

SemEval est une série d'ateliers internationaux de recherche en traitement du langage naturel (NLP) dont la mission est de faire progresser l'état de l'art en matière d'analyse sémantique et d'aider à créer des ensembles de données annotées de haute qualité dans une série de problèmes de plus en plus difficiles en sémantique du langage naturel. Chaque année, l'atelier présente un ensemble de tâches partagées dans lesquelles des systèmes d'analyse sémantique computationnelle conçus par différentes équipes sont présentés et comparés.
Dans cette édition, SemEval a proposé 12 tâches sur lesquelles travailler.
Comme vous le savez peut-être, la PNL est un sujet auquel notre équipe se consacre. SemEval a été une excellente occasion de nous mettre au défi avec une communauté internationale de PNL. Dans cet article, nous allons développer comment les membres de notre équipe ont traité cette première tâche de dictionnaire inversé qu'ils ont choisie : CODWOE : Comparaison de dictionnaires et de WOrd Embeddingsqui consiste à comparer deux types de descriptions sémantiques : les gloses des dictionnaires et les représentations par encastrement des mots. Fondamentalement, étant donné une définition, pouvons-nous générer la vecteur d'intégration du mot cible ?
Les recherches récentes se sont concentrées sur l'apprentissage de représentations de phrases et d'expressions de longueur arbitraire et le dictionnaire inverse est l'un des cas les plus courants pour résoudre ce problème. Le dictionnaire inversé consiste à trouver le mot recherché à travers sa description. Par exemple, en donnant cette description : "un écrit sur un sujet particulier dans un journal ou un magazine, ou sur l'internet". au dictionnaire inversé, il devrait trouver le mot "article" qui lui correspond.
Le principal problème qui subsiste est comment capturer les relations entre plusieurs mots et phrases dans un seul vecteur ?
L'organisation a fourni un ensemble de données d'essai de 200 éléments composés de vecteurs de définition et de leurs encastrements dans cinq langues : français, anglais, espagnol, italien et russe et dans différentes représentations de vecteurs construites avec des techniques bien connues :
- "char" correspond à incorporation de caractèrescalculé à l'aide d'un codeur automatique sur l'orthographe d'un mot.
- "sgns" correspond à Skip-Gram with negative sampling embedding, aka. Word2Vec (Mikolov et al., 2013).
- "electra" correspond à Incorporation contextuelle basée sur un transformateur.
Afin que les résultats restent comparables et significatifs sur le plan linguistique, les challengers n'ont pas pu utiliser de ressources externes.
Dans ce qui suit, nous allons présenter nos contributions pour résoudre le problème du dictionnaire inversé.
Notre proposition de modèles
Nos approches nécessitent un modèle capable d'apprendre à établir une correspondance entre des phrases de longueur arbitraire et des vecteurs de mots de longueur fixe à valeur continue. Nous avons exploré des modèles séquentiels, en particulier les modèles LSTM (Long-Short Term Memory) et BiLSTM (Bidirectional Long-Short Term Memory). L'architecture des modèles suivants est basée sur TensorFlow et Keras bibliothèques.
Avant de présenter nos modèles, nous souhaitons mentionner que nous avons prétraité les données de contenu à l'aide de Stanza qui lemmatise toutes les définitions et supprime toute la ponctuation. Nous l'avons fait afin de minimiser les mots alternatifs pour un même concept et d'aider nos modèles à traiter correctement le vocabulaire.
Modèle de base
Notre premier modèle appelé Baseline Model est intentionnellement simple pour créer des scores de base et introduire des manipulations sur les ensembles de données.
