

Historically, Berger-Levrault has been a publisher of legal and practical books and articles. The articles are on line and come from Légibases1. Exploiting the knowledge contained in these texts is difficult. This is why it is necessary to structure the knowledge so that it can be accessed quickly. Berger-Levrault develops software solutions specialized in Automatic Natural Language Processing (NLP), such as a document search engine, an automatic response generation engine, a legal watch automation and many others. These software solutions need to exploit Berger-Levrault’s knowledge of textual data. Until now, however, they have been limited by the ability to browse the entire raw knowledge. It is therefore necessary to structure this knowledge so that it can be used to enrich business applications and thus improve them. To achieve this, two aspects are highlighted: (1) Representing all knowledge through a knowledge structure; and (2) Using this knowledge to improve the performance of several Berger-Levrault software products.
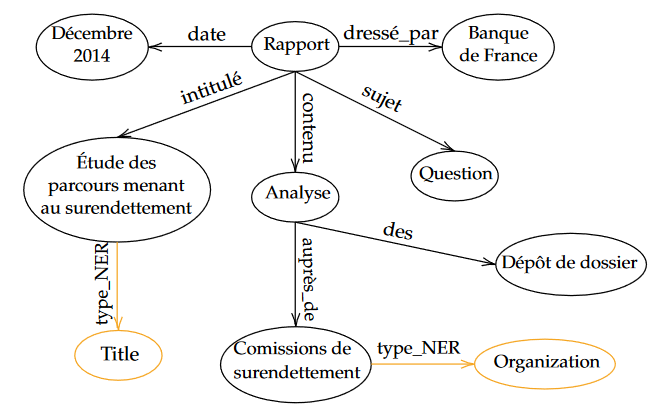
En décembre 2014, un rapport a été dressé par la Banque de France au sujet de la question préoccupante du surendettement. Justement intitulé “Étude des parcours menant au surendettement”, il nous livre une analyse en amont des dépôts de dossiers auprès des commissions de surendettement.
The example above is a paragraph from a text (article/book) from Berger-Levrault. The aim is to transform this text into a structure as shown in diagram 1 (below). The fact that we are interested in texts leads us to take into consideration the fact that nothing exists beforehand, i.e., no knowledge structure is pre-existing, and that it is necessary to build this structure from the text itself, i.e., the terms of the text, i.e., the terminology. It is important to bear in mind the lexical and semantic purpose of text structuring, i.e. that this structuring of knowledge will be used by Berger-Levrault to guide its NLP applications. These lexical and semantic notions are provided by the links between words.
Scientific background
Information extraction : Definition
Information extraction is the automatic task of extracting structured information from unstructured documents in a restricted domain. It involves converting plain text into a structured form of knowledge.
Extracting information from plain text into structured data formats involves three types of sub-tasks: entity-relation-entity (ER) triplet extraction, key term extraction and, more specifically, named entity recognition (NER) and, finally, Event Extraction (EE), which we won’t cover in this article.
“Yesterday, New York-based Foo Inc. announced the acquisition of Bar Corp.”
Extracted information: MergerBetween(company1, company2, date)
company1 = Foo Inc.
company2 = Bar Corp.
date depends on the date of the article from which the sentence is taken
The previous example represents an information extraction from a sentence taken from news feed reports on corporate mergers. We can see that two types of information have been extracted: the “MergerBetween” relationship (relationship extraction) and the terms or entities (terminology extraction) that make up this relationship, namely the companies (company1 and company2).
We can identify three main construction stages, each dependent on the other. The first is to extract the terminology that will later represent the concepts. The second is to extract relationships. Several types of relationships can be identified. In order to group terms together into concepts, we need to identify hierarchical and synonymous relationships between our terms. Next, we want to extract semantic relations. This can be the same approach if the relations are well defined, i.e. we have prior knowledge of the types of relations and this set of types is finite. In many cases, it’s a matter of extracting pairs of candidate terms and classifying them to a given type among those specified upstream.
Finally, a rule application step is necessary to make inferences or to validate the consistency of the knowledge structure. Indeed, when adding information, it is necessary to check that it is correct and does not contradict any other information.
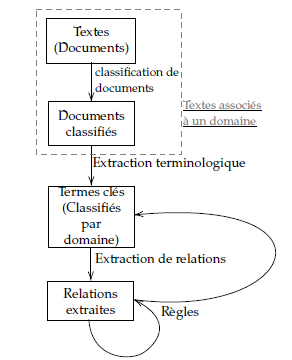
We can therefore draw a general system whose architecture is shown in the figure above (see diagram 2). We will detail them at the following points:
- Based on the raw text from the documents, we classify them in one of the 8 sub-domains offered in Légibases, namely : Civil status & cemeteries, Elections, Public procurement, Urban planning, Local accounting and finance, Territorial human resources, Justice and health (État civil & cimetières, Élections, Commande publique, Urbanisme, Comptabilité et finances locales, Ressources humaines territoriales, Justice and santé in french)
- We go through each paragraph to extract the key terms and link them to a given domain. This not only enables us to fill in the graph as explained above, but also to filter relationships by domain, so that we can concentrate on relevant information and adapt to one domain at a time.
- The relationships between these key terms can be extracted, whether they are of a specific type or based on text.
- The rules will be able to update the set of key terms and relationships by deleting erroneous or obsolete information or adding inferred information.
In this article, we focus on the information extraction part only, i.e. terminology extraction (of key terms) and relation extraction, as explained in the following sections.
Terminology extraction
Terminology extraction: definition
Terminology extraction (or sometimes terminology identification) consists in automatically extracting relevant terms from a given corpus of texts. This can take various forms, such as relevant themes, main text segments or even main or lemmatized words. The Berger-Levrault texts are legal and practical books and articles from a variety of sectors. We can compare this corpus grouping to a garde manger for a chef. Just as a chef would select the right ingredients for a recipe from a particular country, terminology extraction involves extracting the right terms from texts for a particular task in a particular field.
Generally speaking, automatic terminology extraction approaches extract terminological candidates, i.e. syntagms that are syntactically plausible, e.g. by sentence splitting.
Candidates are then filtered using statistical and machine-learning methods. Terminology extraction involves extracting a list of relevant terms associated with a specific domain. The aim here is to get rid of the superfluous by searching for less common but more relevant terms, and then to supplement this extraction with synonyms using other resources.
By selecting the most relevant and significant key terms, terminology extraction enables you to focus on the essential information. A notion of structure is naturally created by identifying conceptual terms and the other terms associated with the concept.
Experts’ annotations
The books and articles in the Berger-Levrault corpus are partially annotated by experts in the field. An expert in one of the 8 sub-domains processes a document or article and goes through each paragraph one by one, choosing whether or not to annotate it with one or more terms. The example below shows the annotations made by experts on a given paragraph. The experts’ annotations have been bolded and italicized in the associated text by a human, so as to make intuitive processing to match, not what is obtained directly with the system.
Les communes dotées d’un plan d’occupation des sols rendu public ou d’un plan local d’urbanisme approuvé peuvent, par délibération, instituer un droit de préemption urbain sur tout ou partie des zones urbaines et des zones d’urbanisation future délimitées par ce plan, dans les périmètres de protection rapprochée de prélèvement d’eau destinée à l’alimentation des collectivités humaines définis en application de l’article L. 1321-2 du Code de la santé publique, zones et secteurs définis par un plan de prévention des risques technologiques en application de l’article L. 515-16 du Code de l’environnement, dans les zones soumises aux servitudes prévues au II de l’article L. 211-12 du même code, ainsi que sur tout ou partie de leur territoire couvert par un plan de sauvegarde et de
Droit de préemption urbain, Préemption, Risque naturel et/ou technologique, Secteur sauvegardé, zone, zone d’aménagement concerté, d’urbanisation future
mise en valeur rendu public ou approuvé en application de l’article L. 313-1 lorsqu’il n’a pas été créé de zone d’aménagement différé ou de périmètre provisoire de zone d’aménagement différé sur ces territoires.
Expert annotations are manual, and experts do not hold a reference lexical resource at the time of annotation. Experts therefore annotate differently. Key terms have been described with several inflected forms and sometimes with additional irrelevant information such as determiners (e.g. “des frais” in other paragraphs). A key term groups together all the arrow-form annotations into a single representative form.
We’ve collected all the experts’ annotations. From the various inflected forms, we want to move on to this representative form known as the “key term”. To do this, we’re going to pre-process the data in order to unify them.
