

In Berger-Levrault, several of our software products incorporate a search engine in themselves to facilitate access to information. This information can be encoded in files having various and varied formats. For example, Word, PDF, CSV, JSON or even XML files. Current search engines such as Lucene focus most of the time on keyword searches. This in fact limits in-depth searches, for example, to find semantic links between the words expressed by the user and the words contained in the database to be indexed. These semantic links can refer to several lexico-semantic relations such as synonymy, specification, generalization, or even semantic refinement. That said, in-depth research can improve the coverage of returned responses and promote intelligent research that goes beyond simple keywords research. This is what we are going to tell you in this article, a new smarter search engine component that puts itself as a service of Berger-Levrault products. We called this component DEESSE: Deep Semantic Search Engine. For this research and technological innovation project, we were interested in proposing semantic document search methods while considering the words and their contexts in a database to be indexed.
A first exercise was already carried out on deed documents produced in “BL.Actes-Office (BLAO)”. Before going into the details of the fundamental approach of DEESSE, since this new system has received good feedbacks, BLAO already uses our DEESSE service and we can congratulate ourselves for that. However, we would like to mention that for BLAO, a java API was used to communicate with Lucene (the old system). For reasons of interoperability, DEESSE is currently offered as a java component (JAR) with an API. Although DEESSE was originally developed for BLAO, we have considered future uses with different business contexts. Therefore, the proposed API is generic. Finally, work is in progress to propose a REST API and thus to offer DEESSE as an online indexing and search service. Furthermore, we would like to mention that DEESSE indexes documents faster than its predecessor: the old Lucene system and uses much less disk space.
Scientific background
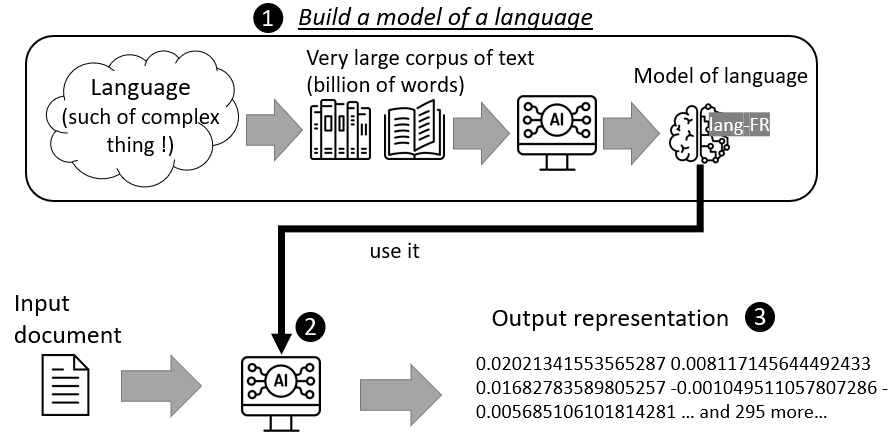
Machines are not capable of understanding textual content like a human, so it is very difficult to design a program capable of understanding all the subtleties of a language. Therefore, we speak of “representation” and “model”. A representation is a machine-readable form of textual content. Like binary encoding, representations are often incomprehensible to humans. For example, in Figure 1, ❸ is a representation of a document. These representations are calculated by a mathematical process that seeks the most simplifying representation while retaining the maximum amount of detail ❷. However, for this representation to be consistent with a language, the process is parameterized by a model describing that source language ❶.
