
Traditionally candidates for municipal elections prepare a program including various objectives they undertake to achieve if they are elected. The last French Municipale Election made no difference despite the quite particular context of execution of the 1st round due to the sanitary crisis.
Hence, we used this period to gather data that could help Berger-Levrault in understanding some specific trends. Our objective was twofold:
- Gather data on the web related to candidates programs for the 2020 french municipalities election
- Analyze this data to determine which candidate proposes actions in terms of participative democracy, establishing tendencies on ambition level, size of the town, political affiliation, etc.
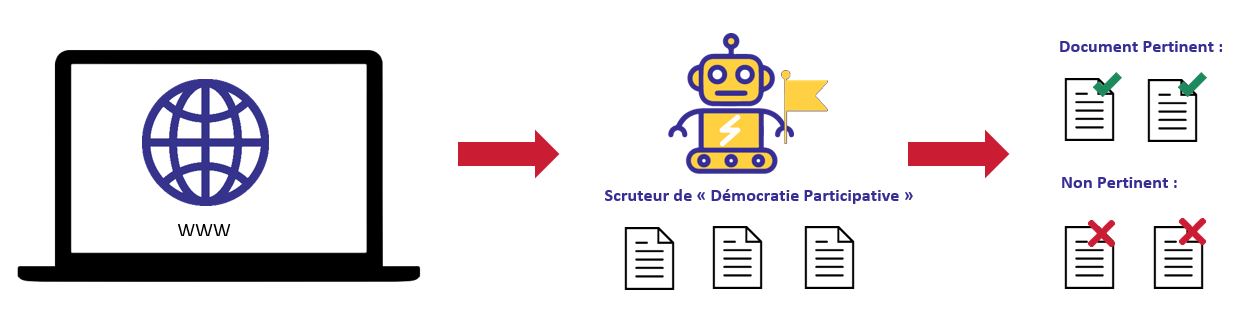
Such data could help us in identifying precisely which candidates have intentions in terms of participative democracy to constitutes a prospects base. We relied on two technologies to resolve these objectives: Web Scraping to collect data and Natural Language Processing to extract valuable information from it.
Step 1: I scrap, you scrap, he scraps…
To fulfill our objectives, we had to collect the data that would be used in order to draw a profile for each candidate’s program. We used web scraping techniques to collect data on the web. It is a process that browses the source code of a web page (HTML) and relies on its structure to automatically find the contained relevant information. A large diversity of tools are available for web scraping, we used two Python libraries: BeautifulSoup and Selenium.
First, we scraped governmental websites to gather data on the candidates and the municipalities. This helped us generate a database containing for each candidate his name, the name of his list, the associated town (with its name and size), and his political affiliation. Then, we gathered all the programs we could find in their PDF format, extracting the contained text to be analyzed by NLP in the second part of this project. These programs were found on different sources such as the website Calameo.
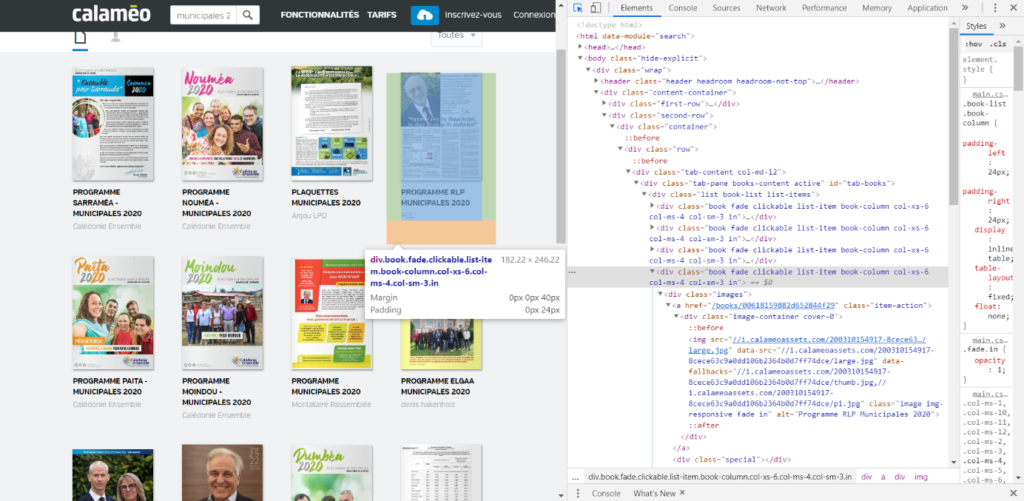

To complete these programs, we scraped Google News to find all the articles in the newspapers mentioning the candidates and subjects around participative democracy. The main issue we faced with this automatic collect for a great number of candidates (more than 30’000 towns in France) is the lack of visibility on the quality of the data (programs and articles) we were collecting. We reduced the number of candidates by removing the towns with less than 5’000 citizens and we dealt with the issue of quality by applying a filter on data according to their textual content. In the end, we obtained 2’396 programs of candidates for 1’686 different towns.