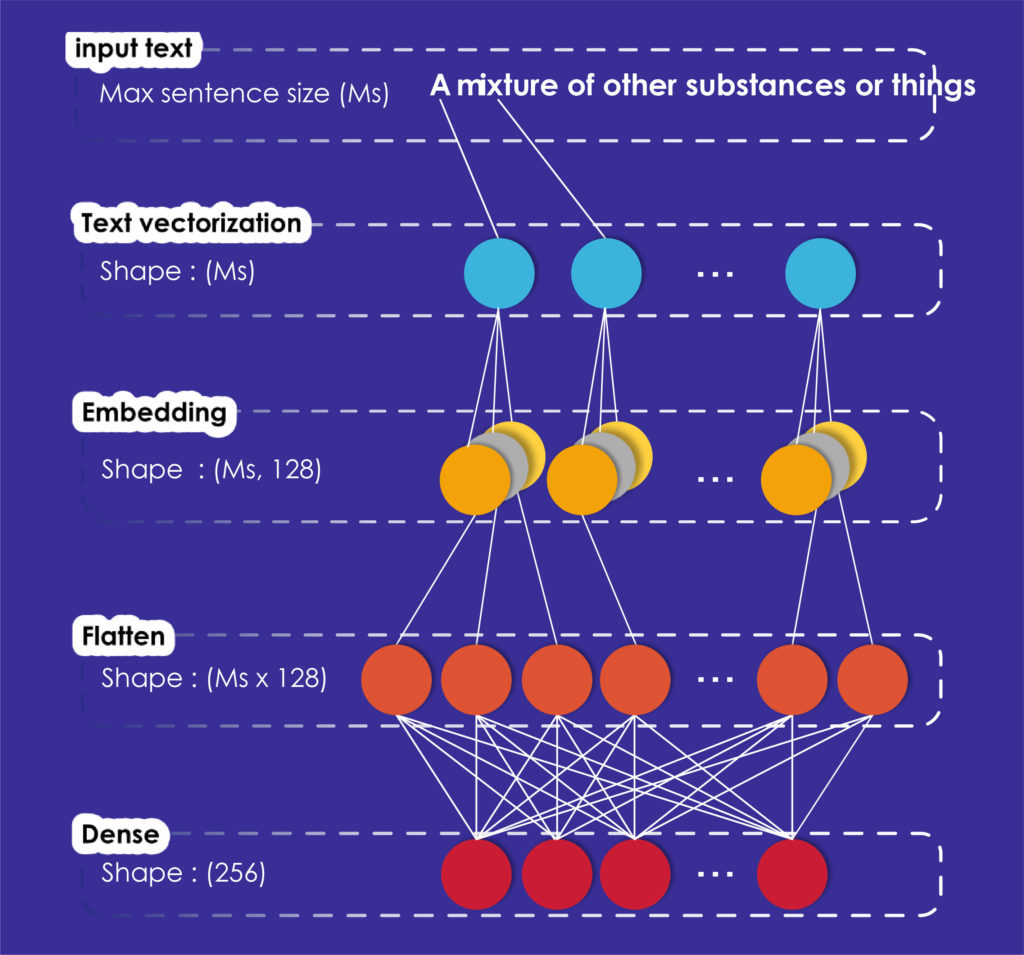
Comme vous pouvez le constater dans la figure 1, notre modèle créé avec Keras est composé de quatre couches. Sa première couche qui est la vectorisation du texte, transforme le texte d'entrée en un vecteur. Pour effectuer cette opération, nous devons donner un identifiant à chaque mot différent dans notre corpus, puis chaque phrase sera représentée comme un vecteur d'identifiants.
Maintenant, la phrase de chaque vecteur est prête à être traitée par la couche d'incorporation qui transforme les entiers positifs (index) en vecteurs denses de taille fixe.
Ensuite, la couche d'aplatissement fera passer les données de deux dimensions à une seule sans perdre aucune valeur.
Enfin, nous modélisons les données de sortie en utilisant une couche entièrement connectée (couche dense) pour correspondre à l'incorporation de brillance donnée par les organisateurs.
Modèle avancé
Les LSTM sont des réseaux neuronaux récurrents (RNN) qui possèdent une mémoire interne leur permettant de stocker les informations apprises pendant la formation. Ils sont fréquemment utilisés dans la tâche de dictionnaire inversé et dans les tâches d'intégration de mots et de phrases, car ils peuvent apprendre les dépendances à long terme entre les mots existants dans la phrase et ainsi calculer les vecteurs de représentation du contexte pour chaque mot.
BiLSTM est une variante des LSTM. Il permet une représentation bidirectionnelle des mots.
