

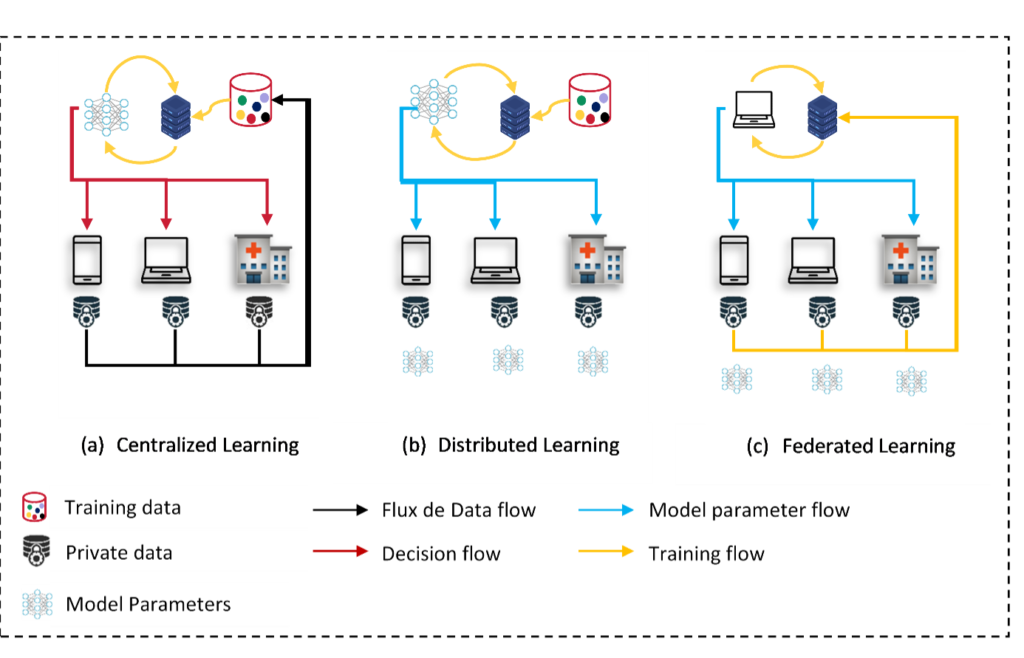
De nos jours, une quantité massive de données est générée par des appareils tels que les smartphones et les objets connectés (IoT). Ces données sont utilisées pour entraîner des modèles d'apprentissage automatique (ML) performants, rendant l'intelligence artificielle (IA) présente dans notre vie quotidienne. Les données sont généralement envoyées dans le cloud, où elles sont stockées, traitées et utilisées pour entraîner des modèles de manière centralisée. L'IA centralisée est l'architecture la plus courante. Cependant, les transferts répétitifs d'énormes volumes de données génèrent un coût élevé en termes de communication réseau et suscitent de nombreuses questions sur la confidentialité et la sécurité des données. Du point de vue de la sécurité, les données sensibles sont fortement exposées aux attaques et aux cyber-risques. Parmi les violations les plus graves enregistrées au XXIe siècle, Equifax avec 147,9 millions de clients touchés en 2017, Marriott avec 500 millions de clients touchés en 2018, et eBay avec 145 millions d'utilisateurs touchés en 2014. Dans ce contexte, un nouveau règlement de l'Union européenne, appelé "Règlement général sur la protection des données", a été appliquée. L'objectif est de sécuriser et de protéger les données personnelles en définissant des règles et des limites, ce qui complique le processus de formation et d'adaptation des modèles d'apprentissage automatique centralisés.

Une approche d'apprentissage distribué a été proposée pour traiter ce problème. Elle consiste à ramener le code aux données. Chaque appareil périphérique (téléphone cellulaire, appareil IoT, etc.) entraîne son modèle localement sans bénéficier des données et de l'expérience des autres. Cette approche garantit la confidentialité des utilisateurs mais les modèles sont loin d'être efficaces principalement en raison du manque de données dans l'appareil, du stockage limité, et de la capacité de calcul.
L'apprentissage fédéré vise à résoudre les problèmes de confidentialité causés par la centralisation des données dans de grandes bases de données. Lorsque vous appliquez une approche d'apprentissage fédéré, vos données restent sur vos appareils (ou serveur), c'est l'IA qui se déplace (et apprend) d'une base de données à une autre plutôt que d'apprendre sur une seule grande base de données.
