
When our client equipment needs maintenance intervention for any reason, they can request it through Carl Source, our CMMS software.
Those intervention queries will be received by the technical service which will analyze it, pre-qualify it and associate it to an intervention type before scheduling it. Some interventions are more urgent to other and some need technical specificity or special skill. It can easily become a brainteaser. Therefore, if the number of daily queries become really important, the person in charge can quickly be overwhelmed in its work.
To facilitate their work and make their schedule intervention more efficient, we worked on an algorithm to analyze and classify the intervention queries and provide helping information to the person in charge of scheduling maintenance intervention.
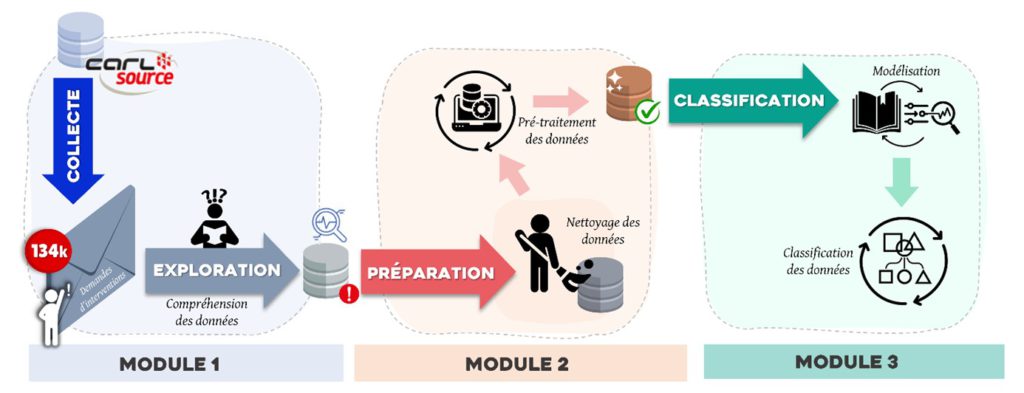
Our solution is composed of three main units. The first unit is dedicated to data collection and exploitation, the second unit extract knowledge and transform the raw data collected into useful data, then in the last unit, transformed data will be classified by type of intervention (in some cases, the algorithm can suggest different types of intervention). With those information, the person in charge can decide to associate the query to an intervention with the right technician.
In this project, it is really important to know what maintenance is about. Maintenance can be needed in various business area like industry, energy, transport, etc. and for different reason. It can be for corrective reason when a failure happens on equipment, for preventive reason to avoid a future failure due to time for instance or predictive maintenance when the machine activity is measured with IoT technology and can prevent its own breakdown.
Data understanding
From our private network, we collected the intervention queries data from 22 clients. It’s important to know that intervention queries forms can be personalized by each client, depending on his needs. That’s why we have to select the most indicative and communal requirements.
Once exported, data look like on figure 3 presented below.

To uniform those data, we select the most relevant and communal information to classify the intervention queries. The information selected are: the name of the clients, intervention query ID, the priority degree, current status of the query, creation date, equipment concerned, query title and its description.
By going through these raw data, we noticed some noise in them. We call noise the language differences observed like spelling mistake, words in other language, acronyms, brand names, etc. That’s why we need to prepare the data before treating them.
Data preparation
To select the right information from the collected data, we categorize them in two groups.
A first group with variable characteristics: the client name, the query code, its status, priority degree, date and the equipment concerned ID. A second group for informative variables which are in our case: the title, query description and equipment name.
Now, we have to prepare the data to its treatment. To do so, we have to go through the following “cleaning” steps:
Tokenization: This first step is the entry point for any NLP process. It consists in transforming the intervention query in an individual words series called “tokens”.
Punctuation, symbols, extra space and digits suppression: Those elements don’t provide useful information, though they can be disruptive in the treatment.
Stopwords suppression: Stopwords, also called empty words are frequents terms used which do not add valuable information to a sentence. We delete them to reduce the model vocabulary.
Spelling correction: We need correctly spelled words to interpret them. To correct spelling mistakes, we use Pyenchant which suggest corrections for misspelled words.
Proper name detection and suppression
Detection and suppression of internal clients codes and intervention query test
Recognition of entity name, like cities, places, brand, etc.
Acronyms identification
Lemmatization to identify the same expression with different forms (plural form, conjugate form, etc.)