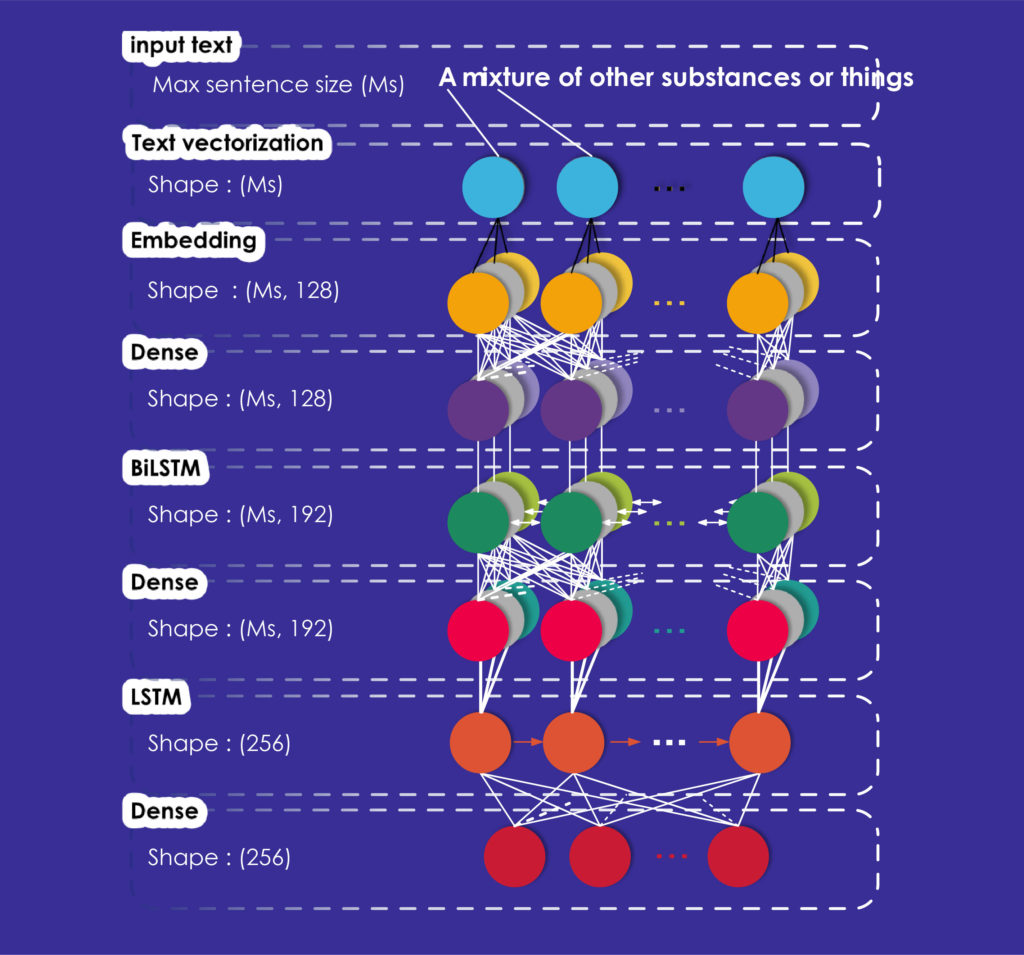
Notre deuxième modèle, appelé modèle avancé, est un réseau BiLSTM-LSTM. Comme pour le modèle de base, nous utilisons un modèle séquentiel qui peut être fourni par Keras.
Ce modèle commence également par une couche de vectorisation du texte, une couche d'incorporation et une couche dense produisant des vecteurs. Nous avons ensuite ajouté une couche BiLSTM, qui prend une couche récurrente (le premier LSTM de notre réseau) qui, à son tour, prend le "mode de fusion" comme argument. Ce mode spécifie comment les sorties avant et arrière doivent être combinées ; dans notre cas, la moyenne des sorties est prise.
A ces trois couches, nous avons ajouté une autre couche Dense entièrement connectée et une couche LSTM de 256 dimensions correspondant aux dimensions des vecteurs de sortie et une couche Dense finale avec les mêmes dimensions.
