Démonstration: L’Intelligence Artificielle et la Recherche d’Information au service de BL.ActesOffice
Le module présenté dans cette démonstration permet de rechercher des documents sur une partie de la base d’ActesOffice en se basant sur des techniques appartenant au domaine de l’intelligence artificielle (IA), du traitement automatique des langues (TAL) et de la recherche d’Information (RI). Ces trois domaines scientifiques et technologiques ont beaucoup en commun : ils traitent tous du texte exprimé en langue naturelle.
La représentation des documents au sein d’un système de RI et le calcul de similarité entre ces représentations sont deux problématiques différentes que nous avons traitées dans ce projet de recherche et développement.
Afin de donner une représentation sémantique aux documents qui porte leur sens, nous nous sommes basés sur un modèle de langage entraîné sur un corpus de taille très importante provenant du domaine .fr (pour plus de détails, voir la section Description de l’approche). Ce même modèle a été utilisé pour donner une représentation sémantique à la requête; quand à la mesure de similarité utilisée pour comparer la représentation de la requête aux représentations des documents, nous avons utilisé la mesure Cosinus.
Description de l’approche : vers une recherche de documents par similarité sémantique et utilisation des plongements lexicaux (word embeddings)
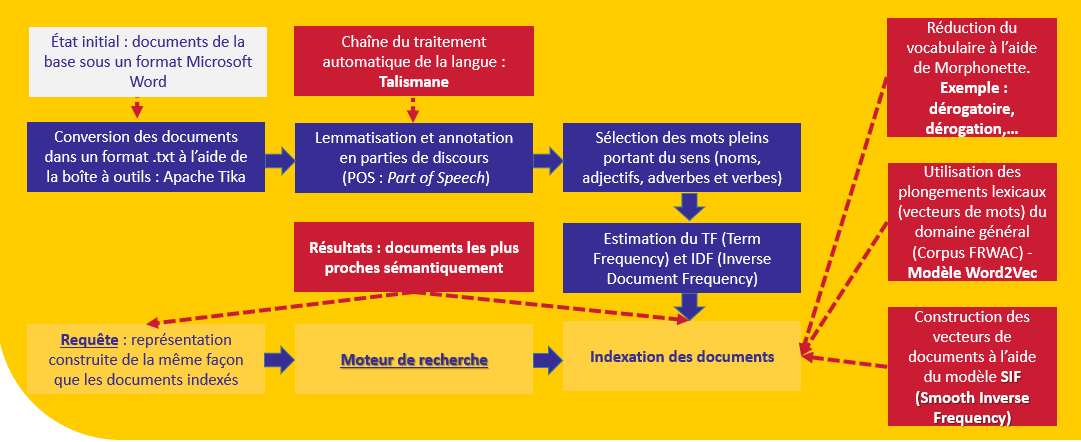
Les documents de la base sont tout d’abord indexés avec une représentation permettant de mesurer leur rapprochement avec la requête. Notre objectif principal est de donner du sens au contenu textuel exprimé dans ces documents.
Plusieurs ressources sont utilisées pour y arriver à cette indexation :
Systèmes proposés
Le modèle de langage que nous avons utilisé (à savoir, Word2Vec avec une architecture CBOW – Continuous Bag-of-Words) a été entraîné sur le corpus frWaC (corpus français du domaine .fr). Ce corpus contient près de deux milliards de mots. Nous avons utilisé le modèle Word2Vec proposé par Jean-Philippe Fauconnier (lien d’accès).
