Hoy en día, las sociedades evolucionan a gran velocidad. Esta evolución implica cambios en nuestras herramientas. Es el caso de los programas informáticos, deben evolucionar y mantenerse actualizados para responder a nuestras necesidades. Pero, ¿cómo asegurarse de que el software responde a nuestras necesidades a pesar de la evolución? Una forma popular y eficaz son las pruebas. Una prueba comprobará el comportamiento de un software para detectar posibles errores y asegurarse de que se ajusta a las expectativas. En este artículo nos centraremos en las pruebas funcionales antes de lanzar un software. Estas pruebas se realizan con varios escenarios que se componen de secuencias. Cuando la secuencia llega a su fin, produce un valor añadido de negocio que se compara con las expectativas del probador.
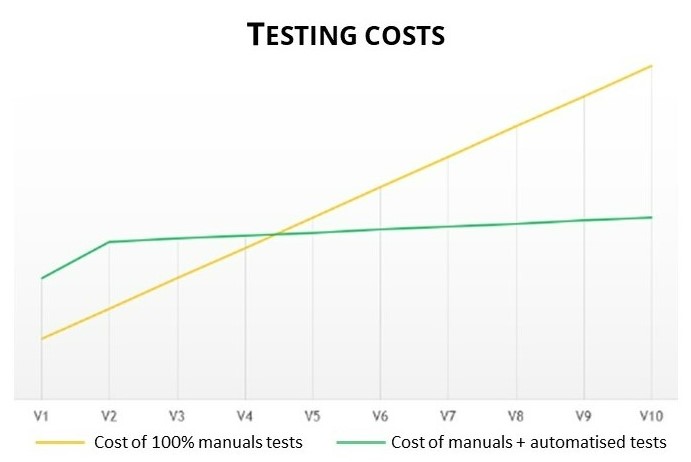
Cuando un software está compuesto por distintos componentes, es humanamente imposible realizar pruebas porque el número de escenarios es demasiado importante debido a las interacciones de los distintos componentes, así que no se prueban todos los escenarios. Otro punto importante es el coste de mantenimiento para mantener el software actualizado. Por eso los buscadores han intentado automatizar una parte de esas pruebas. Como se puede ver en el Figura 1La automatización ha reducido considerablemente los costes de mantenimiento en el tiempo.
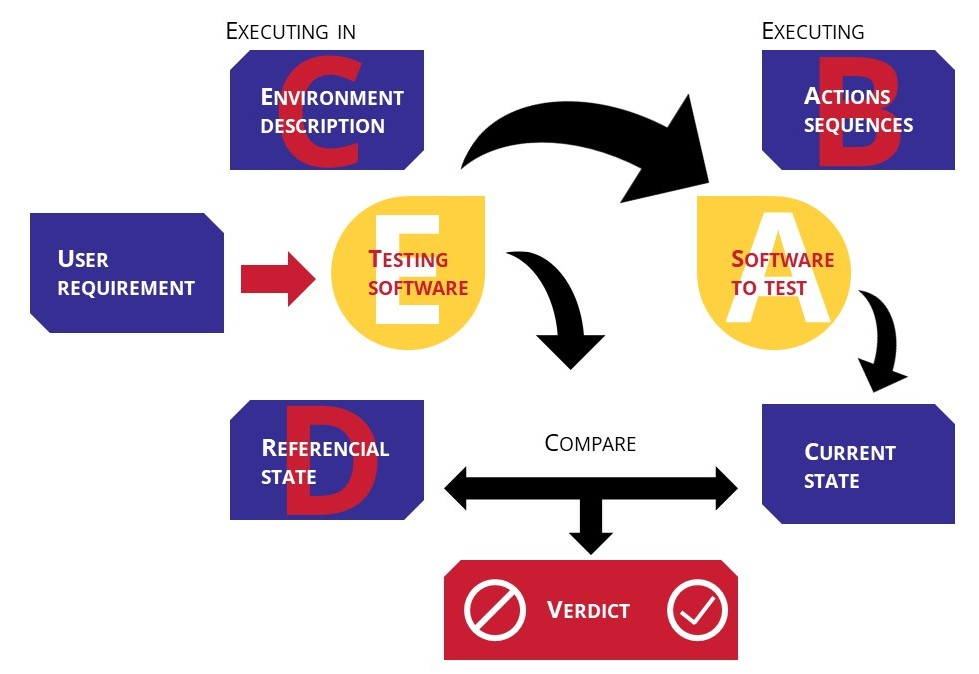
Los últimos avances en Inteligencia Artificial brindan nuevas oportunidades a las pruebas de hiperautomatización. El objetivo es crear un sistema de software genérico casi autosuficiente capaz de verificar el comportamiento de un software. Para funcionar, el comprobador del sistema de software necesitaría estar compuesto con diferentes datos (figura 2):
A. Un software para probar,
B. Secuencias de acción a realizar. Estas acciones serán los datos que introduzca el software de pruebas,
C. Datos contextuales y técnicos que describen el entorno en el que evoluciona el software probado,
D. Un estado referencial (acorde con la expectativa),
E. Un evaluador capaz de comparar el estado del resultado de la prueba con el estado referencial para interpretar el resultado y emitir un veredicto.
Se trata de un ambicioso objetivo, ya que la inteligencia artificial tendría que generar de forma independiente todos los datos de la lista en lugar del software probado (A). Hoy en día no se ha creado una inteligencia artificial capaz de hacerlo.
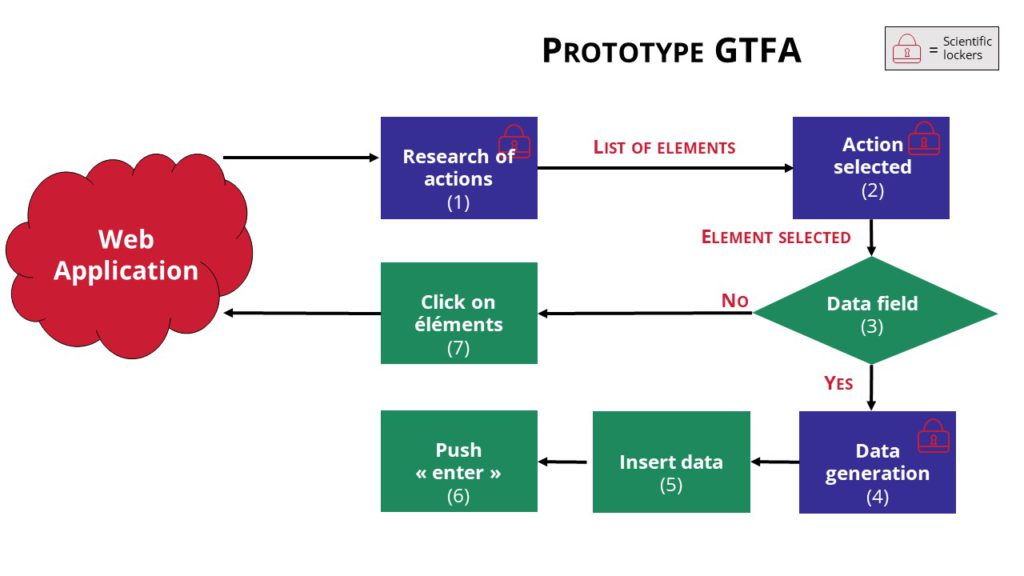
Para iniciar este proyecto, decidimos simplificarlo y trabajar únicamente en un comprobador de software (E) capaz de explorar otro software de forma automática. Supusimos que: la evaluación de la prueba es el número de estados que ha explorado el software (cuantos más estados explore, mejor será). Significaría que el software puede probar secuencias de acción aún no probadas con escasa manipulación humana.
