
In the current socioeconomic context, companies must work together. Interoperability, which is the action to work together through systems is an unconditional factor to do so. To work, the information shared needs to be compatible. Information can be incompatible when they’re built differently by people or systems.
Mediation goal is to manage syntactic and semantic information matching to federate information resources between partners. We speak about matching schema based on unsupervised learning methods: the process to automatically identify items semantically linked.
So our objective is to automatize this process with a general matching schema taking two information schemas build in different ways and produce a consistent one semantically understandable.
As messages are only textual, we used Natural Language Processing (NLP) methods to detect semantic compatibility between the text fields.
A mediation semantic approach for data exchange between schemas
Input parameters choice
Different parameters have to be taken into account:
- The number of similar words: words are translated in vectors into the algorithm. If there are a lot of similar words, it must be considerate as data will be close to each other (we call them neighbors).
- The acceptation threshold: it must be determined at the beginning of the algorithm. If the distance between two vectors is below this threshold, the fields can be considerate as matching, though, if the distance is above it, the match isn’t accepted.
- The top candidates to considerate at the output: It defines the number of terms to considerate when generating the matching fields. Indeed, a candidates list will be sorted during the process. This list can be exhaustive or not.
Data collection
In the mediation process, we’ll have two schemas in a similar or different format. The first step of the process will be to convert them in a common, well known and easy to manipulate format (CSV for instance).
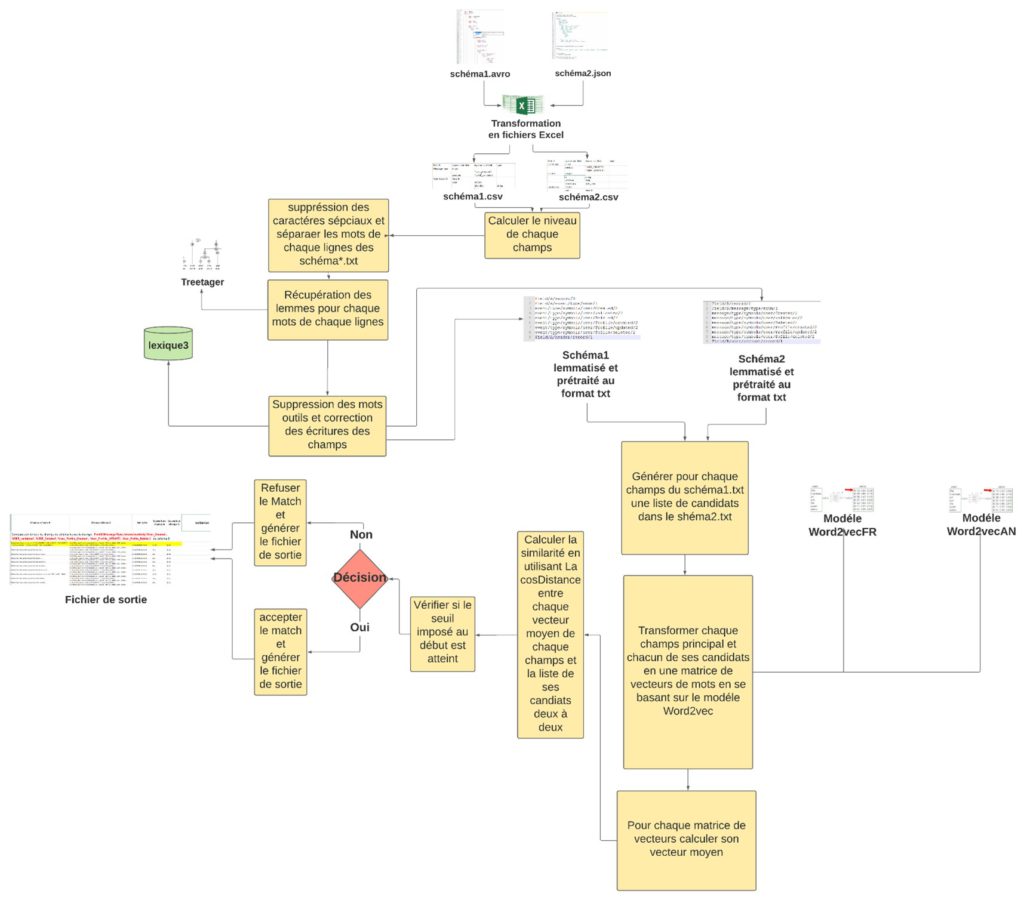
Schema preprocessing
This is a fundamental step in the matching process. It removes data noise which negatively impact the similarity calculation model (We call “noise” the orthographic variant of a same word. It can be a spelling mistake or the plural form of a word). For this step, we applied a preprocessing which must “clean” the data. We’ve set up a process pipeline (figure 1):
- Calculation of level fields: It refers to the position of the field in the code structure.