Synonym management to reduce the model vocabulary.
N-grams detection and processing: N-grams are words’ association which are important precision to contextualize an intervention query. For instance, the term “water leak” is more precise than “leak” alone to determine the type of intervention. To detect them, we use established libraries.
Modelling: Classification by vocabulary dominance
Once the data are prepared, we can classify the intervention queries by analyzing the vocabulary used. In the analysis we’re looking for distinctive key words to categorize the intervention. These key words are in lexicons defined in advance and describe each type of intervention.
In this project, we have eight types of interventions:
- Plumbing: This type of intervention requires a plumber with specific knowledge and has to be done quickly in most case
- Property maintenance: It requires a multi-task technician to do all kind of general maintenance and isn’t urgent in general
- Electricity: These interventions can only be realized by an electrician and can requires specific skills
- IT and telephony: Generally these are subcontracted or managed by a specific team.
- Fire safety: Usually subcontracted with a direct link to a manager
- Machine maintenance: It requires a special technician. The most difficult in this type of intervention is to figure out how urgent is the intervention and the importance of the affected equipment
- Administrative: It can be report, orders, selling and buying process…
- Unclassified: When there is not enough information in the intervention query, the words used aren’t in the lexicons, there is competencies between different intervention types, etc.
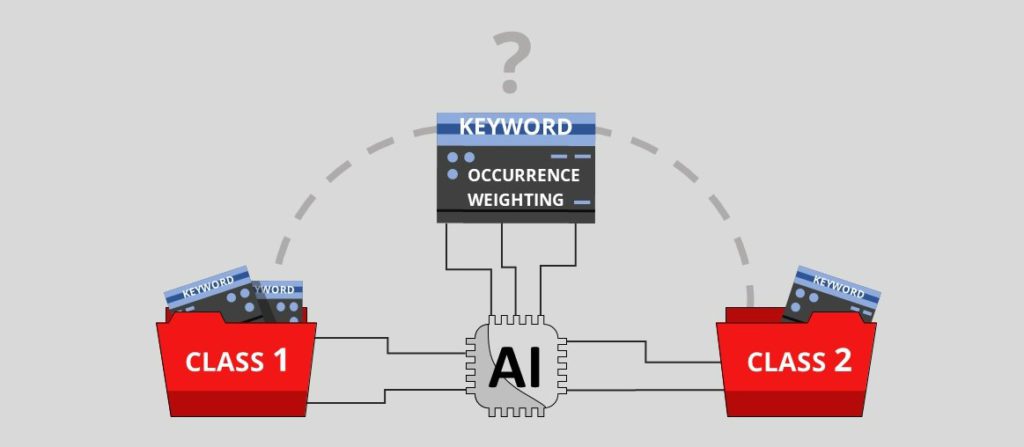
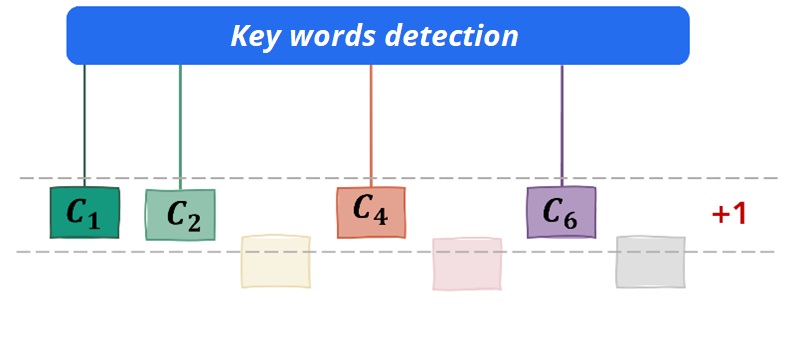
From those information, the algorithm search matching key words in the intervention query and lexicons. Then we apply a scoring through two methods.
The first method is occurrence calculation: for each matching key words, it gives a point to the concerned intervention type and the one with the biggest score will be proposed to the user.
We also use a weighting method: we attribute an importance coefficient to some words and when they appear in an intervention query they are recognized as more important to the algorithm than others words. A same word can appear in different lexicons with a different weight scores.
By mixing those two methods, the algorithm classification is more accurate.