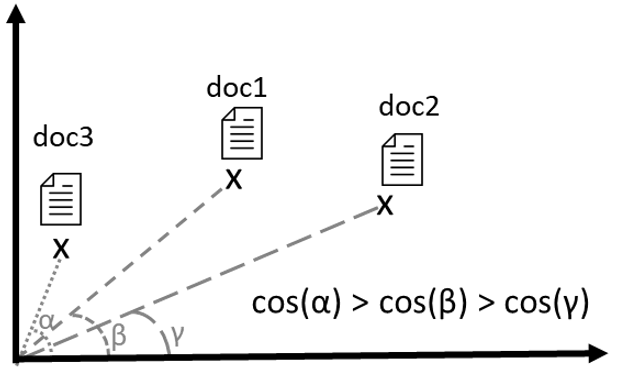
With these representations and in a given model it is possible to compare the representations. Figure 2 gives an illustration. One of these comparisons is based on a metric called cosine. One way to represent this is to visualize documents at some points in an n-dimensional space. Simply measure an angle between these documents, the cosine, to know how close they are semantical.
The techniques used in this work belong to both artificial intelligence (AI), natural language processing (NLP), and information retrieval (IR). These three fields of science and technology have a lot in common: they all deal with text expressed in natural language. The representation of documents within an IR system and the calculation of similarity between these representations are two different issues that we have dealt with in this research and development project. In addition, the strength of DEESSE system is to give the user the possibility of expressing his request (query) in natural language (like Google does).
The main objective of this work is to propose a semantic representation model, on the one hand, for the documents database to be indexed and, on the other hand, for the query expressed by a user whose goal is to semantically query a database. To give a semantic representation that carries the meaning of the documents, we based ourselves on a language model trained on a very large corpus coming from the .fr domain that we detail below (in the next section). This same model was used to give a semantic representation to the query; As for the similarity measure used to compare the representation of the query to the representations of the documents, we used the very popular Cosine measure.
How does it work in depth?
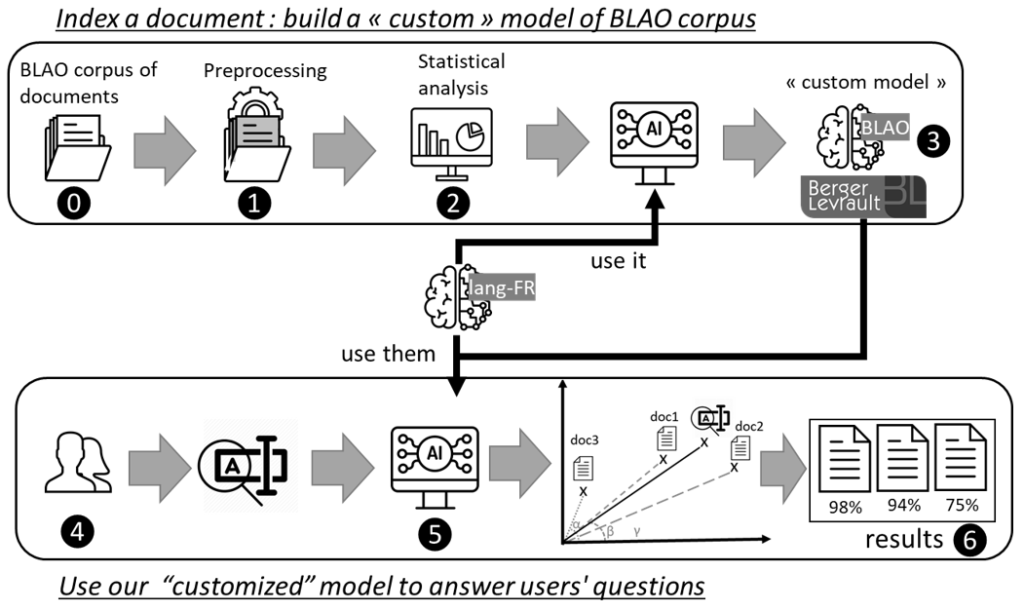
We detail here the architecture of our approach to creating semantic representations as well as how to return the documents that are semantically closest. Figure 3 describes the main stages. To test our DEESSE proposal, we worked on a sub-corpus of the BLAO database: this is a set of deliberation documents for the city of Draguignan ⓿. These documents are first, ❶, pre-processed to find words with meaning (nouns, adjectives, adverbs, and verbs) and stop words (e.g., determinants, prepositions, etc.). Then ❷ a statistical description is made. For each word with a meaning, its number of occurrences is counted (Term Frequency – TF) and then its inverse document frequency (IDF). With the results of the second step, the document is indexed ❸, i.e., a representation of the document is constructed. For this, external resources are used (morphological families and language model).
