
In his previous article, Romain explored the theoretical foundations and methods dedicated to the automatic evaluation of artificial intelligence systems, emphasizing the importance of making them more human and intuitive. This article continues this reflection by focusing on the practical applications of these advances. How are these innovations deployed? What challenges do they face? What are the prospects for making AI evaluation even more reliable and faithful to human experience?
1. Innovation Frontiers: Advancing Towards Contextual Human-Like Evaluation
To bridge the gap between automated and human evaluation, innovation in AI assessment is evolving along two key axes:
- Simulating human evaluators by modeling their judgment and decision-making processes.
- Decomposing evaluation criteria and constraints to create a structured and analytical approach.
1.1. Decomposing Evaluation: A Criteria-Based Approach
Rather than relying on broad, subjective assessments, the evaluation process is broken down into key dimensions that mirror human judgment, including:
- Completeness – Does the response cover all necessary aspects of the query?
- Conciseness – Is the information delivered efficiently without unnecessary verbosity?
- Context adherence – Does the response align with the specific business context or domain?
- Relevance – How well does the output address the user’s intent and needs?
By structuring the evaluation around these criteria, we can pinpoint weaknesses in generated responses and create a more actionable feedback loop for continuous model improvement.
1.2. Operationalizing Evaluation: The Role of User Mapping
To translate evaluation into a practical and scalable framework, these criteria are integrated into a user interaction map, which defines:
- Evaluation Workflow: When and how assessment questions should be asked to ensure timely and relevant insights?
- Stakeholder Roles: The involvement of key professionals, such as:
- Prompt Engineers – refining inputs to optimize model responses.
- Fine-Tuners – adjusting model weights and parameters based on evaluation feedback.
- Developers/Data Engineers – integrating evaluation mechanisms into broader AI pipelines.
- Automation Integration: Implementing structured reasoning techniques like:
- Chain of Thought (CoT) – breaking down reasoning into interpretable steps.
- Tree of Thought (ToT) – exploring multiple reasoning paths to enhance evaluation depth.
1.3. Towards a More Adaptive and Context-Aware AI Evaluation
By advancing towards contextual and structured human-like evaluation, organizations can refine AI assessment methods to ensure accuracy, relevance, and practical applicability. This approach not only enhances trust and reliability in AI systems but also facilitates seamless integration into enterprise workflows, enabling AI models to evolve dynamically in response to real-world requirements.
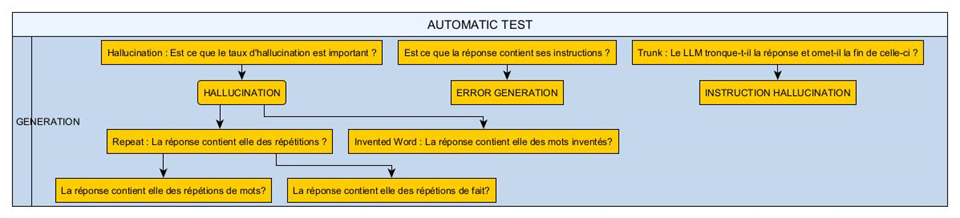
2. Practical Applications
Our approach to adaptive and context-aware AI evaluation is designed to be versatile and applicable across multiple domains.
2.1. Enhancing Prompt Engineering
Prompt engineering requires continuous iteration and refinement to ensure that AI-generated responses remain coherent, relevant, and aligned with the intended request. However, this process presents a key challenge: optimizing one type of response may inadvertently degrade another, making it difficult to achieve consistent improvements across all scenarios. To mitigate this issue, an automated evaluation platform can systematically track and measure potential regressions, identifying trade-offs between different prompt optimizations. By doing so, it minimizes the reliance on exhaustive human validation at each step, streamlining the iterative fine-tuning process while ensuring sustained response quality.
2.2. Optimizing Fine-Tuning for Domain-Specific Adaptation
Fine-tuning an LLM for a specialized use case requires continuous monitoring to ensure that training modifications lead to tangible improvements without unintended trade-offs. Each adjustment in the model’s training process can impact response quality, making systematic evaluation essential to maintaining performance. An automated evaluation framework enables real-time assessment of the model’s responses, ensuring they remain accurate, relevant, and contextually aligned with the intended domain. This approach not only streamlines the fine-tuning process but also helps prevent regressions, allowing AI models to adapt effectively while preserving high-quality outputs.
2.3. Developer & Data Engineering Impact: Ensuring Robust Preprocessing
Engineers working on document segmentation, data preprocessing, and pipeline optimization play a crucial role in shaping the input data that LLM process. Any modification to these upstream tasks can significantly influence the quality, coherence, and relevance of the model’s responses. To mitigate unintended consequences, automated quality assessment tools can provide real-time feedback, helping engineers to:
- Detect potential degradations in response quality caused by data transformations;
- Validate whether preprocessing changes enhance or hinder model performance;
- Ensure that adjustments align with business rules, domain-specific requirements, and overall LLM reliability. By integrating automated evaluation early in the development cycle, engineering teams can proactively identify and resolve issues, reducing the risk of costly regressions while improving data consistency and model effectiveness.

2.4. Project & Product Management: Aligning AI Evaluation with Business Goals
For project and product managers, reliable quality metrics are essential to assess how effectively an LLM responds to user queries. These insights drive strategic decision-making, ensuring that the model aligns with both user expectations and business objectives.
In large-scale industrial projects, the ability to rapidly iterate across diverse use cases and datasets is critical. Automated evaluation serves as a key enabler, either augmenting or replacing manual assessment, which is often time-consuming and prone to bias. By integrating automated quality checks, managers can accelerate deployment cycles, maintain consistency in model performance, and ensure that AI-driven solutions remain adaptable to evolving business needs.
Conclusion: Towards a More Reliable and Scalable AI Evaluation Framework
Scientific and Technological Perspectives
The ultimate goal is to develop an evaluation framework that closely mirrors human judgment, even in complex domains with diverse requirements, such as technical, legal, and administrative fields.
By leveraging a criteria-based evaluation approach, we can systematically analyze each aspect of a response, generating quantifiable scores and actionable alerts to assess performance more precisely. This structured methodology ensures that AI-generated outputs meet high standards of accuracy, relevance, and domain-specific compliance.
Product Vision at Berger-Levrault
The ambition is to provide a comprehensive platform and toolset for automated AI evaluation across a wide range of use cases. Beyond enabling continuous improvement, such a solution plays a crucial role in:
- Benchmarking new AI models to assess their capabilities in real-world scenarios.
- Refining fine-tuning strategies by identifying optimization opportunities.
- Validating prompt modifications efficiently, reducing the need for manual intervention.
By offering a global view of model performance, this approach helps pinpoint areas requiring improvement, ensuring that AI-driven systems consistently meet business and user expectations.
Future Directions
The development of a human-like automatic evaluation framework is strategically significant for both the enterprise and the broader AI community:
- For businesses, it enables a flexible, scalable, and adaptive evaluation system that aligns with real-world applications and industry-specific requirements.
- For the AI research community, it introduces a reproducible, context-aware evaluation framework, offering a more relevant alternative to traditional, generic NLP metrics.
By structuring evaluation around well-defined criteria and developing robust auto-evaluation tools, this approach reduces reliance on human evaluation while enhancing consistency, scalability, and quality in LLM and RAG-based systems. It represents a significant step forward in making AI evaluations more reliable, efficient, and sustainable, ultimately fostering greater trust in AI-driven decision-making processes.