Google a publié (en 2016) une nouvelle architecture d'apprentissage appelée Federated Learning pour répondre aux limites des approches centralisées et distribuées existantes. Ainsi , qu'est-ce que l'apprentissage fédéré ?
Dites-moi... qu'est-ce que la Federated Learning ?
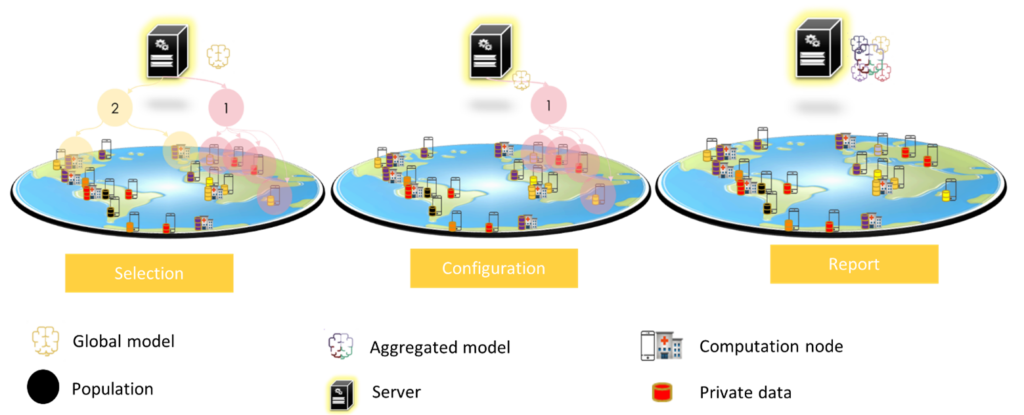
L'apprentissage fédéré vient principalement résoudre le problème de la confidentialité. Cette approche d'apprentissage consiste à entraîner un modèle de manière collaborative à partir des données locales de chaque participant en ne partageant que ses paramètres chiffrés au lieu de partager les données. Cette approche a été proposée pour la première fois par Google afin de prédire les saisies de texte des utilisateurs sur des dizaines de milliers d'appareils Android tout en conservant les données sur les appareils (Brendan McMahan et al. 2017). Pour atteindre cet objectif, Google a défini trois étapes principales pour la communication entre l'appareil et le serveur (Bonawitz et al. 2019) :
- Sélection : Les dispositifs qui répondent aux critères d'éligibilité (par exemple, en charge et connectés à un réseau illimité) sont enregistrés dans le serveur. Le serveur sélectionne un sous-ensemble des participants (population) pour effectuer une tâche (formation, évaluation) sur un modèle.
- Configuration : le serveur envoie un plan à la population qui contient les informations de formation du modèle pour le dispositif et les informations d'agrégation pour le serveur.
- Rapport : dans cette phase, le serveur attend les mises à jour des dispositifs, pour les agréger en utilisant l'algorithme de moyenne fédérée.
L'apprentissage fédéré s'est rapidement développé dans la littérature, nous trouvons plusieurs architectures (Aledhari et al. 2020) qui dépendent principalement des applications. Cependant, les auteurs de (Q. Yang et al. 2020) ont réussi à catégoriser les architectures d'apprentissage fédéré en fonction de la distribution des données. Ces architectures diffèrent en termes de structure et de définition :
Apprentissage fédéré horizontal (HFL)