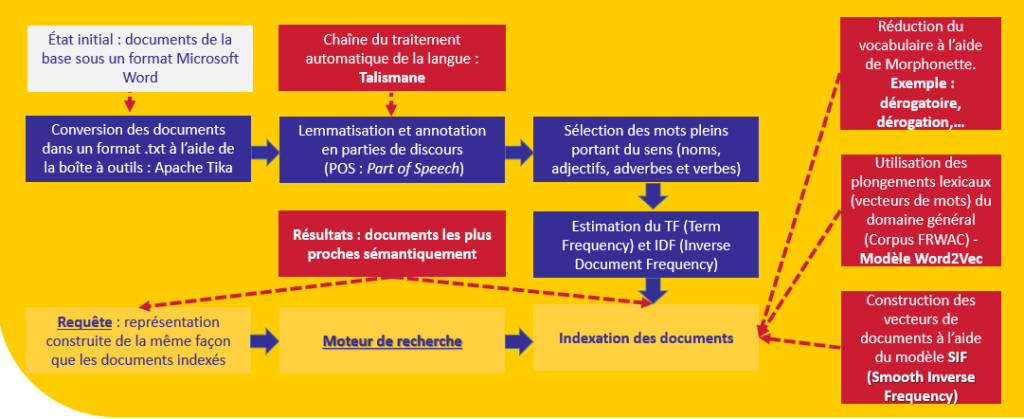
Il se peut que le modèle utilisé ne propose pas une représentation pour les mots exprimés dans la requête :

Types de requêtes
Nous proposons deux manières d’intérroger la base :
- Seulement les mots de la requête originale sont pris en compte pour intérroger la base,
- Nous prenons en compte non seulement les mots de la requête originale mais aussi les trois mots les plus proches sémantiquement à chaque mot de la requête originale.
Comment ça marche ?
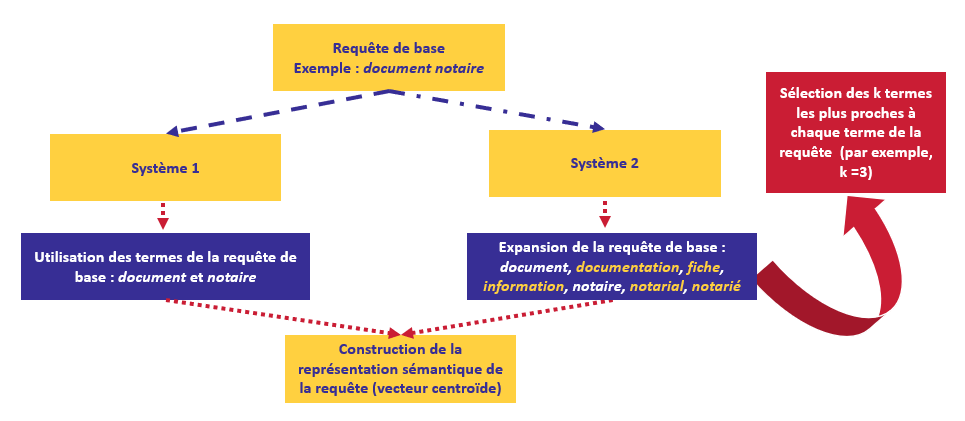
L’utilisateur doit fournir sa requête dans le champ de recherche et le type de cette requête (simple ou étendu).
Si le type choisi pour la requête est simple alors la représentation de la requête tient compte uniquement des mots exprimés par l’utilisateur. Dans le cas contraire, si le type est étendu alors des mots sémantiquement proches sont rajoutés à la requête initiale.
Par exemple, si la requête initiale est Entreprise travaux publics, la requête étendue est exprimée comme suit : entreprise, public, travail, chantier, collectivité, pme, pme-pmi, priver, professionnel, salarié et territorial.
Le résultat de la recherche est représenté sous forme d’un tableau permettant de réaliser différentes manipulations (tri, filtre, par exemple).
Ce tableau contient quatre colonnes, à savoir :
- Rang du document : les documents sont triés selon le score de similarité sémantique (exprimé en score de confiance),
- Score de confiance : il exprime le rapport entre le score de similarité sémantique du premier document (le premier du tableau) et le score de similarité du document à traiter,
- Premières lignes : un premier fragement de texte du document à traiter,
- Texte intégral : un lien pour consulter le texte dans son intégralité.
Si l’utilisateur souhaite rechercher exactement une chaîne de caractères dans la base, il peut l’entourer avec des guillemets (soit « et », soit “ et “).
Contact
Mokhtar Boumedyen BILLAMI (E-Mail : mokhtarboumedyen.billami@berger-levrault.com)
Christophe BORTOLASO (E-Mail : christophe.bortolaso@berger-levrault.com)