- The first step is to eliminate the first tool words (determinant, for example).
In the concrete example “de participation de zones d’aménagement concerté”, the annotation is transformed into “participation de zones d’aménagement concerté”. - Then, based on these elements, we want to unify the annotations of the same identifier under a single representative key term called referent: a single form for terms with the same identifiers but different arrow forms. For example, “de restauration immobilière”, “restauration immobilière” and “Restauration immobilière” all refer to the same key term. In order to construct an identifier for a given term that has already passed through the first stage, we lemmatize all the words that make up this term. This identifier is only used to find all the different inflected forms of the same identifier. In order to choose the right representative, we have divided our problem into two cases: simple terms (words) and complex terms. In the case of complex terms, we have chosen to take the inflected form with the highest number of occurrences in the corpus. To do this, a statistical analysis is performed on the entire corpus to calculate the number of occurrences of each annotation. In this way, the most frequent form represents the surrogate that can refer to a given key term. For simple terms, we prefer a standard canonical form, as we wish to favor the singular and generic form over the plural form.
However, as mentioned above, the matching was done manually, since a great deal of pre-processing, often multiple, had to be done. For example, in our case, “Risque naturel et/ou technologique” was matched with “risque technologique”. However, many other cases exist, making it difficult to pre-process these annotations. Expert annotations are therefore not present in the associated text. This may be due to the fact that the term requires pre-processing, as in the previous case, but it may also be due to a key term that is too long, rendering it unusable, or it may be due to a theme associated with the paragraph.
Let’s go back to the previous example. Here, we’re going to represent the words that we would consider intuitively relevant by putting them in bold, while keeping the annotations in italics. These are the terms that a human might select as interesting in the text to form a general idea of the text.
Les communes dotées d’un plan d’occupation des sols rendu public ou d’un plan local d’urbanisme approuvé peuvent, par délibération, instituer un droit de préemption urbain sur tout ou partie des zones urbaines et des zones d’urbanisation future délimitées par ce plan, dans les périmètres de protection rapprochée de prélèvement d’eau destinée à l’alimentation des collectivités humaines définis en application de l’article L. 1321-2 du Code de la santé publique, zones et secteurs définis par un plan de prévention des risques technologiques en application de l’article L. 515-16 du Code de l’environnement, dans les zones soumises aux servitudes prévues au II de l’article L. 211-12 du même code, ainsi que sur tout ou partie de leur territoire couvert par un plan de sauvegarde et de
Droit de préemption urbain, Préemption, Risque naturel et/ou technologique, Secteur sauvegardé, zone, zone d’aménagement concerté, d’urbanisation future
mise en valeur rendu public ou approuvé en application de l’article L. 313-1 lorsqu’il n’a pas été créé de zone d’aménagement différé ou de périmètre provisoire de zone d’aménagement différé sur ces territoires.
Here, when we compare the words in bold with those in italics, we see that this paragraph is sorely lacking in information. In fact, the expert annotates the paragraph with a view to giving a brief summary of the entire paragraph, not with a view to giving the relevant terms in the text. Naturally, when we compare the paragraph with the terms that a human could select as relevant in the text to form a general idea of the text against the annotations, we notice a large difference. To reinforce this idea, Table 1 describes for a given domain: the number of expert annotations, the number of articles for that domain and the number of key terms that it was possible to extract from the expert annotations (with the percentage of loss). We can thus see that there is a lot of loss and few key terms for all the articles. Books have not been taken into account in order to filter by field. In fact, Légibases articles are categorized by field, which is not the case for books. It should be noted that these figures were collected in 2020 and have evolved since then. However, they remain interesting to support the fact that expert annotations are not sufficient for information extraction.
| Domains | Number of key terms | Number of articles | Number of annotations |
| Civil status & cemeteries (État civil & cimetières) | 642 (29.6% remaining) | 2 767 | 2 169 |
| Elections (Élections) | 108 (72% remaining) | 152 | 150 |
| Public procurement (Commande publique) | 876 (72.9% remaining) | 1 354 | 1 201 |
| Urban planning (Urbanisme) | 327 (59% remaining) | 1 357 | 554 |
| Accounting and local finance (Comptabilité et finances locales) | 981 (50.1% remaining) | 1 971 | 1 957 |
| Local human resources (Ressources humaines territoriales) | 122 (41.6% remaining) | 361 | 293 |
| Justice | 870 (60.1% remaining) | 3 980 | 1 447 |
| Health (Santé) | 491 (59.2% remaining) | 896 | 830 |
We therefore had two options: to exploit these exceptions among the experts’ annotations by making a similarity between the terms in the text and the annotations in order to group them together, or to add textual information by developing a terminology extractor based on textual content.
In order to add textual information, we turned to a terminology extractor, which we present in the next section.
InfoGlean KeyTerms
InfoGlean KeyTerms is the name given to the terminology extractor we have developed. This extractor is divided into three subsystems:
- Named entity recognition (NER): This is the task of identifying specific named entities in a text and then categorizing them into predefined categories such as people, places, organizations, dates and many more. Named entities are concrete elements of the text that have particular importance, often being proper nouns.
Typically, a NER system consists of two steps: the identification of named entities and the labeling of entities in each of the previously defined categories. We use a fine-tuned CamemBERT model for the NER task named “CamemBERT-NER” and extended with additional labeling for dates2. - Relevant term extraction – also known as keyphrase / keyword extraction – involves extracting important terms (simple or complex) from a text. These key terms help to identify the subject of a document. We have chosen to use the ChatGPT API. The following is an example of a prompt used in ChatGPT to extract relevant terms. This prompt has been pared down, omitting parameters to filter and format the output.
Consider the following text in french: "Les communes dotées d’un plan d’occupation des sols rendu public ou d’un plan local d’urbanisme approuvé peuvent, par délibération, instituer un droit de préemption urbain sur tout ou partie des zones urbaines et des zones d’urbanisation future délimitées par ce plan, dans les périmètres de protection rapprochée de prélèvement d’eau destinée à l’alimentation des collectivités humaines définis en application de l’article L. 1321-2 du Code de la santé publique, zones et secteurs définis par un plan de prévention des risques technologiques en application de l’article L. 515-16 du Code de l’environnement, dans les zones soumises aux servitudes prévues au II de l’article L. 211-12 du même code, ainsi que sur tout ou partie de leur territoire couvert par un plan de sauvegarde et de mise en valeur rendu public ou approuvé en application de l’article L. 313-1 lorsqu’il n’a pas été créé de zone d’aménagement différé ou de périmètre provisoire de zone d’aménagement différé sur ces territoires."
Give me the relevant terms in this text.
- Extracting legal entities involves extracting entities from a text in the same way as for NER, but related to the legal domain only. We have observed five different types of legal entity: Law, Article, Proposal, Decree, Other. We use Nihed Bendahman’s system for extracting entities of interest, i.e. both legal entities and named entities. This system is based on REGEX-based rules.
We take the previous example and apply the combination of these systems (the three different InfoGlean KeyTerms extractions), representing them by their respective colors superimposed on the experts’ annotations.
Les communes dotées d’un plan d’occupation des sols rendu public ou d’un plan local d’urbanisme approuvé peuvent, par délibération, instituer un droit de préemption urbain sur tout ou partie des zones urbaines et des zones d’urbanisation future délimitées par ce plan, dans les périmètres de protection rapprochée de prélèvement d’eau destinée à l’alimentation des collectivités humaines définis en application de l’article L. 1321-2 du Code de la santé publique, zones et secteurs définis par un plan de prévention des risques technologiques en application de l’article L. 515-16 du Code de l’environnement, dans les zones soumises aux servitudes prévues au II de l’article L. 211-12 du même code, ainsi que sur tout ou partie de leur territoire couvert par un plan de sauvegarde et de
Droit de préemption urbain, Préemption, Risque naturel et/ou technologique, Secteur sauvegardé, zone, zone d’aménagement concerté, d’urbanisation future
mise en valeur rendu public ou approuvé en application de l’article L. 313-1 lorsqu’il n’a pas été créé de zone d’aménagement différé ou de périmètre provisoire de zone d’aménagement différé sur ces territoires.
Relation Extraction
Relation extraction: Definition
Relation extraction is a Natural Language Processing (NLP) task that aims to identify and classify semantic relations between entities in a text. For example, given the sentence “Barack Obama was born in Hawaii”, relation extraction can extract the relation place_of_birth (Barack Obama, Hawaii) from the text. Relation extraction can be used to extract information from a variety of sources, such as news articles, social networking posts, scientific papers or web pages, and organize it in data structures.