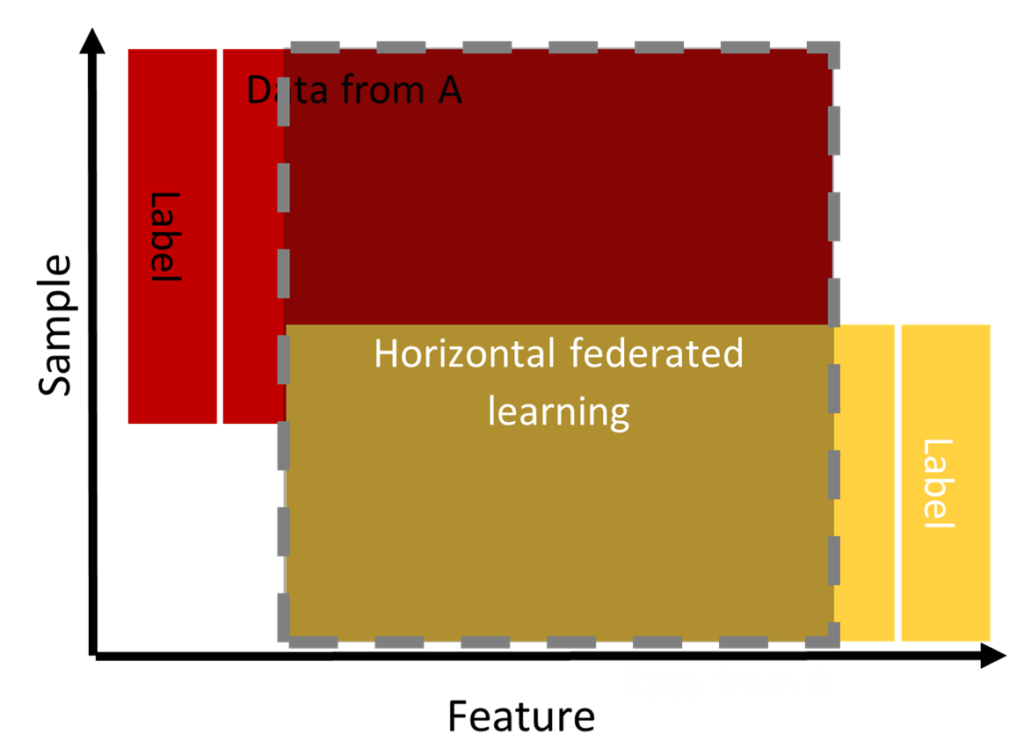
Les données suivent un partitionnement horizontal. Pour cela, nous constatons que les données se chevauchent dans "l'espace des caractéristiques" mais diffèrent au niveau de "l'espace des échantillons" comme le montre la figure 3 (Aledhari et al. 2020 ; Q. Yang et al. 2019, 2020). Cet apprentissage est utilisé lorsque la population appartient au même domaine. Par exemple, deux banques de la même région peuvent collaborer pour détecter les utilisateurs qui empruntent malicieusement à une banque pour rembourser le prêt à une autre banque.
Selon (Q. Yang et al. 2020), nous pouvons mettre en œuvre l'apprentissage fédéré horizontal en suivant deux types d'architecture : une architecture client-serveur ou une architecture pair-à-pair (P2P). Ces architectures diffèrent par les processus de formation et d'agrégation.
Architecture client-serveur
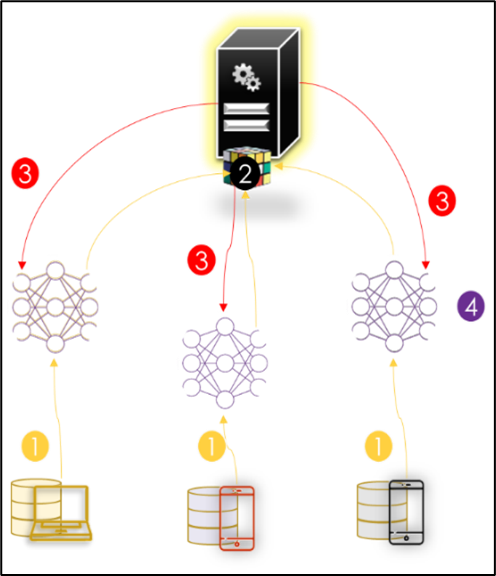
L'architecture client-serveur est illustrée dans la figure ci-dessous. Dans ce système, les participants (également appelés clients ou utilisateurs ou parties) ayant le même schéma de données pilotent en collaboration un modèle global (également appelé serveur de paramètres ou serveur d'agrégation ou coordinateur).
FedAVG (Federated Averaging) est l'algorithme utilisé par Google pour agréger les données des participants. Cet algorithme orchestre l'entraînement via le serveur central qui héberge le modèle global. Cependant, l'optimisation réelle est effectuée localement sur les clients en utilisant, par exemple, le gradient stochastique décent (SGD). L'algorithme FedAvg commence par initialiser et sélectionner un sous-ensemble de clients pour entraîner le modèle global. Un cycle de communication comprend les deux étapes suivantes :
- Étape 1 : Après avoir mis à jour son modèle local, chaque client divise ses données locales en lots de taille B et effectue E époques de la SGD, puis télécharge son modèle local entraîné vers le serveur.
- Étape 2 : Le serveur génère ensuite le nouveau modèle global en calculant une somme pondérée de tous les modèles locaux reçus.
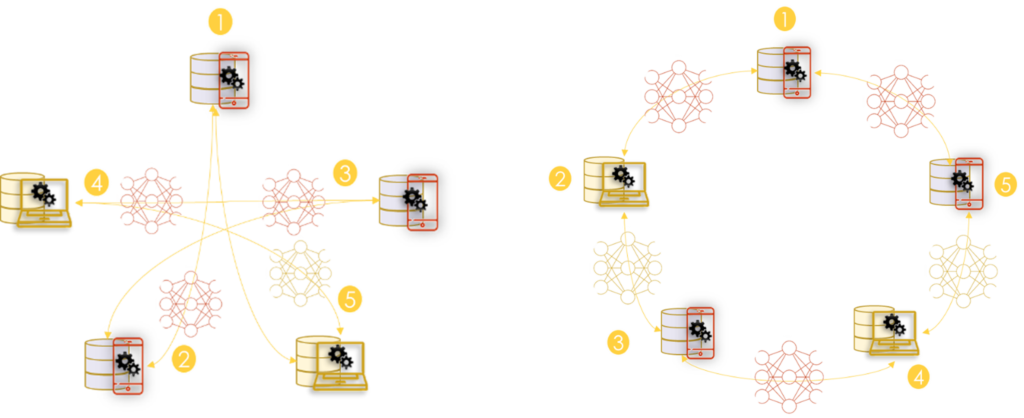
Architecture Peer2Peer
Le P2P est la deuxième architecture proposée pour l'apprentissage horizontal (Q. Yang et al. 2020). Dans cette architecture, les appareils s'organisent pour entraîner un modèle global sans servir de serveur central. (Roy et al. 2019) présente des algorithmes pour cette architecture. La solution est tolérante aux pannes et il n'est pas nécessaire d'avoir un serveur central auquel tout le monde fait confiance. Ainsi, un client aléatoire peut lancer un processus de mise à jour à tout moment.
Le processus de formation se fait en 3 étapes :
- Étape 1 : Chaque participant forme un modèle localement.
- Étape 2 : Un client aléatoire de l'environnement lance le processus de formation global. Il envoie une requête au reste des clients pour obtenir leurs dernières versions du modèle généré.
- Étape 3 : tous les participants envoient leurs poids et la taille de l'échantillon d'apprentissage au client.
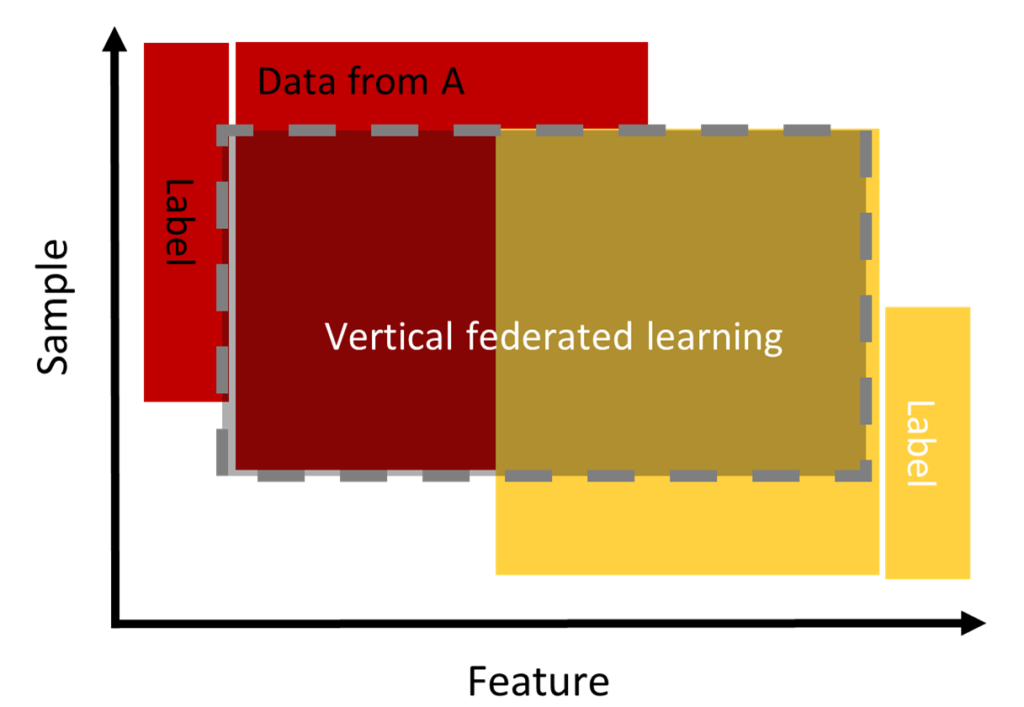
Apprentissage fédéré vertical (VFL)
Dans cette catégorie et contrairement à l'approche horizontale, les données de la population se chevauchent dans "l'espace échantillon" mais diffèrent dans "l'espace caractéristique". Elle est applicable pour deux entités appartenant à deux domaines complémentaires. Par exemple, deux entreprises différentes dans la même ville : l'une est une banque et l'autre une société de commerce électronique. Leur "espace d'échantillonnage" contient la plupart des résidents de la zone ; ainsi, l'intersection de leur "espace d'échantillonnage" est très large. Cependant, comme la banque enregistre le comportement de l'utilisateur en termes de revenus et de dépenses et que le commerce électronique retient la navigation de l'utilisateur et des achats, leurs espaces de fonctionnalités sont très différents.
