

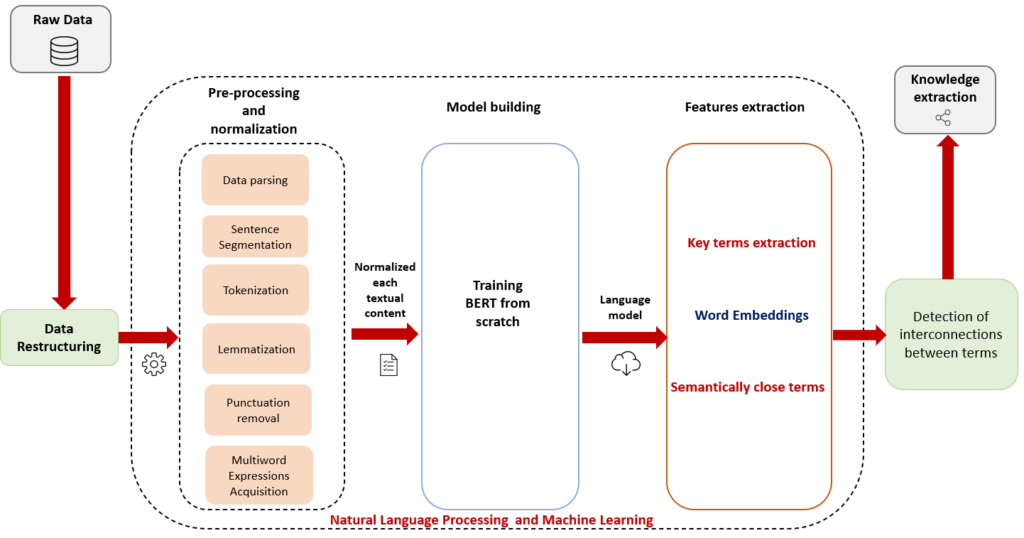
There’s a suite of available options to run BERT model with Pytorch and Tensorflow. But to make it easy to get our hands on our model, we went with Bert-as-a-service : a Python library that enables us to deploy pre-trained BERT models in our local machine and run inference.
We run a Python script from which we use the BERT service to encode our words into word embedding. Given that, we just have to import the BERT-client library and create an instance of the client class. Once we do that, we can feed the list of words or sentences that we want to encode.
Now that we have the vectors of every word of our text file, we will use scikit-learn implementation of cosine similarity between word embedding to help determine how close they are related.
Here is an overview of the frequency distribution for some terms present in our editorial base:

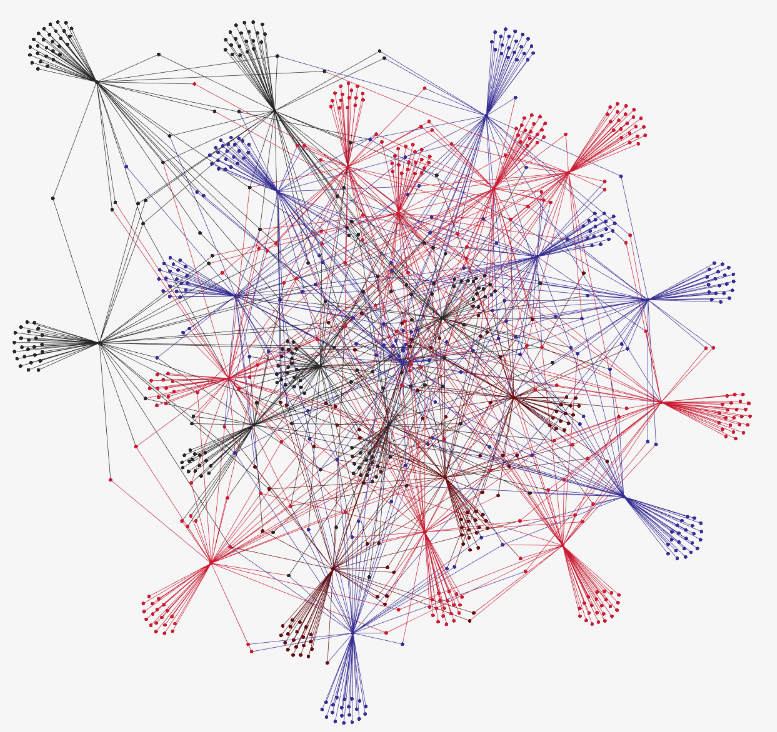
After obtaining Cosine similarity scores between two given terms, we build a CSV file that contains the top 100 frequent key terms in our editorial base, their 50 closest words, as well as their similarity scores. The figure below shows the 100 most frequent terms:

The file is then presented as an input to create the following labeled graph representing the semantic dependencies obtained from the previous steps:



