
Introduction
In a context where the automation of data workflows has become a fundamental pillar of project reliability and scalability, Apache Airflow has established itself as an essential tool within the technical ecosystem of our BL Research team, dedicated to Research and Technological Innovation at Berger-Levrault. Whether orchestrating text document processing chains or driving transformations on IoT data, Airflow offers invaluable flexibility when properly mastered.
Two use cases embody our feedback:
- BL.Predict, an IoT platform dedicated to predictive maintenance, exploiting industrial sensor flows: airport conveyors, motors, energy meters….
- Foundation, a cross-functional service offering a search engine and intelligent assistant for several products, based on heterogeneous data from S3, API or SFTP.
This article provides technical feedback on the use of Airflow in these two projects: implementation patterns, challenges encountered, and lessons learned.
Why Airflow for these two applications?
Airflow stands out for its ability to meet several critical requirements:
- Regular scheduled batch execution, driven by flexible CRONs.
- Automatic error detection, with retry options configured on a per-task basis.
- Seamless separation of orchestration and business logic, facilitating updates without redesigning DAGs (Directed Acyclic Graph), i.e. graphs showing the dependencies between IT tasks and their execution orders.
- Scalability via Kubernetes (one pod per task, i.e. a computing unit created and managed directly in Kubernetes).
- Native support for S3, SFTP, APIs, MQTT and data formats (JSON, text, HTML).
- GitOps architecture with continuous deployment via Helm + Argo CD, driven by GitLab CI.
This combination makes it a robust and adaptable orchestrator, capable of handling both intensive processing and distributed pipelines per use case.
BL.Predict: orchestrating IoT for maintenance
BL.Predict collects and processes data from sensors deployed on industrial equipment (such as airport conveyors), via gateways, MQTT brokers, SFTP, or even public APIs (for energy consumption, for example). This data is then stored in a time-series database (InfluxDB type), used to feed maintenance-oriented business dashboards.
The pipelines implemented proved to be robust, modular and deployable on Kubernetes. They follow a classic five-step scheme: retrieval, validation, transformation, prediction and export. Prediction is based on expert rules or upstream-trained anomaly detection models. An example: detecting abnormal vibration deviations or temperature anomalies on industrial equipment motors.
However, some use cases required near-real-time processing (less than a minute), which highlighted Airflow’s limitations in this type of scenario. Indeed, the execution mode on Kubernetes, where each task triggers a new pod, introduces a latency that is difficult to avoid, especially for very short tasks. An alternative might have been to use a more event-driven orchestrator, but Airflow’s rich functionality and mature ecosystem were deemed more relevant to this project at this stage.
The multiplication of dynamic DAGs per equipment or per site is another critical point: each specific flow or hardware configuration requires a dedicated, dynamically instantiated DAG. This reinforced the need for a strict framework of governance and standardization (names, variables, logs). Finally, the volume of logs generated by the frequent execution of technical tasks requires centralization and archiving on S3.
Foundation: Intelligent assistant and cross-functional search engine
The Foundation project aims to structure documents from different sources (S3, SFTP, APIs) for several in-house products. These documents are sometimes semi-structured (HTML, JSON), sometimes raw (text files, PDF extracts). The aim is to make them usable in a cross-functional search engine and an intelligent assistant based on LLM.
The pipeline applies a series of operations: collection, synthaxic analysis (also known as “parsing”), enrichment via language model (adding metadata), segmentation, calculation of vector embeddings, then export to a vector store or semantic engine (such as Weaviate).
We have adopted an approach based on template DAGs instantiated dynamically via JSON configuration files. Each configuration defines the type of source, the parser to be used, the output points, and so on. This makes it possible to maintain a single code base for multiple workflows, while allowing a high level of business specialization.
Intermediate data is stored on S3 between each task, in order to decouple execution and avoid the limitations of XCom. This approach enabled us to maintain a certain degree of robustness, but also introduced the complexity of managing intermediate states (cleaning, versioning).
We also had to deal with the management of updates, additions and deletions in document sources, to avoid reprocessing the entire corpus at each launch. This need is gradually pushing us towards a more event-driven logic, although this has not yet been implemented.
Finally, parallelism management is a key point: the aim is to make the most of available Kubernetes resources, without running costly sequential pipelines. We are currently working on fine-tuning processing and gradually integrating Dynamic Task Mapping, which will enable tasks to be automatically parallelized on a list of documents or logical units, while keeping DAG simple to maintain.