For research, users express their queries in natural language ❹. As with documents, during indexing, a representation of the query is constructed ❺. It is then compared with the representations of previously indexed documents to determine which documents are semantically closest ❻.
The Figure 4 below presents the different stages of our approach in more detail.
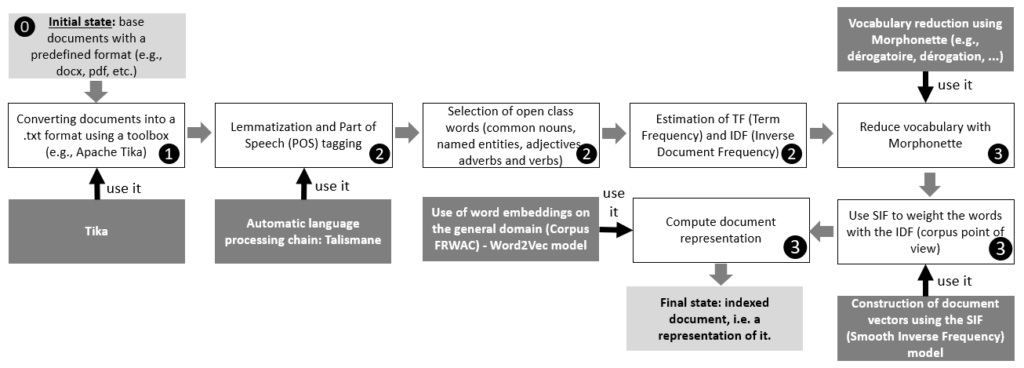
First, the documents ⓿ are converted to a plain text format (*.txt) ❶. This latter text format is passed to Talismane which the idea here is to extract meaningful words (open-class words) ❷. The idea thereafter is to measure the degree of frequency in terms of occurrences (Term Frequency) as well as the inverse document frequency (IDF) of all the words in the documents to be indexed.
Semantic representation of documents ❸
Below, we describe the two essential steps in creating semantic representation of documents:
- After obtaining the different lemmas of a given document, we perform a lexical substitution to reduce the vocabulary, that is to say, we use the Morphonette ressource (Hathout, 2008) to replace, if possible, the words of a document by the most frequent words in the corpus and belonging to the same morphological family. For example, dérogatoire can be replaced by dérogation if it is more frequent than it.
- We build continuous vector representations to documents from a list of words. For this, we use the Smooth Inverse Frequency (SIF) algorithm proposed by Arora et al. (2017). The principle of this algorithm consists of taking the weighted average of the incorporation of words in a text in order not to give too much weight to words that are not relevant from the semantic point of view. This step consists of considering the IDF associated with each word in the corpus.
To generate continuous vectors for documents, we based ourselves on a language model allowing us to provide vectors of words (word embeddings). These vectors are of the Word2Vec (Mikolov et al., 2013) with a CBOW (Continuous Bag of Words) architecture type. The Word2Vec model was trained on the FRWAC corpus (Fauconnier, 2015).
FRWAC is a French corpus of the .fr domain, it contains nearly two billion words. Fauconnier (2015) has already proposed a language model trained on this corpus, so we used it. For the transition from the representation of words to the representation of documents, we have chosen to use a weighted centroid vector as described by Arora et al. (2017). This vector is defined from the vectors of all the words of a given document. Moreover, the semantic representation of the query is constructed in the same way as the representation of documents.
