

Context
Legal monitoring is a crucial activity for legal experts in order to remain in phase with legal news. It allows them to be permanently aware of current regulations and to anticipate their future evolutions, in order to apply them as soon as possible. However, with the constant inflation of legislation, the watchdogs themselves experience an information overload that complicates their activities. It becomes very difficult for them to analyze hundreds or even thousands of articles per day and the synthesis of relevant information requires a considerable effort. Automatic summary generation therefore represents an interesting solution to help watchdogs in their legal watch activities. Abstracting approaches can be ≪ extractive ≫ or ≪ abstractive ≫. Extractive approaches return excerpts from the texts to be summarized, while abstractive approaches can formulate new sentences. Thus, abstractive approaches aim to produce summaries analogous to what watch loads produce.
In this article, we will investigate the extent to which we can apply generative language models to legal data collections, what their limitations are, and how we can evaluate the fidelity of the summary generated by them.
Data used for the experiments
For this study, we used the Légibase french data collection from Berger-Levrault. Légibase is a collection of legal and regulatory monitoring documents for local authorities and public administrations. Each document includes (a) a title, (b) a text, (c) a summary and (d) a set of metadata associated with the documents. An example of a document is shown in Figure 1. All of the information in the documents is written by experts in the field whose goal is to keep the legal information current.

LLMs used for the experiments
We have selected 4 abstract summary generation models: BART, BARThez, Bert2Bert, T5. As each of these models has been trained with generic data, generally from the web and whose vocabulary is quite far from that of the legal domain, we have proceeded to a fine-tuning step of these models on the Légibase data.
Results
In order to evaluate the performance of the models we finetuned, we used performance metrics dedicated to the automatic generation of ROUGE and BLEU summaries. These metrics compare the number of n-grams (sequence of words) in common between the reference summary produced by the experts and the summary generated by the language models. We also used a CosSim semantic similarity score that measures the semantic closeness between the reference summary and the generated summary. The results obtained are presented in Figure 2 :
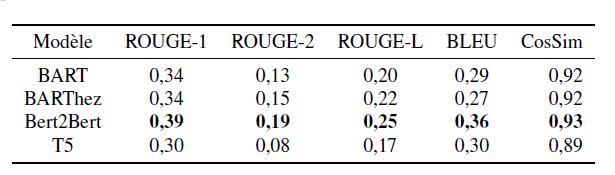
We can see from the figure of results that the Bert2Bert model stands out from the other models, followed by the two BART and BARThez models. The T5 model turns out to be the one with the worst results.
The importance of entities of interest in the evaluation of generated summaries
Specialized fields such as law, health or science in general are particularly sensitive fields, where every concept used, every proper noun or even adjective has a concise meaning. Therefore, the veracity of the information conveyed in these fields is very important. The ROUGE and BLEU scores we obtained give us a first indication of the quality of the summaries generated by the language models. However, they do not allow us to evaluate the coverage of the summaries in terms of vocabulary of interest (business vocabulary and named entities), nor do they allow us to evaluate the inconsistencies with the source document. We therefore propose to focus on a more advanced analysis of the generated summaries. We define the concept of an entity of interest, i.e., an entity related to the legal domain or a simple “named entity”. In the following, we choose to evaluate the coverage of the summaries and their inconsistencies, known as hallucinations based on the entities of interest detected in the source document and the generated summaries.
An illustration of hallucinations is proposed in the example of Figure 3 :

Metrics considered
Two types of metrics are proposed : coverage and hallucination/abstraction rate.
Let N(d), N(r), N(g) be the numbers of entities of interest present respectively in the source document d, in the reference summary r (gold standard) and in the generated summary g.
A first category of metrics concerns the coverage of the summaries :
- the coverage rate cg of the generated summaries :
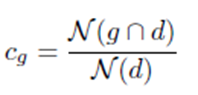
Where N(g ∩ d) is the number of d entities found in the generated summary.
- The coverage rate Cr of the reference summaries:
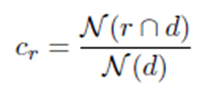
Where N(r ∩ d) is the number of d entities found in the reference summary written by the experts. Cr can be seen as a maximum achievable by the different models.
A second category of metrics is related to the appearance of entities in the generated/reference summaries, entities that were not present in the source documents. We define:
- the (extrinsic) hallucination rate h:
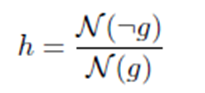
Where N(¬r) is the number of abstracted entities in r, i.e., the percentage of entities in r that are not part of the entities in d.
These abstractions can be compared to extrinsic hallucinations of the generated summaries in the sense that they do not relate to knowledge present in d. They come from the experts who made the reference summaries: the latter can indeed use their a priori knowledge to write the summaries. It is however to be noted that even if comparable to extrinsic hallucinations, the abstractions are factual, i.e. they can be considered as true, contrary to some extrinsic hallucinations.
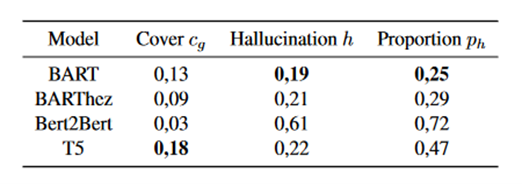
Results
The results in Figure 4 shows significant differences in the rates obtained by the different models. Although the Bert2Bert model obtained the best ROUGE and BLEU scores, it obtains the lowest coverage rate, the highest hallucination rate by far (>60%) as well as the highest proportion of hallucinated summaries. The T5 model, on the other hand, has the best coverage of the source document entities, surpassing even that of the reference summaries. Finally, the BART model has the lowest hallucination rate and hallucination proportion.
A further analysis concerned the study of coverage and hallucination rates according to the entities involved (person, organization, location and legal). Legal entities are the most hallucinated, probably due to their strong presence in the data collection. Person, organization, and location entities are hallucinated in relatively similar ways.
Finally, to examine hallucinations in more detail, we calculated a percentage intersection between hallucinated entities in the generated summaries and abstract entities in the reference summaries.
The results are presented in Figure 5. They give an indication of the factuality of the hallucinations. Once again, Bert2Bert obtains the least convincing results, in contradiction with the results of traditional metrics. However, these analyses need to be extended: without putting the hallucinated entities into context, their exact factuality cannot be deduced. They can indeed be used in a way that provokes counter-meanings or in a wrong way.

All these results confirm that a simple analysis on ROUGE and BLEU metrics is not sufficient in a business context. The Bert2Bert model, which seemed to be the best performing on the classical metrics, turns out to be the one that generates the most “uncontrolled” hallucinations. Therefore, we plan to pursue a more detailed study of the T5 and BART models.
What’s next?
This study opens up several perspectives. In the short term, we would like to continue our evaluation of hallucinations : (i) by detecting intrinsic hallucinations, and (ii) by analyzing the factuality of hallucinations as a whole.
In the longer term, the generative models can be improved along two axes : (i) limiting hallucinations, for which one avenue lies in the removal of abstractions in the reference summaries, and (ii) controlling them, by teaching the models to hallucinate factual (truthful) information. These two perspectives could lead to more accurate and reliable results in the generation of summaries in the legal domain, a business domain in which the veracity of information is crucial.



