
Relationship identification in documents is part of a project about knowledge graph.
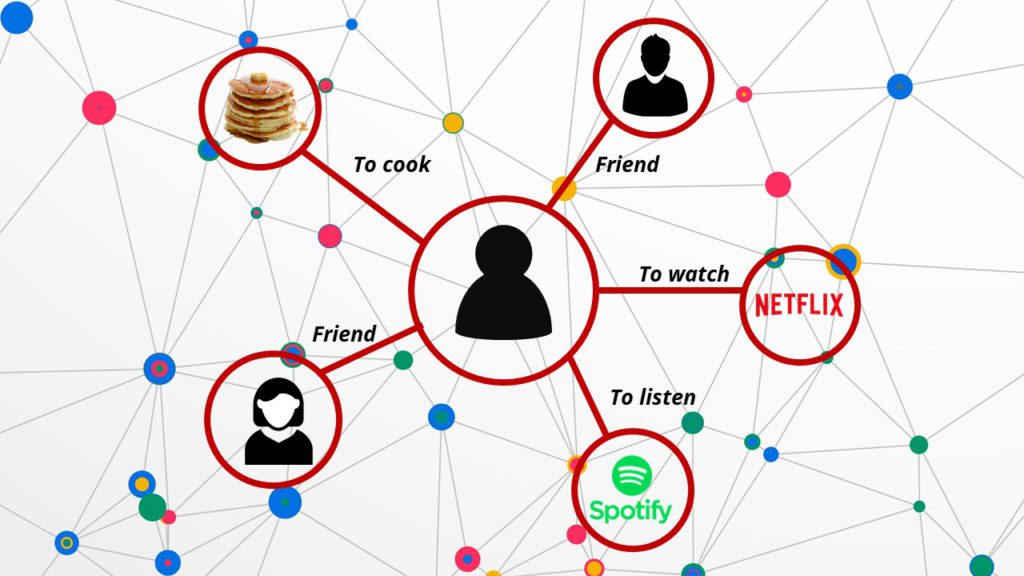
A knowledge graph is a way to graphically present semantic relationship between subjects like peoples, places, organizations etc. which makes possible to synthetically show a body of knowledge. For instance, figure 1 present a social media knowledge graph, we can find some information about the person concerned: friendship, its hobbies and its taste.
The main objective of this project is to semi-automatically learn knowledge graphs from texts according to the speciality field. Indeed, the text we use in this project come from height public sector fields which are: Civil status and cemetery, Election, Public order, Town planning, Accounting and local finances, Local human resources, Justice and Health. These texts edited by Berger-Levrault comes from 172 books and 12 838 online articles of judicial and practical expertise.
To start, a specialist in the area analyzes a document or article by going through each paragraph and choose to annotate it or not with one or various terms. At the end, there was 52 476 annotations on the books texts and 8 014 on articles which can be multiple words or single term.
From those texts we want to obtain several knowledge graphs in function of the domain like in the figure below:
Like in our social media graph (figure 1) we can find connection between speciality words. That’s what we are looking to do. From all the annotations, we want to identify semantic relationship to highlight them in our knowledge graph.
Process explanation
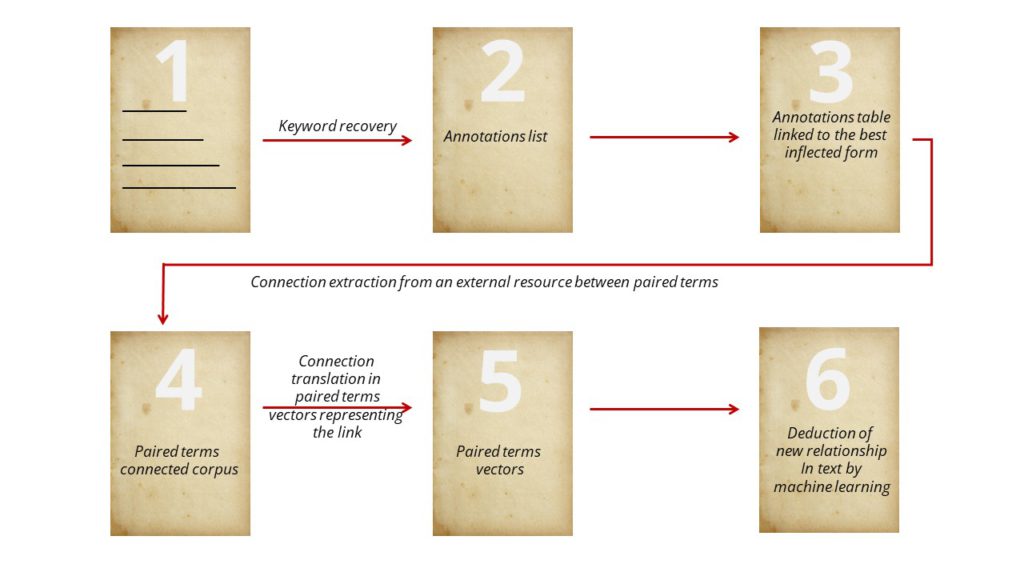
The first step is to recover all the experts annotations from the texts (1). These annotations are manually operated and the experts don’t have a referential lexicon, so they may not use the same term (2). The key words are described with several inflected forms and sometimes with irrelevant additional information like determiner (“a”, “the” for instance). So, we process all the inflected forms to obtain a unique key word list (3).