The documents are indexed mainly by their semantic representation, the query too. However, since the language model was trained on a different corpus than the base to be processed, the model used may not offer a representation for the words expressed in the query. There are many reasons for this: we can deal with codes, terms that are too technical, or even dates, for example. The figure below describes our choices to deal with this problem, that is, the types of document representation used to query the indexed database.
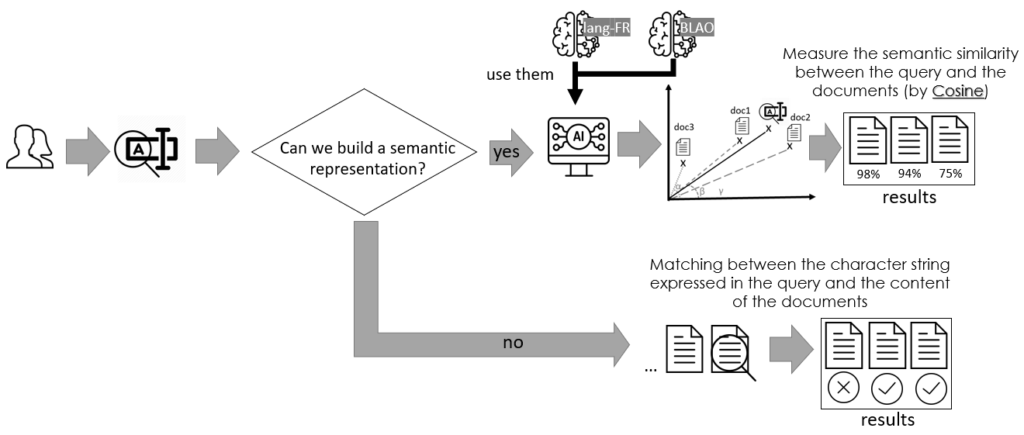
Therefore, to improve search results, and if the use of lexical embeddings from the FRWAC Corpus does not return a semantic representation for the query expressed by a user, we automatically apply an exact search (on raw texts). This secondary approach consists of finding exactly the character string of the query in the documents of our corpus.
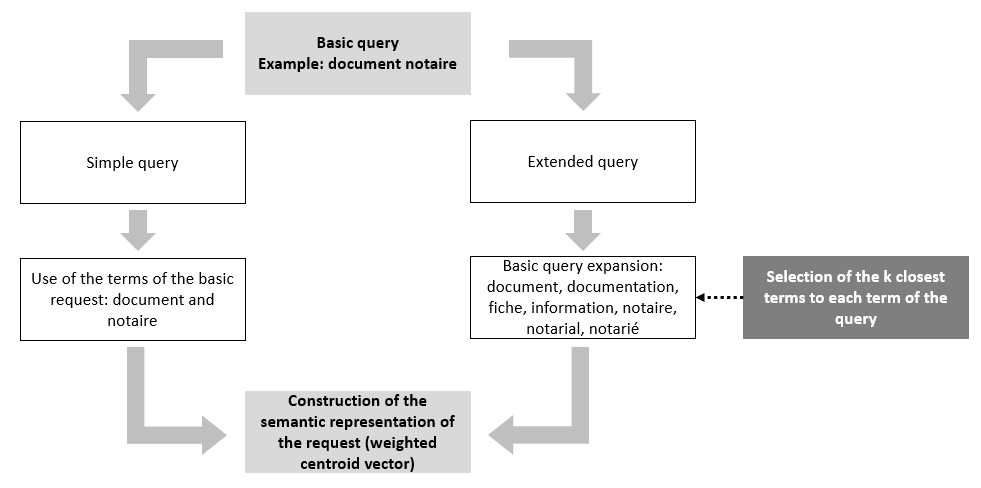
Queries type
We offer two ways to query a database:
- By using the words of the original query only
- By considering not only the words of the original query but also the three words semantically closest to each word of the original query. This extension of the words list of the query is based on the use of the language model Word2Vec
The figure below describes with an example how the words of the original query are used.