Different types of relationships can be extracted from text, depending on the level of specificity, granularity and domain. Named entity relations are between named entities, such as people or places. For example (president_of, Joe Biden, USA). Semantic role relations refer to relations between a predicate and its arguments, such as (agent, manager, John) or (patient, eat, apple). Ontological relations are those that belong to a schema, such as hyperonymy or hyponymy (subclass_of, dog, animal) or (has_Color, Apple, Red). All these types of relations provide valuable information about the text. These are well-defined types of relations that are frequently reused, such as synonymy, equivalence, hierarchy and association. However, this requires each type to be defined in advance, and if there are many to be determined, this requires manual effort. Another form of relationship extraction exists. These are open relations that extract relational information from text, such as verbs, and give total freedom. However, this technique requires the management of a large number of possibilities.
In order to overcome the problems of both the overly complex system required for open relationship extraction and the need to limit the number of relationship types, we created a progressive, iterative relationship extraction system. We have therefore built our system in several stages:
- Reducing the relation extraction problem to taxonomy relation extraction
- Extension to other types of essential relations such as synonymy, part of or others.
- Domain classification to improve results (see previous BL.Research article)
- Extracting open relations
The basic system of steps 1 and 2 (and also the one to be grafted in step 3) is divided into several phases, as shown in the figure below.
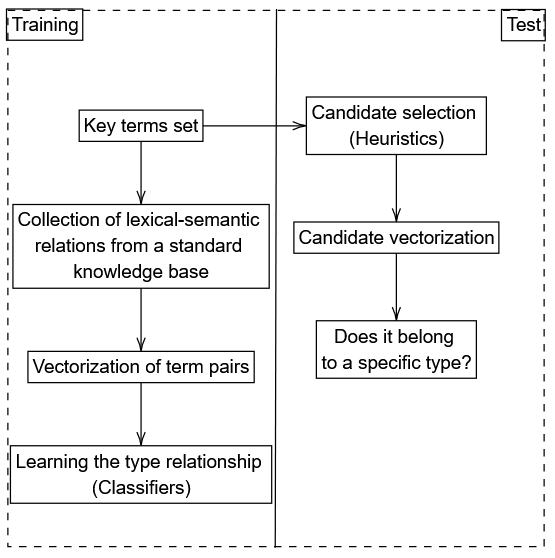
- From the initially extracted key terms, we used the lexical-semantic network JeuxDeMots to retrieve the instances of relations. This lexical-semantic network is a general knowledge base of French, built on a platform that invites the player to explain the relationships linking the different words in the network. This makes it possible to extract information from all kinds of French terms. Our method therefore involves retrieving a set of key term pairs for a given type of relationship, based on the key terms in the corpus. In step (1) of the system, we have limited ourselves to the taxonomy relationship type, i.e. hyperonymy and hyponymy. We then retrieve these relationship instances for various selected types: Generalization (hyperonymy) and Specification (hyponymy) for step (1) and synonymy or others in addition for step (2). Using JeuxDeMots provides a starting point for extracting legal and practical information from our Berger-Levrault texts.
- From these relation instances, we now need to create vector representations of our instances in context. To do this, we first train lexical embeddings of the terms making up the instances. Lexical embeddings are a way of representing words as numerical vectors in a mathematical space. Imagine each word having its own address in this space. Word2Vec is a tool that creates these representations using a deep language model. For example, for the generalization relation: public procurement is_a procurement, Word2Vec creates two lexical plungers called vectors: Vector(public_procurement) and Vector(procurement). From these vectors, we deduce vector representations of typed relations using a simple arithmetic operation. There are two possible cases: the first concerns asymmetrical relations such as generalization or specification, and the second concerns symmetrical relations such as synonymy. In fact, a symmetrical relationship (introduced in step 2) is like a set of mirrors, where if A is linked to B, then B is also linked to A. Take the example of friends: if Alice is Bob’s friend, then Bob is also Alice’s friend. It’s a relationship where both parties see each other in the same way.