- Special characters suppression and separation of fields in word sequences.
- Lemma recovery: The lemma is the verb infinitive and the singular masculine form of a name, an adjective or an adverb. The lemma recovery goal is to group terms which express a similar idea to show if fields are matching or not. The lemmatization considers the context of the word that has been use in and find its “common” form.
- Stop words suppression: The stop words are very frequent which don’t contribute to the comprehension. We’ve constituted a list of French and English stop word with 890 words (pronouns for instance).
- Correction of spelling mistakes: Words badly spelled can’t be lemmatized and will not be recognized by our model. To avoid this problem, we established an orthographic similarity in our solution to identify similar words and avoid silly mistakes due to spelling.
Matching schemas steps
The first step of the matching schemas is to generate a candidate list which consist in listing words candidates for each field of schema 1 and schema 2. This list will depend on the number of similar words define previously and the matching will only be applied on this list. The second step is to transform terms into vectors. The words of the two originals schemas can be in different languages, so it’s essential to translate them in a same language: a one vector space. From these data, we can build the vector matrix and calculate the average units to represent a field with a single vector. Based on this information, the algorithm will be able to see if the fields are similar or not by comparing them to the threshold determined before.

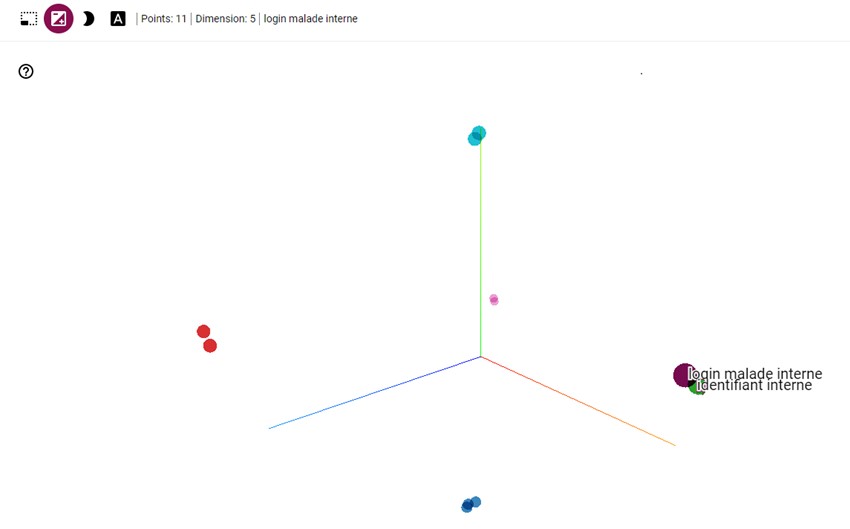
As you can observe in the figure, the closest the points are in the cloud will determine how similar are the fields.
Experimentation and results
In the table below (figure 4), we synthesize the result of our different experimentations and their evaluations. V1, V2, V3 and V4, represent our four variants according to the number of neighbors terms and the threshold we’ve configured.
- In our first experimentation, we tested our matching schemas approach on the two following schemas: Application Role Event Specification and Message Type Role Event.
- In the course of the second experimentation, we measured the benefit of our schemas matching approach in the health sector. We tested our matching schemas on two schemas named Patient Synchronization and Internal Patient Medical Data that we built manually.
- For the last experimentation, we tested the lemmatization and orthographic correction of our approach by using the same schema than in experimentation 2 without applying the lemmatization and orthographic correction.

Precision is the relation between pair correctly matched and the number of pair matched
Recall is the relation between pair correctly matched and the number of pair to match
FMesure is the harmonic measurement between Precision and Recall
The results of the experimentation shows that the consideration of level fields has a benefit on our approach, indeed in the course of the fields matching, the F-Mesure goes up to 83% when we defined a number of words neighbors.
The third experimentation results shows the importance of lemmatization and orthographic correction. They improved the F-Mesure by 35% and allow to cover more English and French terms.
Through experimentation 1 and 2 using V1, we noticed that with a smaller threshold than 1 (0.6) our approach still cover a large part of the fields. Moreover, the compromise we chose between the number of “neighbors” and the threshold gave better results.
In resume, we could observe the best results through our first approach which include lemmatization and orthographic correction. Though it would be interesting to explore more the type of fields and distinctive approach for the schema matching (like the top terms candidates and the kind of fields for instance).