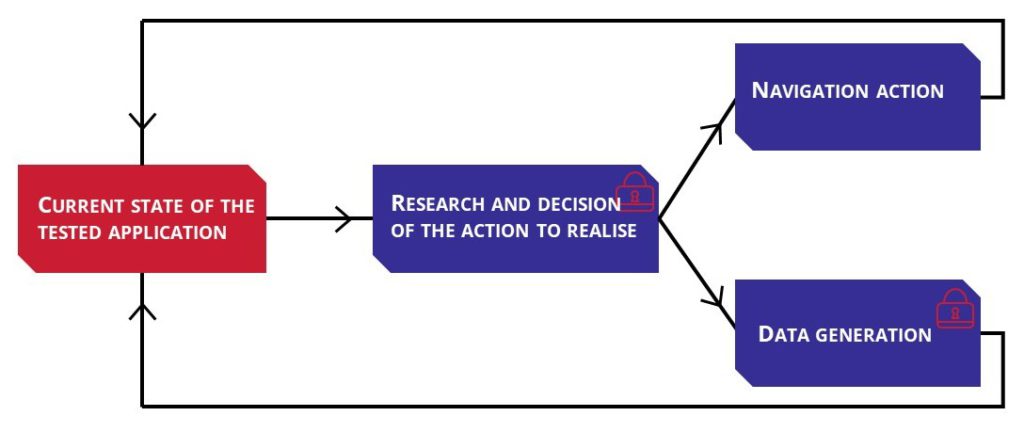
Para "explorar" el otro software (A), el probador (figura 3) tendrá que determinar primero la acción a realizar. Este primer paso puede considerarse un "casillero" porque, a pesar de la investigación, aún no se ha resuelto. En la segundo paso, el probador tiene dos posibilidades: generar datos (que presentan otra taquilla) y acción de navegación (hacer clic en un botón, por ejemplo). Si no puede generar datos, intentará una acción de navegación y luego determinará si el estado del software probado ha cambiado y razonará por sí mismo sobre qué hacer a continuación. Esto simplifica el problema, pero no lo hace más fácil.
El estado del arte
Las generaciones de buscadores han trabajado en este problema a dos niveles diferentes:
1st A nivel industrial (enumera herramientas y framework utilizables por todos) con un enfoque directo. Deduce que el código no es el lenguaje más fácil de interpretar por todo el mundo, trae bugs y un coste importante de mantenimiento por lo que semi-automatizan las pruebas para ganar tiempo en ello. Esta solución es eficaz en sistemas informáticos pequeños o medianos.
En el segundo nivel, el enfoque es menos directo. En primer lugar, se deducen conocimientos sobre el software probado y se introducen en un método elegido más o menos inteligente como Minería web o Probador de monos pero esos métodos no generan datos.
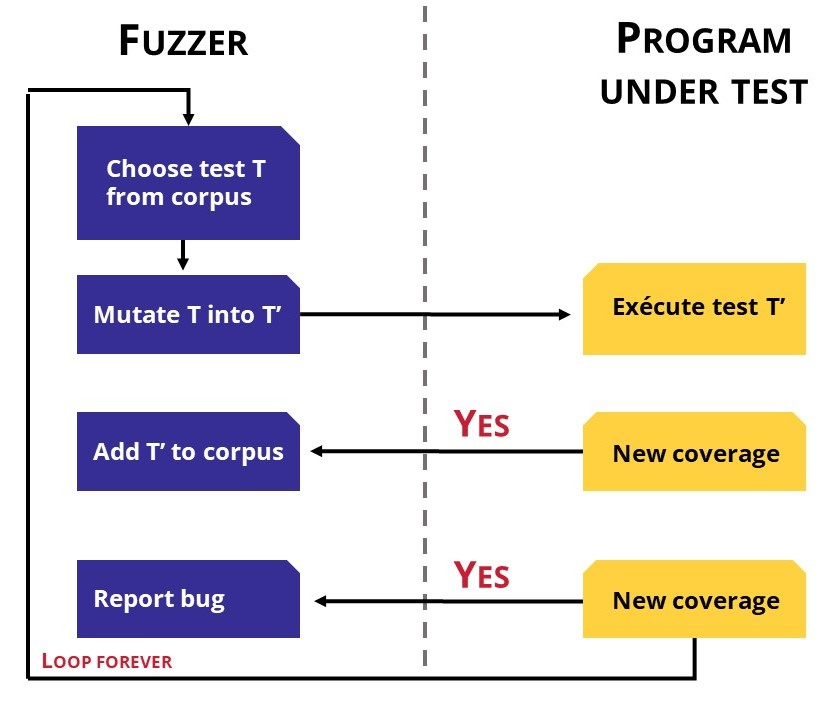
Para crear una aplicación inteligente de búsqueda, es necesario generar datos. Un enfoque científico son las pruebas fuzzer. El fuzzer generará a partir de una semilla. Algunos de ellos generan datos aleatorios (figura 4)otros aprenderán por su cuenta. Por ejemplo, si los datos generados llegan a un nuevo estado, los datos se añadirán a la prueba de datos pero si el estado resultante en un error, se informa del fallo. Pero este método no tiene en cuenta el entorno empresarial.
