

Find about our work on SemEval task n°1: reverse dictionary
SemEval is a series of international Natural Language Processing (NLP) research workshops whose mission is to advance the current state of the art in semantic analysis and to help create high-quality annotated datasets in a range of increasingly challenging problems in natural language semantics. Each year’s workshop features a collection of shared tasks in which computational semantic analysis systems designed by different teams are presented and compared.
In this edition, SemEval proposed 12 tasks to work on.
In this article we’ll explain how our team proceed with the task n°8 of the challenge: Multilingual News Article Similarity which consisted in measuring semantic textual similarity between news articles in different languages. Our goal was to develop a system using Natural Language Processing (NLP), information retrieval methods and artificial intelligence to identify news articles that provide similar semantic information based on four characteristics: geolocation, time, share entities and shared narratives. To achieve this goal, we must identify important elements in the news articles content, such as the discussed event, location, time and people involved.
The semantic textual similarity (STS) task has been a research subject in NLP for many years, and it has been held in SemEval since several editions. But compared to others editions, this year focused in measuring similarity between long news contents and not sentences, snippets of texts or short texts.
Challenges of the task
We encountered many challenges working on this task:
- First, the content scraping of the provided URL (in the first attempt, we had empty or incomplete content in many examples);
- There was many languages to work on (some languages in the test set weren’t present in the train set);
- Finally, it was challenging to choose the type of the predicted score: decimal or integer, which is different according to the number of human annotators per document.
Data description
The data used to train was composed of 4 964 pairs of news articles written in seven different languages: English (EN), French (FR), Spanish (SP), German (DE), Polish (PL), Arabic (AR) and Turkish (TR). The pairs were formed either with the same language or with different languages. In the training corpus, seven couple types were monolingual and only one was cross-lingual (DE_EN).
For the test corpus, there was a total of 4 953 pairs of news articles in ten different languages. They added three new languages which were Russian (RU), Chinese (ZH) and Italian (IT). In this corpus, we had eight cross-lingual couple types with seven couple types that we had never seen in the train corpus.
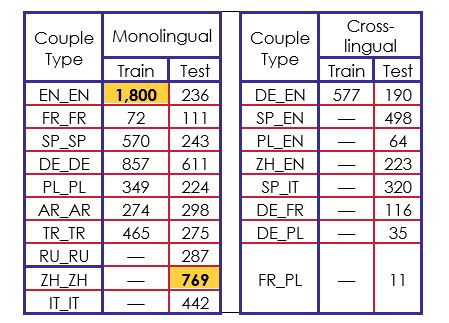
Each pair of documents was annotated by one to eight annotators based on seven score categories that were “Geography”, “Entities”, “Time”, “Narrative”, “Overall”, “Style”, and “Tone”. In addition, the organizers provided the article pairs identifiers, languages, and URLs for each pair. Using the URLs, we were able to retrieve data from the articles such as: titles, texts, keywords, tags, authors, publication date, abstracts, and meta-descriptions along with other irrelevant information.
System overview
The challenge proposed involved choosing between three options:
• Building a model for each training dataset by language: English, French, Spanish, German, Polish, Arabic and Turkish.
• Building a unique model in English (the global reference language and the best managed by NLP methods) and translating all texts into that language.
• Building a multilingual model that can handle two texts into different languages.
We have chosen to build learning models in some main languages: English, French, Spanish, German, Arabic and Turkish. We abandoned Polish language because we did not find any adequate pretrained models. When two texts to be compared were not in the same language, we translated them into the main language selected.
A fundamental point for the final score to be generated is the choice on the precision of the answer in terms of decimals. We noted that for some languages, the Overall score obtained was an integer. In English, for example, there was a decimal score and more annotators. The actual number of annotations couldn’t be determined in advance. We had therefore defined rules to complete our evaluation according to the score obtained and the language. We did not use the metadata of the news articles because they were incomplete. We simply retained both titles and text contents.
We also noticed:
- Strong correlations between the Overall score and the scores of Entities, Narrative, and Geography.
- The training dataset is unbalanced, especially in English. We had more than four scores.
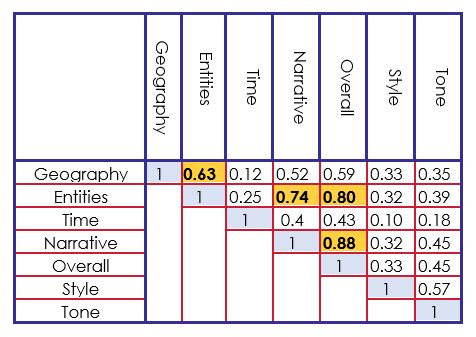
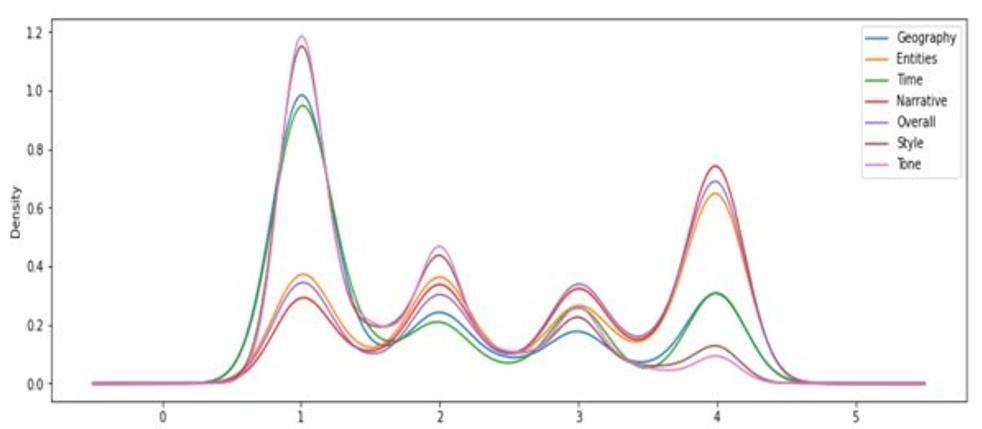
Following the observations that are seen in table 2 and figure 1, we implemented a scoring system based on each language to features to aliment a supervised system. We detail below our features:
- A similarity score of titles based on sentence transformers with a pretrained encoder model.