La VFL peut agréger les caractéristiques des deux parties afin d'obtenir un modèle de prévision des achats de produits en fonction des informations sur les utilisateurs et les produits. (Q. Yang et al. 2019).
Supposons que deux entreprises A et B collaborent entre elles pour former un modèle commun, le processus de formation nous oblige à ajouter un tiers honnête C pour garantir un calcul sécurisé. L'entraînement du modèle se fait en deux étapes :
- Alignement des identifiants : La technique d'alignement des identifiants est utilisée pour confirmer les utilisateurs communs partagés par les deux parties sans exposer leurs données brutes respectives.
- Formation de modèles cryptés : Après avoir déterminé les entités communes, nous pouvons utiliser les données de ces entités communes pour former un modèle ML commun. Le processus de formation peut être divisé en quatre étapes :
- Étape 1 : C crée des paires de chiffrement et envoie la clé publique à A et B.
- Étape 2 : A et B cryptent et échangent les résultats intermédiaires pour les calculs de gradient et de perte.
- Étape 3 : A et B calculent les gradients numériques et ajoutent un masque supplémentaire, respectivement. B calcule également la perte numérique. A et B envoient les résultats numériques à C.
- Étape 4 : C décrypte les gradients et les pertes et renvoie les résultats à A et B. A et B démasquent les gradients et mettent à jour les paramètres du modèle en conséquence.
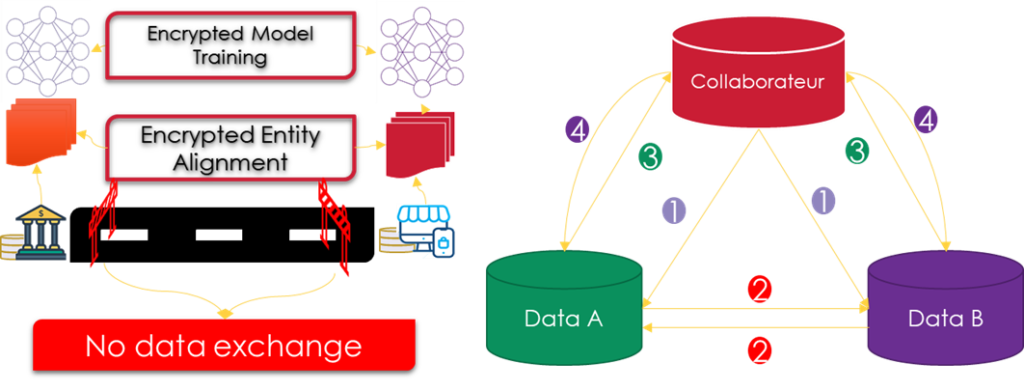
Apprentissage par transfert fédéré
La HFL et la VFL exigent que les participants partagent soit l'espace des caractéristiques, soit l'espace des échantillons pour entraîner le modèle de manière collaborative. Cependant, dans le monde réel, les données des utilisateurs peuvent ne partager qu'un petit nombre d'échantillons ou de caractéristiques, et les données peuvent également être distribuées de manière déséquilibrée entre les utilisateurs, ou toutes les données ne sont pas étiquetées. Face à ces limites, les travaux de (Y. Liu et al. 2018 ; Q. Yang et al. 2019, 2020) ont proposé de combiner l'apprentissage fédéré avec les techniques de transfert d'apprentissage (Pan et al. 2011) qui consistent à déplacer les connaissances d'un domaine (c'est-à-dire le domaine source) vers un autre domaine (c'est-à-dire le domaine cible) pour obtenir de meilleurs résultats d'apprentissage. Cette combinaison est appelée apprentissage par transfert fédéré.