Another example, the query “Entreprise travaux publics” is expressed differently between the two types of queries. After processing the text of the query, the first type returns as a bag of words “entreprise, public andtravail ” while the second returns “entreprise, public, travail, chantier, collectivité, pme, pme-pmi, privé, professionnel, salarié and territorial”. With such a combination of words, it makes perfect sense that the semantic search result of documents might not be the same when applying both types of query.
Our experiments and results: Faster, Smaller, Better
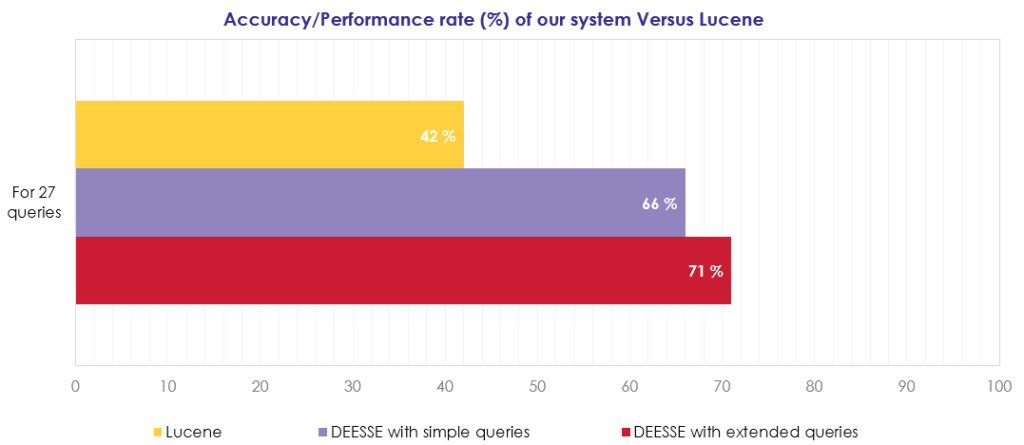
Now we present an evaluation of our approach in comparison with a system that relies on keyword indexing: the Lucene system. To achieve this task, we got in touch with an expert in the BLAO product. This expert provided us a set of 27 queries chosen to cover the possible forms that the queries expressed by users may have (character strings, codes, dates, etc.). A comparison with the Lucene system has been set up. It should be noted that Lucene is the system that was used mainly by BL. Actes-Office, this is no longer the case today since DEESSE replaced it. The figure below shows the different queries taken for the test.

The expert set about annotating the results, that is to say, annotating documents that are relevant to him and that should appear in the first place by the search engine. The figure below shows the evaluation of the results obtained. Our results, therefore, showed a performance rate of 71% for DEESSE with extended queries and 66% for DEESSE with simple queries against 42% for Lucene. We thus obtained +5% with extended queries. Also, out of 8 queries, our systems returned good results against nothing for Lucene: we found some in the following queries: “Entreprise travaux publics“, “Radiotéléphonique “, “2252129.78“, “18 francs” or “18“.
We conducted a comparative study between the legacy search engine, Lucene, and our DEESSE engine. The following table shows our results for a real-life corpus of 13 500 documents (total size of the corpus: 405 MB – average document size 30kb).
| Metrics | Legacy Engine (Lucene) | DEESSE engine | Gain |
|---|---|---|---|
| Total indexing time (hour) | 184.5 hours | 18.25 hours | 166.25 hours gained for indexing time DEESSE requires 90% less time for indexing. |
| Indexing speed (docs/hour) | 91 docs/hour | 740 docs/hour | 649 docs/hour |
| Indexing speed (MB/hour) | 2.73 mb/hour | 22.2 mb/hour | 19.5 mb/hour |
| Indexes size (MB) | 576 000 mb | 260 mb (all indexes) 138 mb (only semantic indexes) | 575 740 mb DEESSE use only 0.06% of the disk space required by Lucene. |
| Performance [1] (<0 : worst; 1: best) | – 1 397 | 0.35 (all indexes) 0.66 (only semantic indexes) |
The results are impressive and demonstrate remarkably well that DEESSE has nothing to envy existing engines, even in an industrial context! We know that 98% of the indexing time is due to the morpho-syntactic analysis. We are considering replacing the current analyzer with a faster one, such as TreeTagger[2]. We then expect a very significant gain (~50%) in indexing speed.