- We used text summarization based on pretrained transformers in each language to measure a similarity score between these summaries. We tested several models on some examples and selected those which seemed to be the best. Based on the language, we were able to obtain one or two models of summaries and thus one or two scores. The models were pretrained on different summarization corpus variants.
- We used identification and extraction of keywords/‘key terms’ in titles and content texts. The extracted tags were nouns, proper nouns, verbs, and adjectives only with stemming adding the ten semantically closest words. Then, we computed the number of common terms in both texts.
- We used identification and extraction of common named entities between titles and content texts, namely: places, persons, organizations, and dates. As for keywords and key terms, we computed the number of identical entities in both texts.
- For the various geographical detected entities (cities, regions, countries), we use the score of the proximity places with geocoding.
- We used the zero-shot classification models based on Press topics that we defined manually: politics, sport, health, economy and technology. The similarity score obtained reflected the number of common topics between two texts.
- Finally, sentiment analysis models were used to identify if the sentiment polarity is positive, negative, or neutral in both texts. The similarity score obtained thus reflected the number of common points.
With all these features, it was possible to make a final rating based on the classification or regression techniques.
For the classification, we tested Random Forest classifier and Logistic Regression for the algorithms that achieved the best performance.
For the regression, we tested Linear Regression, Partial Least Squares (PLS) and Extra Trees Regressor. That said, we could obtain a final evaluation of the selected strategy. To optimize the Pearson correlation score (the measure chosen by the organizers for the evaluation), we used PyCaret library to compare all possible models (by using cross-validation with 10 folds).
For our English model, the various elements found allowed us to have a good performance quickly (approximately 0.85 of Pearson correlation). The only concern was the strong imbalance of the training dataset that we needed to rebalance.
The French model had a poor training dataset (only 72 pair examples). Thus, we selected a more efficient NER (Named Entity Recognition) Transformer model than Spacy. We also focused on optimizing the Turkish model in the same way with an efficient NER transformer. We did not work to optimize the German model which could have be much better.
Experimental set up
We applied our scoring models to every pair of titles and content texts. For Polish language and the new languages observed in the evaluation dataset , all texts were translated into English with deep Translator library and then applied the English model. When there were two different languages, they were translated into English.
Results and analysis
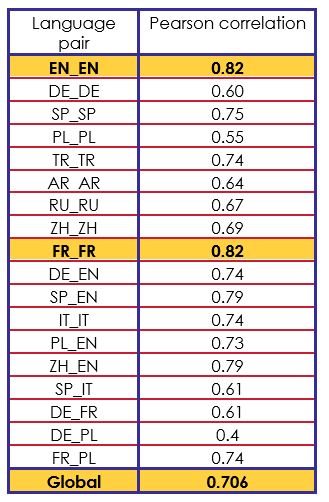
Our final Pearson correlation on the test corpus was 0.706. It indicated very irregular results depending on the pair language. Table 3 shows the obtained results on the test corpus for each language couple type.
The final result for a specific language was generally consistent with the evaluations made previously on the subset (cross-validation) of training dataset.
For the translation part, we observed a fast drift according to the languages: the ZH_EN examples translated into English remained very correct (0.79) but the ZH_ZH examples only obtained an average score of 0.69. We thus had a significant performance reduction in IT_IT (0.74) and SP_IT (0.61) compared to cases when English was used.
We found that most of the large deviations in evaluation were related to scraping errors (blank or inconsistent text).
In conclusion we observed that 71% scores of pairs were excellent (below 0.1), 84% were good (below 0.5) and 96% below 1. We believe that our English, French, Turkish and Spanish models are correct and could have been further optimized cleanly. We had technical difficulties in making a correct Arabic model, as for the German model.
Conclusion
Our system used different features reflecting the similarity that can be obtained, for example, between shared key terms and named entities, or even topics by using zero-shot learning for text classification systems. In addition, we used geolocation for location entities and measure the semantic similarity through the use of lexical embeddings at the sentence level (text title) and paragraph level (text summarizer obtained automatically by using transformers).
Beyond the use of a supervised system to measure the degree of similarity between two given texts, we were in a context of documents that can come from different languages by processing both pairs of monolingual documents and pairs of cross-lingual documents. Since the test corpus may contain documents written in natural languages not processed during learning phase, our system was able to perform an automatic translation into a pivot language in order to project new documents into already known spaces
We obtained a Pearson correlation score of 0.706 compared to the best score of 0.818 from teams that participated in this task.