Step 2: Invoking the power of Natural Language Processing
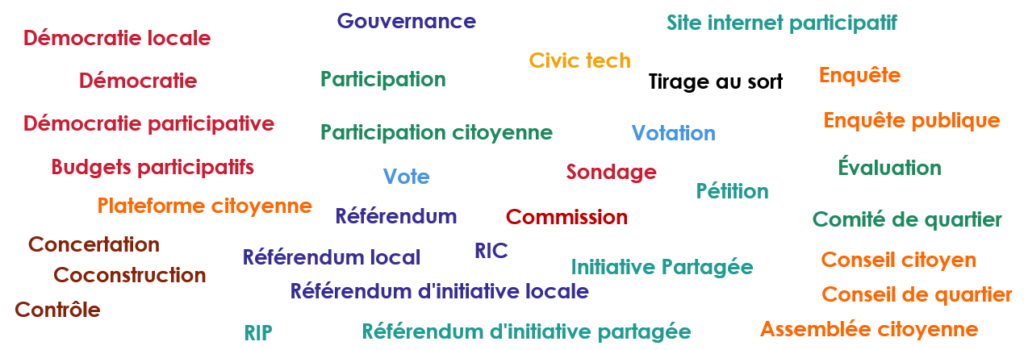
The objective of this second part is to carry out a statistical analysis of the collected corpus (programs of candidates). We have a list of 33 keywords for which we want to measure the term frequency of each term in this corpus (by candidates and/or towns). These terms can be presented in municipal programs with different inflected forms. For example, ‘citoyen’ can be written with different forms: ‘citoyen’, ‘citoyenne’, ‘citoyens’, and ‘citoyennes’. In order to take into account all of the inflected forms associated with each keyword, we have chosen to use Lexique3, a lexical resource that describes different information for the 140 000 words in the French language such as the part of speech, the number of syllables, and the root of the word. It is the latter that interests us in this project, often called by lemma in the NLP.
In addition, it should be noted that Lexique3 offers lemmas for singular words whereas 15 terms of the 33 keywords that we have are multi-words. The solution we propose to resolve this problem is in two steps:
- First, we get the lemma of each word belonging to the expression (multi-words),
- Then, we generate all possible variants. For example, for ‘conseil citoyen’, we have ‘conseil citoyen’ and ‘conseils citoyens’. This technique thus allows us to cover all possible entries associated with a keyword.
We presented various results following the statistical analysis carried out:
- Term Frequency: for each candidate’s program, we obtained the number of occurrences for each keyword
- Global Term Frequency: for each keyword, we obtained the total number of occurrences on the whole corpus
- Document Frequency: we obtained the number of programs for which a keyword appears. A single occurrence of a keyword is sufficient to judge that the program cites it
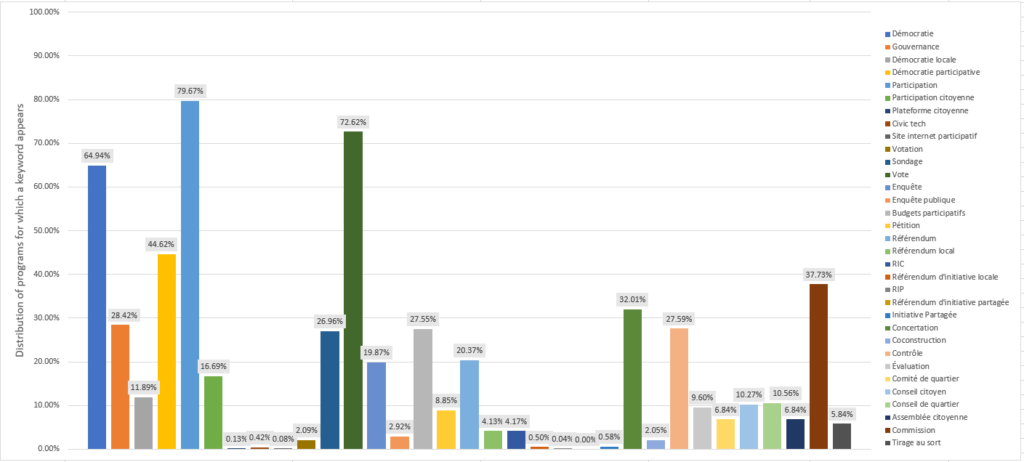
- Coverage: the percentage of programs that evoke each keyword
- Dominant program: the idea is to find which candidate’s program tell us most about a keyword
- A distribution (%) of keywords for each town: This allows us to see the main keywords mentioned by the programs of a given town
To synthetise the results we built a global indicator which aims at classifying the cities among 3 classes:
- Class 0: a town does not indicate or hardly indicate topics that evoke the participative democracy
- Class 1: a town talks about the requested topics
- Class 2: a town talks a lot about these topics
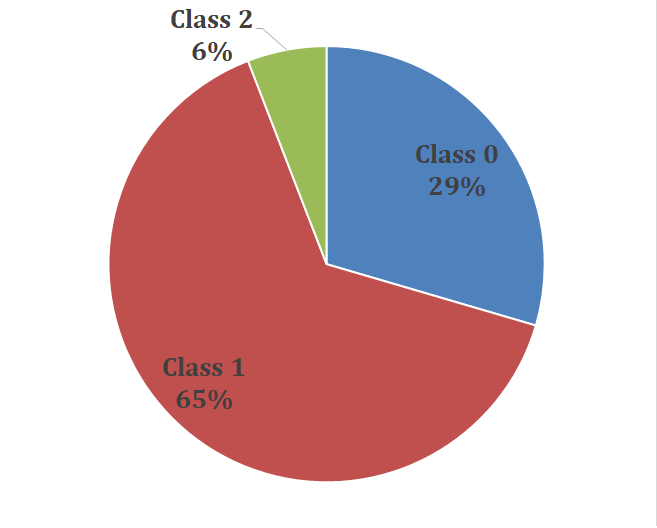
Overall results show that a very large majority of candidates talk reasonably about the participative democracy topics (about 65%), very few never talked about these topics (only 6%), and it appears to be a major topic of interest for a third of cities (29%). This means that participative democracy is a strong tendency in local politics.