Le travail (Y. Liu et al. 2018) propose une implémentation basée sur la plateforme FATE. L'architecture mise en œuvre est la même que VFL avec deux hôtes contenant les données et l'arbitre qui assure d'une part l'agrégation des gradients et la vérification si la perte converge, et d'autre part la distribution des clés publiques pour les deux hôtes afin d'éviter l'échange de données. Pour entraîner le modèle, les deux hôtes calculent et chiffrent d'abord localement leurs résultats intermédiaires en utilisant leurs données, qui sont utilisées pour les calculs de gradient et de perte. Ensuite, ils envoient les valeurs cryptées à l'arbitre. Enfin, l'invité et l'hôte obtiennent les gradients et les pertes décryptés de l'arbitre pour mettre à jour leurs modèles.
Quelles sont les applications de l'apprentissage fédéré ?
L'apprentissage fédéré est un sujet d'intérêt croissant dans la communauté de la recherche et de l'IA. L'association de cette approche à la confidentialité a conduit les chercheurs et l'industrie à l'appliquer dans de nombreux domaines. Plusieurs applications sont actuellement à l'étude.
Prédiction de mots par clavier virtuel
Il s'agit du premier projet proposé pour FL. Le travail (T. Yang et al. 2018) utilise l'apprentissage fédéré global pour former, évaluer et déployer le mode de régression logistique afin d'améliorer la qualité des suggestions de recherche du clavier virtuel sans accès direct aux données sous-jacentes de l'utilisateur. Il existe diverses exigences que les clients doivent respecter pour valider leur éligibilité à participer au processus FL, telles que, les exigences environnementales, les spécifications des appareils et les restrictions linguistiques. D'autre part, d'autres contraintes sur les tâches FL sont définies par le serveur, notamment le nombre de clients cibles devant participer au processus, le nombre minimum de clients requis pour initier un tour, la fréquence de l'entraînement, un seuil de temps d'attente pour recevoir les mises à jour des clients, et la fraction de clients qui doivent signaler l'initiation d'un tour. Dans les travaux de (Hard et al. 2018), ils ont entraîné un réseau neuronal pour montrer que l'approche fédérée est plus performante que l'approche centrale. Dans ce contexte, il existe d'autres travaux élaborés pour adapter LF à ce type d'application comme la perte des emojis (Ramaswamy et al. 2019).
Soins de santé
LF présente une nouvelle opportunité pour ce domaine. Les nouvelles régularisations ont commencé à empêcher la centralisation de données sensibles telles que les données des patients dans les hôpitaux. Dans ce contexte, une multitude de travaux a déjà proposé une adaptation de cette approche au domaine de la santé. Le tableau en annexe présente quelques applications. La prédiction de la mortalité représente une des applications les plus courantes dans ce domaine. Les auteurs de (D. Liu et al. 2018) ont proposé une nouvelle stratégie pour entraîner un réseau de neurones de manière personnalisée à chaque hôpital. Pour cela, la première couche sera entraînée de manière collaborative tandis que les autres seront constituées localement en fonction des données stockées. Cette stratégie a montré une haute performance par rapport à la méthode centralisée. (Huang et al. 2019) proposent un algorithme LF communautaire pour prédire la mortalité et la durée de séjour à l'hôpital. Les dossiers médicaux électroniques sont regroupés en groupes au sein de chaque hôpital en fonction d'aspects médicaux communs. Chaque groupe apprend et partage un modèle LF particulier, ce qui améliore l'efficacité et les performances, et est personnalisé pour chaque communauté plutôt que d'être un modèle général global partagé par tous les hôpitaux et donc les patients. Un autre type d'application dans ce domaine est la reconnaissance de l'activité humaine (Chen et al. 2019) ont proposé une stratégie pour former des modèles basés sur des données provenant de dispositifs médicaux portables. Les données des dispositifs peuvent être distribuées dans différents clouds en fonction du fournisseur et ne pas être échangées en raison de réglementations imposées. Les auteurs ont proposé d'appliquer l'apprentissage par transfert fédéré pour partager les connaissances. En outre, cette pratique permet la personnalisation nécessaire des modèles car les différents utilisateurs ont des caractéristiques et des modèles d'affaires différents.