The performance metrics were so impressive that we had to check our results multiple times.
[1] Performance_Indexation = 1 – (Indexes files size/corpus size to be indexed)
[2] https://www.cis.uni-muenchen.de/~schmid/tools/TreeTagger/
Conclusion and future works
In this article, we presented DEESSE: a semantic document search model. This model has been tested on one of the BLAO product databases. DEESSE is based on the use of AI techniques (word embeddings), natural language processing (Talismane), and information retrieval methods (comparison of semantic representations “documents versus query” in the same vector space). We have seen that the use of word embeddings can improve the search for documents instead of just indexing by keywords. We present below the benefits for use DEESSE:

Otherwise, it should be noted that we have made two demonstrations of the DEESSE system available to all our Berger-Levrault collaborators: the first demonstration reflects the results of the performance obtained with BLAO; the second refers to the BL BOT database. This already allows us to think of the second version of BL BOT.
For future work, we would like to achieve the following below:
- A REST API for DEESSE so that the system can be used without technological restrictions
- Support for more several document formats (e.g., XML, JSON, CSV, etc.)
- For scientific research, it would be interesting to extend DEESSE to learn not only from the contents of documents but also by considering the words expressed in the user’s query. It is a question of considering what the user wishes to have most often and that in a semantic way and intelligently without leaving the contexts proposed in the database
- Test DEESSE on more product databases like BL.API, Legibases, Carl, Commune-IT, and many more.
References
| Apache Tika | https://tika.apache.org/ |
| Talismane | URIELI Assaf (2013). « Robust French syntax analysis: reconciling statistical methods and linguistic knowledge in the Talismane toolkit ». Thèse de doct. Université de Toulouse II le Mirail, France (http://redac.univ-tlse2.fr/applications/talismane.html). |
| Morphonette | HATHOUT Nabil (2008). Acquisition of the morphological structure of the lexicon-based on lexical similarity and formal analogy. Proceedings of the 3rd Textgraphs Workshop on Graph-Based Algorithms for Natural Language Processing, p. 1–8. DOI : 10.3115/1627328.1627329 (http://redac.univ-tlse2.fr/lexiques/morphonette.html). |
| FRWAC | BARONI Marco, BERNARDINI Silvia, FERRARESI Adriano and ZANCHETTA Eros (2009). “The WaCky wide web: a collection of very large linguistically processed web-crawled corpora”. In Language Resources and Evaluation, p. 209–226. |
| Word2Ve | MIKOLOV Tomáš, CHEN Kai, CORRADO Greg et DEAN Jeffrey (2013). « Efficient Estimation of Word Representations in Vector Space ». Proceedings of the International Conference on Learning Representations, p. 1–12 (https://code.google.com/archive/p/word2vec/). |
| Smooth Inverse Frequency (SIF) | ARORA Sanjeev, LIANG Yingyu et MA Tengyu (2017). A simple but Though-To-Beat Baseline for Sentence Embeddings. In International Conference on Learning Representations (ICLR) (https://github.com/KHN190/sif-java). |
| Standard Language Model | FAUCONNIER, Jean-Philippe (2015). French Word Embeddings (http://fauconnier.githubio/#data). |
| Lucene | https://lucene.apache.org/ |
| TreeTagger | SCHMID Helmut (1994). « Probabilistic Part-of-Speech Tagging Using Decision Trees ». Proceedings of International Conference on New Methods in Language Processing, Manchester, UK. |