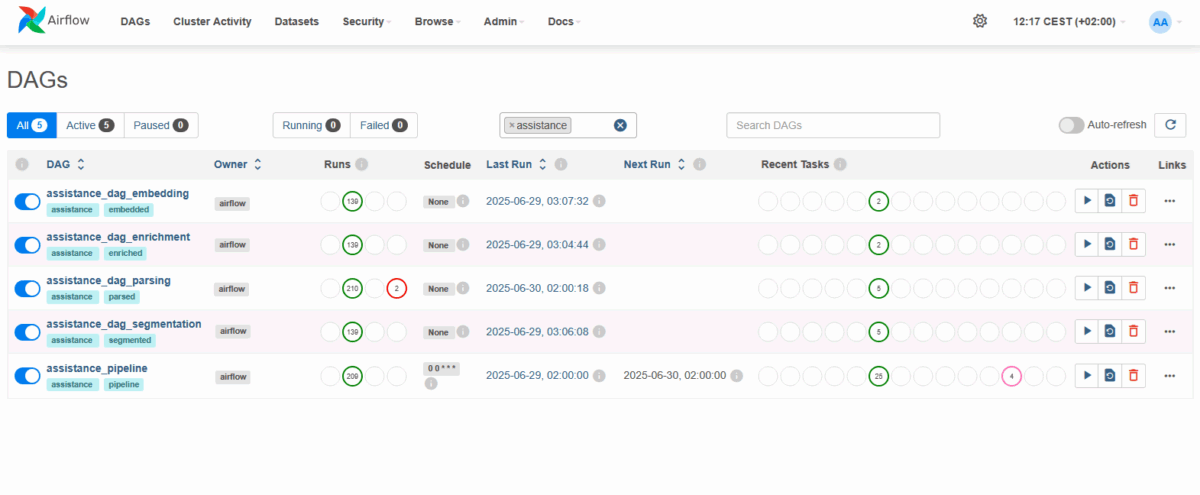
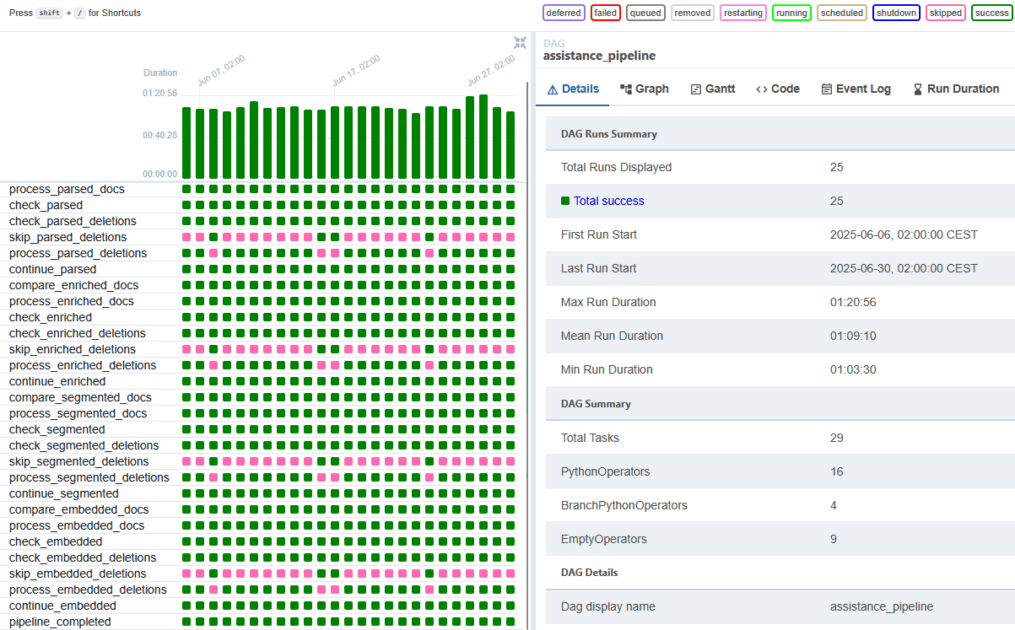
Best practices, environment and recommendations
Our technical stack is based on a coherent combination of building blocks: Kubernetes, S3 for storage, GitLab CI/CD for build and test pipelines, Argo CD for GitOps deployment, and Airflow as a runtime orchestrator. All DAGs are deployed automatically from validated branches, with injection of sensitive information (so-called “secrets”) via environment variables and strict separation of environments (dev, uat, prod).
Standardization of logs (format, naming, trace identifiers, storage in S3) has enabled us to create a common basis for observability. At the same time, the use of reusable business Python services has enabled us to keep our orchestrator code simple, clean and testable.
Dynamic Task Mapping is proving to be a promising way of finely parallelizing workflows without artificially generating dozens of manual tasks. This approach will be systematized over the next few months, particularly for case studies linked to mass document processing.
Conclusion
Our feedback on Airflow, applied to two very different projects such as BL.Predict and Foundation, shows that it is possible to mutualize an orchestrator for a variety of cases, while respecting the specific constraints of each domain: frequency, formats, scalability, parallelism.
The keys to success were structuring the code around injectable services, using dynamic DAGs driven by JSON files, externalizing intermediate data to S3, and continuously exploiting Kubernetes capabilities via a controlled GitOps approach.
For the future, we’re aiming for better support for events, the extension of Dynamic Task Mapping, and improved supervision thanks to more advanced observability tools. Airflow isn’t perfect, but today it remains a robust foundation for industrial orchestration of our most critical workflows.