Internet des objets (IoT)
Le nombre d'objets connectés augmente chaque année (Lueth 2018). Ces objets envoient une quantité massive de données qui augmentent les coûts de communication, de calcul et de stockage. FL est une nouvelle implémentation de l'apprentissage par les appareils (Dhar et al. 2019) pour assurer d'une part la confidentialité et d'autre part pour minimiser la consommation de calcul et de communication. Dans la littérature scientifique, nous trouvons déjà un bon nombre d'applications de FL dans ce domaine. Le travail (Nguyen et al. 2019) propose un système de détection d'intrusion basé sur la détection d'anomalie pour l'IoT. Ce système se compose de différentes passerelles de sécurité, chacune d'entre elles surveillant le trafic d'un type particulier de dispositif, et pilotant en même temps le modèle Gated Recurrent Unit selon un processus fédéré qui s'appuie sur la récupération et l'entraînement local du modèle, puis envoie des mises à jour à un service de sécurité IoT pour effectuer l'agrégation. Un tel système fonctionne sans utilisateur et est capable de détecter de nouvelles attaques.
| Zone | Type de dispositif de formation | Objectif | Modèle formé | Algorithme d'agrégation |
| Application Gboard | Téléphones mobiles | Modélisation du langage : Suggestion de recherche par clavier Modélisation du langage : Prédiction du mot suivant Modélisation du langage : La prédiction des emoji Modélisation du langage : Apprentissage hors vocabulaire | Régression logistique RNN RNN - LSTM RNN - LSTM | FedAvg FedAvg FedAvg FedAvg |
| Soins de santé | Hôpitaux Scénario 1 : Hôpitaux Scénario 2 : les patients Téléphones connectés aux appareils des patients Organisations Conters Institutions Appareils d'électroencéphalographie (EEG) | Prévision de la mortalité Prédiction de la mortalité et de la durée d'hospitalisation Prévision des hospitalisations Détection d'anomalies dans les systèmes médicaux Reconnaissance de l'activité humaine Analyse des changements cérébraux dans les maladies neurologiques Tumeur cérébrale Classification de l'imagerie Classification du signal HEG | Réseau neuronal Apprentissage profond Sparse SVM Réseau neuronal Réseaux neuronaux profonds Extraction d'éléments CNN : U-Net Réseaux neuronaux profonds CNN | Une proposition de FADL FedAvg Une proposition de CPDS Moyenne (non pondérée) des paramètres s/o Méthode des multiplicateurs à direction alternée FedAvg FedAvg FedAvg |
| Systèmes loT | Passerelle de surveillance des dispositifs loT Objets ou coordinateur loT (dispositif de bordure de serveur de nuage) Périphériques loT Téléphones mobiles et serveurs mobiles Edge Computing | Détection d'anomalies Apprentissage léger pour les dispositifs à ressources limitées Déchargement des calculs Amélioration des services des fabricants de loT | RNN GRU Réseaux neuronaux profonds Double Deep Q Learning Formation du modèle Doep partitionné | FedAvg s/o s/o s/o |
| Informatique de pointe | Équipement de l'utilisateur Nœuds de bordure | Déchargement des calculs Encaissement de bord | Renforcement Apprendre | s/o |
| Mise en réseau | Dispositifs de type machine (MTD) | Allocation de blocs de ressources et transmission de puissance | Chaîne de Markov | Agrégation de MTDs Modbls de trafic |
| Robotique | Robots | Décision de navigation des robots | Apprentissage par renforcement | Une proposition d'algorithme de fusion des connaissances |
| Grille-monde | Agents | Construire les politiques du réseau Q | Réseau Q | Perceptron multicouche |
| Amélioration du FL | Nœuds de bordure | Détermination de la fréquence d'agrégation | Modèles ML basés sur la descente de gradient | FedAvg |
| Système de recommandation | Toute glace de l'utilisateur (p. ex. ordinateurs portables, téléphones) | Génération de recommandations personnalisées | Filtrage collaboratif | Agrégation des gradients pour mettre à jour les vecteurs de facteurs |
| Cybersécurité | Passerelles de surveillance Nœuds de bureau | Détection d'anomalies | Auto-codeur | FedAvg |
| Détaillants en ligne | Clients Utilisateurs de la RA | Prédiction du flux de clics Encaissement de bord | RNN - GRU Auto-codeur | FedAvg s/o |
| Communication sans fil | Radios Entités du réseau central | Gestion du spectre Réseau de communication 5G | un modèle d'utilisation du spectre s/o | s/o s/o |
| Véhicules électriques | Véhicules | Prévision des défaillances des VE | RNN LSTM | Moyenne pondérée basée sur la fonction de perte |
Références
- S. Dhar, J. Guo, J. Liu, S. Tripathi, U. Kurup, et M. Shah, "On-device machine learning : An algorithms and learning theory perspective ", arXiv. 2019.