Here are the different arithmetic operations (relationOperation):
Let operationRelation (V1, V2) be the relation vector (source: term1, R, target: term2)- Difference: (V1 – V2) ⇢ Example: (v2 – v1) = (public_procurement, is_a, procurement)
- Absolute value : |V1–V2|
- Once the relation vector representations have been created, we add a learning step to take into account the relation type. This involves learning relation types using binary classification. For a given relation type, the binary classification determines whether it is this relation or its opposite. We provide a binary classifier with the relation vectors for a given relationship type as input. For step (1), the task is to determine whether it is the generalization or the specification. For step (2), we need to multiply the number of binary classifiers with a notion of threshold. This is because a pair of terms may belong neither to one type of relation, nor to its opposite. Pairs of terms are then drawn at random. We therefore create a relation vector for a relation type we wish to test: if classification into a given relation type seems certain (high threshold for a given type) then we deduce a new pair.
Evaluation
Table 2 shows the relationship type classification results for step (2) and a column for step (3). The scores in this table take on a value between 0 and 1. Closer to 1 means that the system performs better in its relationship extraction task.
In order to evaluate different classification models, we use Legibase articles already categorized by domain. This allows us to have a corpus already labelled for the classification of articles by domain. We balance our corpus until we have 250 articles in each of the 8 domains. The results for each classified domain are specified, but the average results are presented in the last two columns, as the relationship extraction model is averaged by default, when the domain is not known.
We find that domain classification leads to better results for asymmetrical relations (Hyperonymy vs. Hyponymy) and (Is Part Of vs. Has part) and for symmetrical relations (Synonymy and Antonymy) for two of the four classifiers (SVC and Decision Tree). We can therefore conclude that it is useful to use domain-based document classification before extracting lexical-semantic relations from raw text.
| Relation type | Classifier | Public procurement (Commande publique) | Accounting and local finance (Comptabilité et finances locales) | Justice | Local human resources (RH territoriales) | Health (Santé) | Urban planning (Urbanisme) | Elections (Élections) | Civil status & cemeteries (État civil & cimetières) | Average x domain | Average without domain classification |
| Hyperonymy vs. Hyponymy | SVC | 0.78 | 0.80 | 0.79 | 0.86 | 0.83 | 0.84 | 0.89 | 0.83 | 0.83 | 0.75 |
| DT | 0.57 | 0.68 | 0.71 | 0.77 | 0.79 | 0.72 | 0.78 | 0.71 | 0.72 | 0.71 | |
| RF | 0.75 | 0.74 | 0.76 | 0.81 | 0.83 | 0.78 | 0.85 | 0.80 | 0.79 | 0.78 | |
| k-NN (k=5) | 0.65 | 0.81 | 0.80 | 0.84 | 0.78 | 0.82 | 0.87 | 0.77 | 0.79 | 0.78 | |
| Synonymy vs. Antonymy | SVC | 0.85 | 0.74 | 0.74 | 0.79 | 0.85 | 0.78 | 0.84 | 0.80 | 0.80 | 0.73 |
| DT | 0.76 | 0.76 | 0.76 | 0.76 | 0.76 | 0.76 | 0.76 | 0.76 | 0.75 | 0.72 | |
| RF | 0.79 | 0.61 | 0.64 | 0.69 | 0.75 | 0.65 | 0.76 | 0.73 | 0.70 | 0.78 | |
| k-NN (k=5) | 0.65 | 0.61 | 0.64 | 0.66 | 0.66 | 0.63 | 0.65 | 0.6 | 0.64 | 0.74 | |
| Is Part Of vs. Has part | SVC | 0.75 | 0.84 | 0.83 | 0.84 | 0.91 | 0.80 | 0.66 | 0.84 | 0.82 | 0.79 |
| DT | 0.76 | 0.72 | 0.75 | 0.72 | 0.81 | 0.61 | 0.54 | 0.61 | 0.68 | 0.65 | |
| RF | 0.79 | 0.81 | 0.76 | 0.86 | 0.89 | 0.79 | 0.63 | 0.86 | 0.80 | 0.73 | |
| k-NN (k=5) | 0.28 | 0.80 | 0.78 | 0.81 | 0.81 | 0.72 | 0.55 | 0.79 | 0.75 | 0.75 |
- Link for Légibases : https://www.legibase.fr/ , one link for each knowledge base: https://collectivites.legibase.fr/ for example. ↩︎
- Link for the model on hugging face: https://huggingface.co/Jean-Baptiste/camembert-ner-with-dates ↩︎