Otro tipo de fuzzer basado en inteligencia artificial como Evolutionary-Based fuzzer mejorará algún paso con Machine Learning y añadirá conocimiento de la profesión en el proceso.
Las soluciones de aprendizaje automático como Q-Learning, la red de neuronas o GAN (Generative Adversarial Network) también son buenas pistas a seguir.
El estudio del estado del arte científico muestra métodos de generación automatizada. Aunque esos métodos son adaptables de una aplicación a otra, no tienen en cuenta mucha información sobre la dimensión empresarial. Así que la exploración no genera un escenario empresarial coherente. Una solución sería introducir preconceptos empresariales para generar escenarios y datos más coherentes. Sin embargo, la preconcepción empresarial es difícilmente enumerable en sistemas de software complejos.
Esta conclusión sobre el estado del arte existente, nos llevó a dirigir un estudio sobre la concepción de un prototipo que respondiera a la problemática. El método que utilizamos expuso al máximo nuestro prototipo a las taquillas identificadas.
Detección y selección de elementos procesables
Basamos nuestro proyecto en una aplicación web existente de tamaño medio.
La interacción automática se ha hecho posible con un programa especial (en nuestro Selenium) capaz de actuar sobre la HMI (Human-Machine Interface) - como hacer clic o escribir texto. (figura 5).
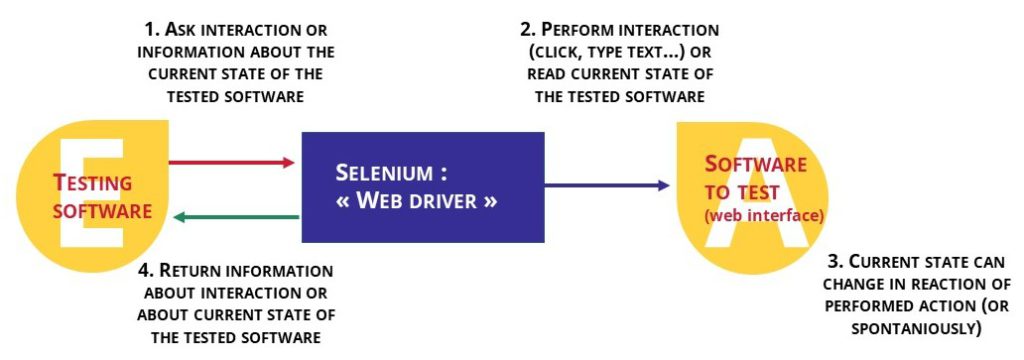
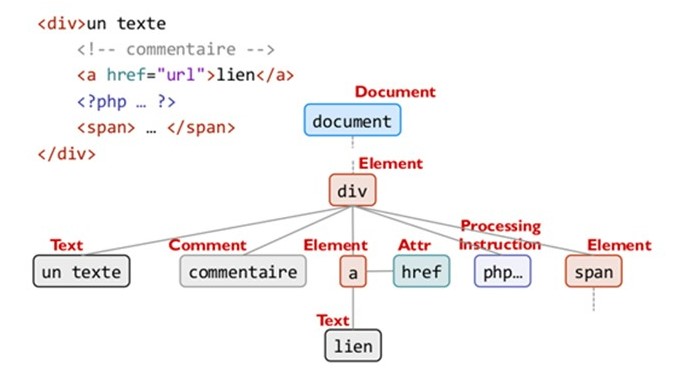
También puede leer el DOM (Document Object Model) (figura 6) y detectar las posibilidades de acción en la página web.