- H. Brendan McMahan, E. Moore, D. Ramage, S. Hampson et B. Agüera y Arcas, "Communication-efficient learning of deep networks from decentralized data", 2017.
- K. Bonawitz et al, "Towards federated learning at scale : System design ", arXiv. 2019.
- M. Aledhari, R. Razzak, R. M. Parizi, et F. Saeed, "Federated Learning : A Survey on Enabling Technologies, Protocols, and Applications", IEEE Access. 2020, doi : 10.1109/ACCESS.2020.3013541.
- Q. Yang, Y. Liu, Y. Cheng, Y. Kang, T. Chen et H. Yu, "Federated Learning", dans Synthesis Lectures on Artificial Intelligence and Machine Learning, 2020.
- Q. Yang, Y. Liu, Tianjian Chen, et Yongxin Tong, "Federated Machine Learning : Concept et applications ", arXiv. 2019.
- H. B. McMahan, E. Moore, D. Ramage, S. Hampson et B. A. y Arcas, "Federated Learning of Deep Networks using Model Averaging", Arxiv, 2016.
- A. G. Roy, S. Siddiqui, S. Polsterl, N. Navab, et C. Wachinger, "BrainTorrent : Un environnement peer-to-peer pour l'apprentissage fédéré décentralisé ", arXiv. 2019.
- Y. Liu, Y. Kang, C. Xing, T. Chen et Q. Yang, " A secure federated transfer learning framework ", arXiv. 2018.
- S. J. Pan, I. W. Tsang, J. T. Kwok, et Q. Yang, "Domain adaptation via transfer component analysis," IEEE Trans. Neural Networks, 2011, doi : 10.1109/TNN.2010.2091281.
- OpenMined, "PySyft," 2020. https://github.com/OpenMined/PySyft.
- Google, "Tensorflow," 2020. https://www.tensorflow.org/federated?hl=fr (consulté le 18 janvier 2021).
- Google, "tensor i/o," 2020. https://www.tensorflow.org/io?hl=fr (consulté le 18 janvier 2021).
- AI Webank, "FATE", 2020. https://fate.fedai.org/ (consulté le 18 janvier 2021).
- T. Yang et al, "APPLIED FEDERATED LEARNING : IMPROVING GOOGLE KEYBOARD QUERY SUGGESTIONS," arXiv. 2018.
- A. Hard et al. " Federated learning for mobile keyboard prediction ", arXiv. 2018.
- S. Ramaswamy, R. Mathews, K. Rao et F. Beaufays, " Federated learning for emoji prediction in a mobile keyboard ", arXiv. 2019.
- D. Liu, T. Miller, R. Sayeed, et K. D. Mandl, "FADL:Federated-Autonomous Deep Learning for Distributed Electronic Health Record," arXiv. 2018.
- L. Huang, A. L. Shea, H. Qian, A. Masurkar, H. Deng et D. Liu, " Patient clustering improves efficiency of federated machine learning to predict mortality and hospital stay time using distributed electronic medical records ", J. Biomed. Inform., 2019, doi : 10.1016/j.jbi.2019.103291.
- Y. Chen, J. Wang, C. Yu, W. Gao, et X. Qin, "FedHealth : Un cadre d'apprentissage de transfert fédéré pour les soins de santé portables ", arXiv. 2019.
- K. L. Lueth, "Number-of-global-device-connections-2015-2025-Number-of-IoT-Devices", 2018. https://iot-analytics.com/state-of-the-iot-update-q1-q2-2018-number-of-iot-devices-now-7b/.
- T. D. Nguyen, S. Marchal, M. Miettinen, H. Fereidooni, N. Asokan et A. R. Sadeghi, " DÏoT : A federated self-learning anomaly detection system for IoT ", 2019, doi : 10.1109/ICDCS.2019.00080.