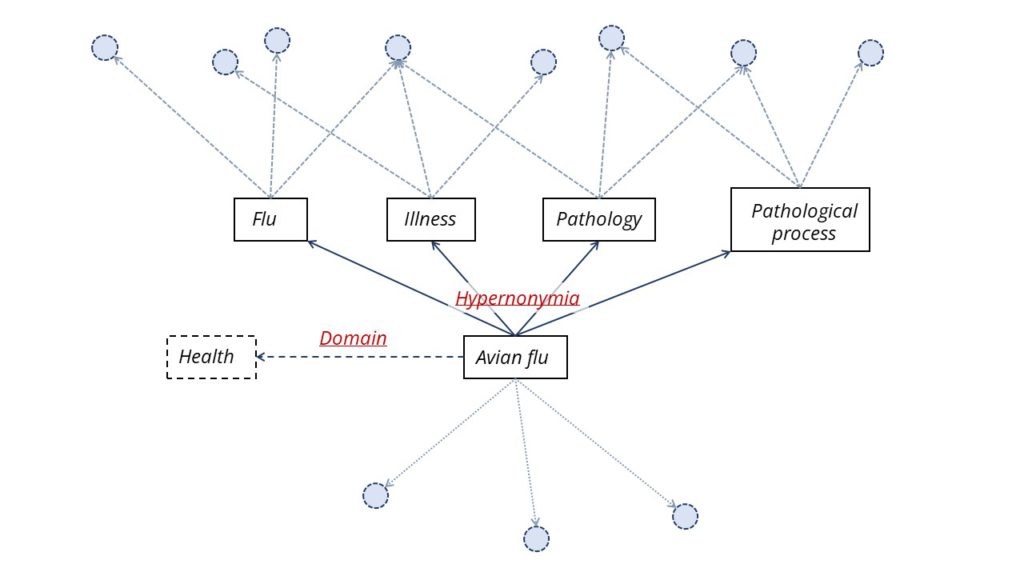
With these unique key words as base, we’ll extract from external resources semantic connections. At the moment, we focus on four scenario: antonymy, terms with opposite sense; synonymy, different terms with the same meaning; hypernonymia, representing terms which can be associated to the generics of a given target, for instance, “avian flu” has for generic term: “flu”, “illness”, “pathology” and hyponymy which associate terms to a specific given target. For instance, “engagement” has for specific term “wedding”, “long term engagement”, “social engagement”…
With deep learning, we are building contextual terms vectors of our texts to deduct pair terms presenting a given connection (antonymy, synonymy, hypernonymia and hyponymy) with simple arithmetic operations. These vectors (5) make a training game for machine learning relationship. From those paired words we can deduct new connection between text words which aren’t known yet.
Connection identification is a crucial step in knowledge graph building automatization (also called ontological base) multi-domain. Berger-Levrault develop and upkeep big sized software with commitment to the final user, so, the company wants to improve its performance in knowledge representation of its editing base through ontological resources and improving some products performance by using those knowledge.
Future perspectives
Our era is more and more influenced by big data volume predominance. These data generally hide a large human intelligence. This knowledge would allow our information systems to be more performing in processing and interpreting structured or unstructured data.
For instance, relevant document research process or grouping document to deduct thematic aren’t always easy, especially when documents come from a specific sector. In the same way, automatic text generation to teach a chatbot or voicebot how to answer questions meet the same difficulty: a precise knowledge representation of each potential speciality area which could be used is missing. Finally, most information research and extraction system is based on one or several external knowledge base, but has difficulties to develop and maintain specific resources in each domain.
To get good connection identification results, we need a large number of data as we have with 172 books with 52 476 annotations and 12 838 articles with 8 014 annotation. Though machine learning methodologies can have difficulties. Indeed, some examples can be faintly represented in texts. How to make sure our model will pick up all the interesting connection in them ? We are considering to set up others methods to identify dimly represented relation in texts with symbolic methodologies. We want to detect them by finding pattern in linked texts. For instance, in the sentence “the cat is a kind of feline”, we can identify the pattern “is a kind of”. It enable to link “cat” and “feline” as the second generic of the first. So we want to adapt this kind of pattern to our corpus.