Cuando se pulsa un botón de la página, se produce un evento que cambia el estado del DOM (es decir, de la página web). A través del DOM, encontramos una forma sólida de determinar si un elemento del DOM provocará un evento o no. Una vez que todos los elementos procesables han sido detectados en el DOM, uno es activado por Selenium. Su activación eventualmente modificará el DOM, entonces comienza una nueva investigación de elemento accionable. El programa calcula una impresión del DOM original, luego registra todas las versiones del DOM generadas para reconocer el estado del DOM ya encontrado y no repetir una misma acción. Si el DOM se compone de datos profesionales, la exploración se orientará escenario.
Este método es una buena forma de detectar todas las acciones posibles, pero muestra sus límites. A veces, las acciones enumeradas no pueden activarse por diferentes motivos:
- Aunque sea visible, un elemento puede estar parcial o totalmente cubierto por otro. (véase la figura 7)
- El elemento está fuera de la pantalla
- El elemento es demasiado pequeño
Parte de esos casos se gestionan automáticamente. Por ejemplo, en el caso de elementos superpuestos, el clic puede ser interceptado por un elemento padre. El resultado es un error. Sin embargo, no se gestionan todos los casos (como los elementos externos) y la gestión tarda más en procesarse.
Como no se puede actuar sobre todos los elementos visibles, hemos añadido un análisis visual al análisis DOM. Cada elemento del DOM se colorea para definir una zona a la que atribuir el clic. La combinación de los dos métodos permite detectar todos los elementos accionables y determinar si son accionables en la zona en la que se encuentra el analizador.
En algunos casos, el análisis del DOM muestra sus límites. Con algunos Framework (como ReactJS) que no alimentan su DOM como es habitual sino que utilizan sus propios modelos de eventos. La nueva tendencia dinámica de la aplicación web hace que el análisis sea muy difícil ya que el DOM siempre está cambiando. No trabajamos en el caso del scroll en nuestro estudio, pero aporta una fuerte complejidad combinatoria, y requeriría una mejor sinergia entre el DOM y los análisis visuales.
Generación de datos
Trabajamos en la generación de datos mediante inteligencia artificial. Nos cuestionamos cómo ayudaría a generar suficientes datos profesionales. Cruzamos los datos generados por fuzzer con los del Q-Learning.
En esta arquitectura (figura 8) el fuzzer genera a partir de semillas implementadas ya seleccionadas por el Q-Learning. El Q-Learning basa su elección en datos contextuales de la aplicación. Por ejemplo, si detecta un campo "nombre", el Q-Learning lo asociará a una semilla "textual". La función de recompensa del algoritmo (que le permite aprender de su experiencia) se basa en la validación o el rechazo del formulario.
De nuestro estudio del estado de la cuestión, podemos concluir que es muy difícil crear una solución hiper-automatizada capaz de ser versátil en diferentes niveles y entornos empresariales. Para ello, hay que resolver diferentes casilleros científicos: determinar la acción a realizar, generación de datos, detección de un nuevo estado.
Aunque el análisis DOM se combina con un análisis visual es interesante determinar con precisión la acción realizableaunque siga habiendo problemas (el desplazamiento, por ejemplo).
Es muy difícil crear un software genérico sin tener en cuenta los requisitos del usuario, ya que los sitios web se construyen de formas diferentes.
A través de nuestro estudio hemos aprendido sobre la tendencia de las herramientas de comprobación existentes y los diferentes enfoques de análisis. Teniendo en cuenta los principales casilleros científicos identificados, no pudimos encontrar una respuesta satisfactoria, pero vamos a recordar nuestro estudio del estado de la técnica y el conocimiento crucial para nuestro trabajo futuro.