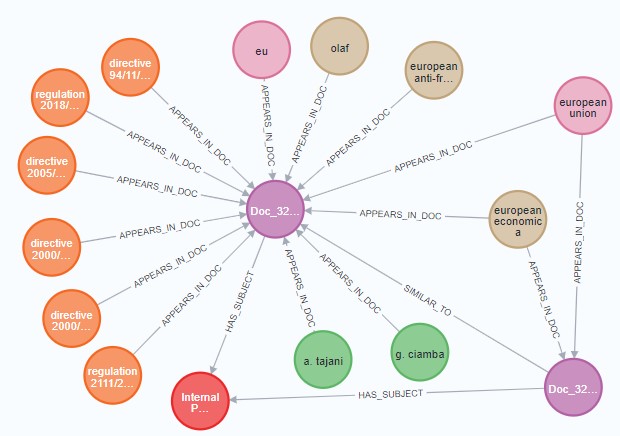
Figure 4: Extract of GDT for the EUR-LEx-Sum dataset. Nodes represent Documents (purple), Law Entities (orange), Organization entities (brown), Person entities (green) and Subjects (red). As can be seen, the two documents are semantically close and share the same subject ‘Internal Market’. They also share the same entity named ‘European Economic Committee’.
– The nodes of GDT include (1) the documents di ∈ DT , (2) the entities Edi of each di, and (3) the subject of di.
– The edges represent (a) the similarity between documents, evaluated with a cosine similarity between embeddings of documents, (b) the presence of an entity in a document, and (c) a link between a document and a subject.
Once the graphs are created, we tried different entity selection strategies and measured the intersection of their results with the set of abstractions in the reference summaries. The idea is, for each document di, to retrieve entities from related documents, according to 4 strategies (S):
– (S1) For the first strategy, we extract entities connected by a maximum of 1, 2, or 3 hops to di;
– (S2) For the second strategy, we extract entities of documents sharing the same subject than di;
– (S3) For the third strategy, we extract entities of documents being semantically similar to di;
– And finally, (S4) for the fourth strategy, we extract entities of documents sharing the same subject than di and being semantically similar to di.
Fine-tuning
Setting 1: For the training phase, we provided the model with the source document di and the Ainri set. During inference, we concatenated the source document and 20 entities of the strategy1 (S1).
Setting 2: During training, the model receives the source document, prepended by 20 entities from Ainri completed by some randomly chosen entities of strategy S1. For inference, only the source document and the entities of S1 are provided.
Setting 3: During training, the model receives only the entities of S1 set and the source document. For inference, the same elements were provided.
Our Results
We used the following systems for comparison with our approach:
– ECC is a model training approach for improving the factuality of generated summaries based on the coverage metric;
– CTRLSum is a training approach to guide the model to include a set of pre-selected keywords and entities in the generated summary; and
– Mixtral 8*7B is a LLM, chosen to compare the experiments conducted with PLMs (Pretrained Language Models) against a LLM without fine-tuning.
For our experiments, we have the following Research Questions (RQs):

Table 2. Summary table of all the experiments conducted
The evaluation metrics we use refer to Faithfulness rate (F), Coverage entities (C), Factual Hallucination entities (F), Rouge-L and Bleu.
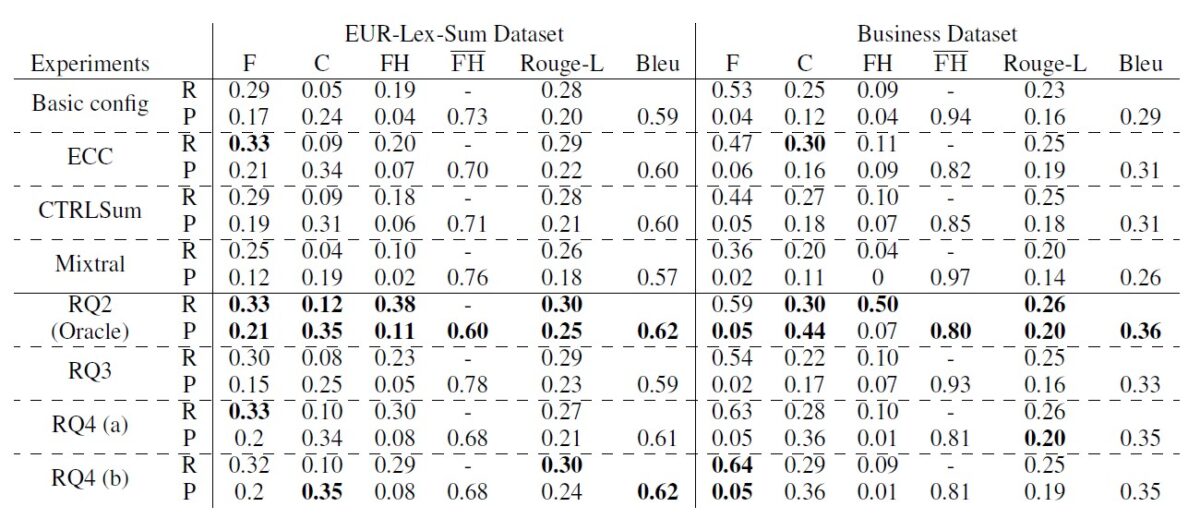
Table 3. Baselines, Oracle and models results.
In this article, we show that legal summaries are written in a specific style, requiring an adaptation of state-of-the-art summarization approaches. We also introduce a new approach for injecting abstractive entities into the model using different configurations. Our experiments on 2 different datasets show that this method significantly reduces non-factual entity hallucinations while increasing coverage metrics and factual hallucinations in the generated summaries.



