

Our times are increasingly influenced by the prevalence of large volumes of data. These data most often hide great human intelligence. This intrinsic knowledge; whatever the field; would allow our information systems to be much more efficient in the processing and interpretation of structured and unstructured data. For example, the process of finding relevant documents or grouping documents to derive topics is not always facilitated, when the documents are drawn from a specific domain. In the same way, the automatic generation of texts to inform a chatbot or a voice bot how to meet the needs of their users perceives the same problem: the lack of precise representation of the knowledge of each potential specific domain that could be exploited. Then, most retrieval and extract information systems rely on the use of one or more external knowledge bases, but they have the difficulty of developing and maintaining resources specific to each domain.
The most fundamental elements of the Semantic Web are ontologies, which have gained popularity and recognition as they are considered as a response to the needs of semantic interoperability in modern computer systems. These ontological bases are very powerful tools for the representation of knowledge. Today, the structuring and management of knowledge are at the heart of the concerns of the scientific communities. The exponential increase in structured, semi-structured, and unstructured data on the Web has made the automatic acquisition of ontologies from texts a very important domain of research. Ontologies are widely used in information retrieval (IR), Questions/Answers, and decision support systems. An ontology is a formal and structural way of representing the concepts and relationships of a shared conceptualization. More specifically, an ontology can be defined with concepts, relationships, hierarchies of concepts and relationships, and axioms present for a given domain. However, building large ontologies is a difficult task, and it is impossible to build them for all possible domains. Concretely, the manual construction of an ontology is a labor-intensive task. Although unstructured data can be transformed into structured data, this construction involves a very long and costly process especially when frequent updates are required. Consequently, instead of developing them by hand, the research trend is currently moving towards the automatic learning of ontologies to avoid the bottleneck in the acquisition of knowledge.
The ontologies and Knowledge Graphs (KG) that can be deduced appear as a solution to the interpretation of hyper-specialized vocabularies. To discuss these vocabularies, it should be noted that our Berger-Levrault group currently offers more than 200 books and hundreds of articles with legal and practical expertise on the Légibases portal. This portal covers 8 domains:

In addition, the collections of books are thematic, partially annotated, and the result of significant editorial work between Berger-Levrault and many experts. As mentioned at the beginning of this article, the knowledge that can be extracted from voluminous data (for our case, Berger-Levrault editorial base that is written in French) is very useful for a whole range of possible applications, going from information extraction (IE) and documents research to enriching the knowledge of conversational agents in order to best meet the needs of users.
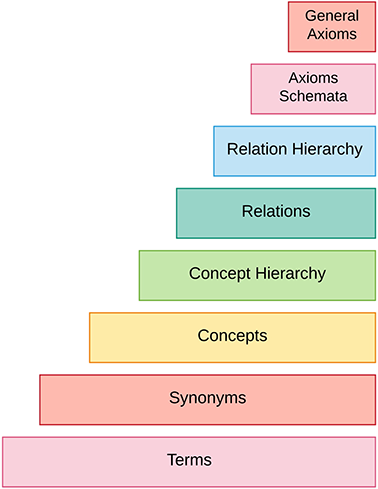
The process of acquiring ontologies from texts goes through several stages: it begins first with the identification of key terms and their synonyms, then these terms and synonyms are combined to form concepts. Next, taxonomic, and non-taxonomic relationships between these concepts are extracted, for example by inference methods. Finally, the axiom schemes are instantiated, and the general axioms are deduced. This whole process is known as the ontology learning layer cake, as shown in the figure below.
The advantage that we have available is that all documents of our editorial base (books and articles) have a semi-structured representation, that is, each paragraph of each document is annotated by experts with key terms. These annotations can lead us to build ontological bases with a good quality when we find that the identification of key terms is an essential step on the creation of ontologies.
The approach that we propose consists in monitoring the progress of this process above and applying it to the fields of the public sector. However, it should be noted that to satisfy each stage of this process, several techniques and models have been proposed in the literature. Concretely, our approach will emphasize learning with little supervision. The principle consists in automatically integrating into an ontology the instances of concepts and relationships with a confidence score deemed high and to manually validate the instances with a low confidence score. These manual validations will allow us to learn new rules that we propose to integrate into the learning system to limit supervision the most possible.
The recent advances offered by word embeddings with vectorization methods such as Word2Vec, Glove (Global Vectors for Word Representation) or even BERT (Bidirectional Encoder Representations from Transformers) offer the potential for analysis of textual information which has already proven itself in many applications, such as voice assistants and translation engines. For our experiments, we have chosen to work with BERT to train a language model on the editorial base. This model thus allows us to have contextualized word embeddings (continuous contextualized word vectors) for all key terms that experts have selected.
As an example, if we take only the articles of the Légibases and only the annotations coming from the thesaurus of the 8 domains, we have in terms of annotation the following elements:
| Domain | Number of key terms | Number of articles | Number of annotations |
| Civil status & Cemeteries | 642 | 2767 | 2169 |
| Elections | 108 | 152 | 150 |
| Public order | 876 | 1354 | 1201 |
| Urbanism | 327 | 1357 | 554 |
| Accounting & Local Finance | 981 | 1971 | 1957 |
| Regional HR | 293 | 361 | 122 |
| Justice | 1447 | 3980 | 870 |
| Health | 491 | 896 | 830 |
To give you an overview of our first word processing work on the editorial base, below, a figure summarizing the processing carried out to bring out key terms semantically close:
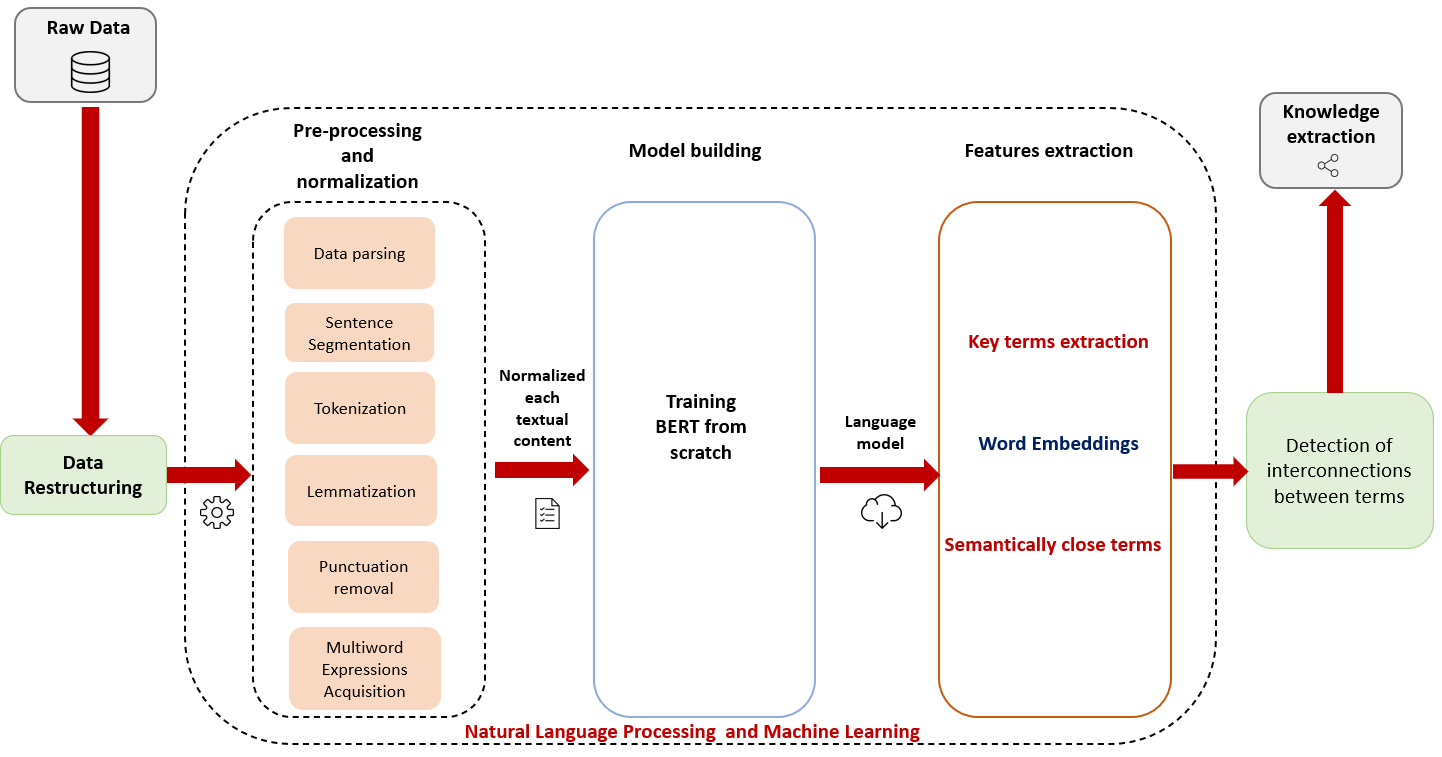
Step 1: Pre-processing and normalization
As the first step of our approach, we took over the Raw Data (RD) stored on our SQL database and performed a restructuring task in order to obtain an organized set of HTML documents, and therefore be able to exploit its content. Note that at this point, we identify the terms needed for our ontology learning process as the key terms annotated by the experts in each paragraph of each document.
Once the required format is obtained, we start up the pre-processing pipeline that goes as the following:
- Data parsing and sentence segmentation: parsing the HTML documents and breaking the text apart into separate sentences.
- Lemmatization: in most languages, words appear in different forms. Look at these two sentences:
« Les députés votent l’abolition de la monarchie constitutionnelle en France. »
« Le député vote l’abolition de la monarchie constitutionnelle en France. »
Both sentences talk about “député”, but they are using different inflections. When working with texts in a computer, it is helpful to know the base form of each word so that you know that both sentences are talking about the same meaning and same concept “député”. This will especially come in handy during training word embeddings. - Multiword Expressions (MWE) Acquisition: replacement of whitespaces in multiword expressions by an underscore “_”, so that the term would be considered as a single token and therefore a single vector embedding will be generated for it instead of two or more vectors for each word that is part of it.
To prepare the text content for embeddings training, we generate a raw text file, from HTML documents, containing one sentence per line with unified keywords (same representation).
Step 2: Model Building
Now that we have a normalized text file, we can launch the training of the state-of-the-art Natural Language Understanding model BERT on our text file using Amazon Web Services infrastructure (Sagemaker + S3) as fellow:

- Building the vocabulary: we will learn a vocabulary that we will use to represent our editorial base.
- Generating pre-training data: with the vocabulary at hand, BERT can generate its pre-training data.
- Setting up persistent storage: to preserve our assets, we will persist them to AWS Storage (S3 in AWS).
Step 3: Features extraction
- Generation of word/term Embeddings.
- Measure the Cosine similarity between all key terms and thus deduce their semantic dependencies.
Results
Here is an overview of the frequency distribution for some terms present in our editorial base:
| Highly common terms | Average common terms | Less common terms |
| Key terms / Term frequency (TF) | Key terms / Term frequency (TF) | Key terms / Term frequency (TF) |
| code / 125 912 | jury / 3 290 | intérêt commun / 4 |
| loi / 90 177 | famille / 3 280 | association para-administrative / 4 |
| … | … | |
| permis de construire / 7 268 | démocratie / 2 158 | convention d’encaissement de recettes / 1 |
After obtaining Cosine similarity scores between two given terms, we build a CSV file that contains the top 100 frequent key terms in our editorial base, their 50 closest words, as well as their similarity scores. The figure below shows the 100 most frequent terms:

The file is then presented as an input to create the following labeled graph representing the semantic dependencies obtained from the previous steps:
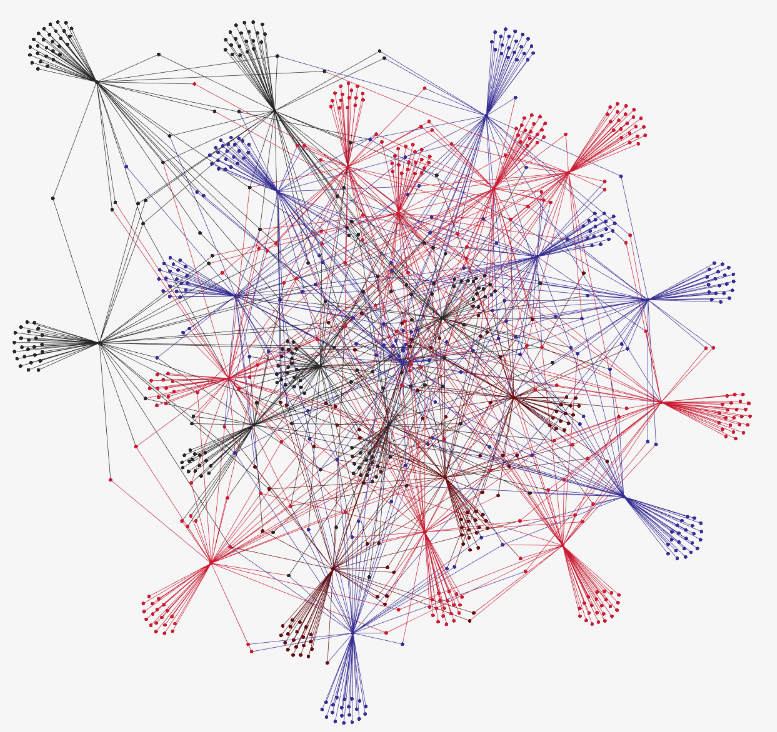
For an example, we show you below the terms closest semantically to “droit”:

We remind that we present here the first work that we carried out for the study of the corpus of the editorial base and that the continuation of this work will lead us to apply techniques of extraction of concepts and relations using different levels of analysis, namely: linguistic, statistical and semantic level.