Lexicons are built manually, but they are enriched and their weighting score is adjusted by the algorithm with an automatic learning process based on the words frequency in a class, their specificity and their original weighting score. It’s important to have well informed lexicons and the right score characteristics to obtain a precise classification.
Classification evaluation
After collecting, understanding and preparing the intervention query data, we could classify them thanks to our well-informed lexicons and to the occurrence and weighting methods. A last step but not least is the evaluation, in which we evaluate the obtained results by our methods.
The confusion matrix is a famous measuring tool in automatic learning process. It resumes the classification results as you can observe in Figure 6.

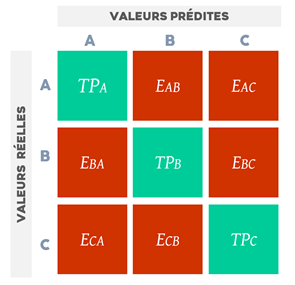
With this matrix, we can evaluate the accuracy: the number of queries well classified compared to the total number of queries; precision: the number of queries well classified or misclassified in a same class; recall or sensibility: the number of queries classified correctly in a category compared to the number of queries belonging to it; F-score: harmonic average of precision and recall.
Learning phase
To evaluate the learning performance of our solution, we collected 999 intervention queries randomly. We manually categorized them to compare our categorization to the generated result.
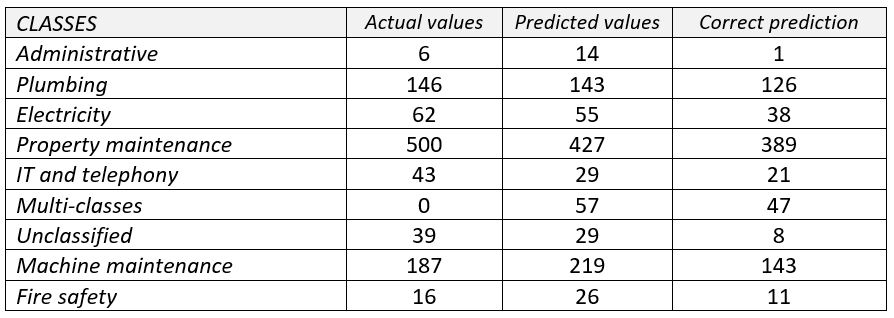
The result shows an accuracy result of 78,2% of our model. In it, there was 5,7% of multi-class intervention queries with 82,46% of them correctly categorized. We’ve noticed a really low accuracy rate in the administrative class due to the unbalanced learning data which make it generic. Though, other categories have pretty good results. The precision result is 60,6% and recall result is 61,85%.
Testing phase
To evaluate its generalization capacity, we collected 922 intervention queries from five new clients and manually classified them to compare them to the generation.
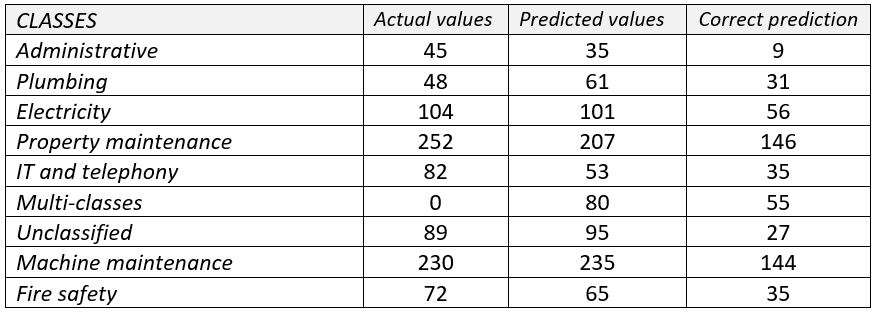
The accuracy rate came down to 58,3% on the testing phase with a precision result of 52% and a recall result of 54,8%. The model has a better supervision on some clients than others which can be explained by business area differences. These results let us notice the incapacity of our model to detect and integrate other classes than the ones already set up.
With this project, we propose a helping decision tool to assist the technical team on the intervention query processing. Our algorithm enable the intervention query automatic prequalification then propose a classification to the manager who can associate it to an actual intervention. It helps him on query flow management and schedule optimization. Our solution has good results for clear queries with specific terms thanks to the occurrence method, but it can be improved by working on lexicons and setting up a right balance between glossary to not confuse them.