Configuration expérimentale
Puisque trois types de représentations vectorielles nous ont été proposés dans cette tâche partagée, nous avons utilisé les mêmes architectures pour produire les trois types de vecteurs. Cependant, le format de données donné en entrée du modèle n'est pas le même pour les trois types. Pour les types de représentation "electra" et "sgns", nous avons préparé un vocabulaire contenant les mots des glosses du "training dataset", les mots de ce vocabulaire ont été obtenus en suivant l'étape de prétraitement.
Pour le type vectoriel "char", nous construisons un vocabulaire de tous les caractères utilisés dans les gloses sans prétraiter les données. L'idée étant que, pour la représentation de type "char", le modèle encode les caractères des gloses en vecteurs et produit ensuite les vecteurs d'encodage des gloses sur la base des vecteurs de caractères constituant les gloses.
Le modèle que nous proposons est un modèle monolingue (nous l'avons entraîné séparément sur le jeu de données d'entraînement de chaque langue). Cependant, afin d'évaluer l'impact de l'utilisation d'un modèle multilingue, nous avons entraîné les mêmes réseaux neuronaux sur cinq langues (avec vecteur de caractères) en même temps et comparé les résultats obtenus avec ceux des modèles monolingues.
Pour les types de représentation "sgns" et "electra", nous avons construit un vocabulaire contenant les mots de toutes les gloses sur les cinq langues, qui contient au total 121 147 mots. Nous avons fait de même avec les vecteurs "char" mais en préparant un vocabulaire de caractères à la place contenant 405 caractères, au total. Le tableau 1 ci-dessous décrit la taille du vocabulaire pour chaque modèle monolingue et pour le modèle multilingue.
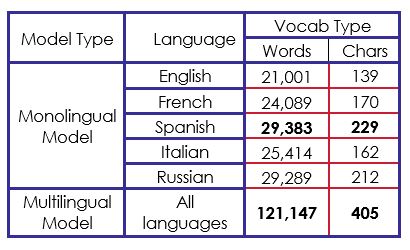
Nous remarquons qu'en additionnant tous les mots dans les cinq langues différentes des données d'origine, on obtient 129 176 mots. Cependant, le vocabulaire de notre modèle multilingue est de 121 147 mots, ce qui signifie qu'il existe 8 029 mots communs à au moins deux langues différentes.
Résultats et analyse
Notre objectif principal était de surpasser le modèle de base et les résultats de l'organisateur.
Notre modèle de base n'a pas obtenu de meilleurs résultats que les modèles de pointe, mais nous pouvons analyser un point intéressant : ce modèle simple produit étonnamment de meilleurs résultats sur la mesure du Rank cosinus. Sur les résultats de la MSE (erreur quadratique moyenne) seuls trois cas surpassent le modèle de base des organisateurs. De plus, chaque mesure de cosinus de rang est meilleure.
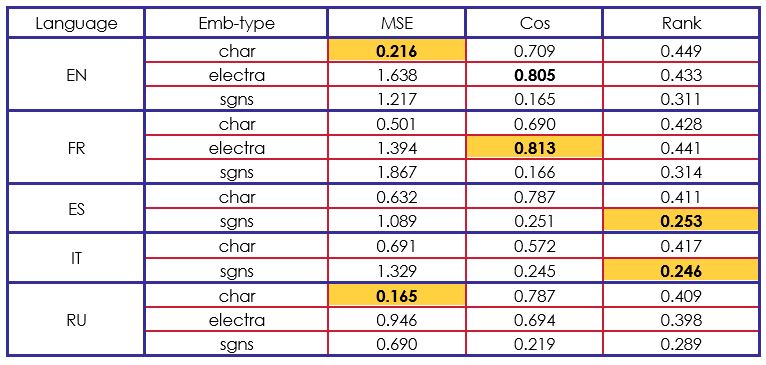
A ce stade, nous pouvons analyser qu'il est difficile d'être performant dans les mesures MSE et Cosinus, tout en essayant d'obtenir de bons résultats dans la mesure Rank et vice-versa. Cette analyse est soutenue par l'évaluation suivante de notre modèle avancé dans le tableau 3.
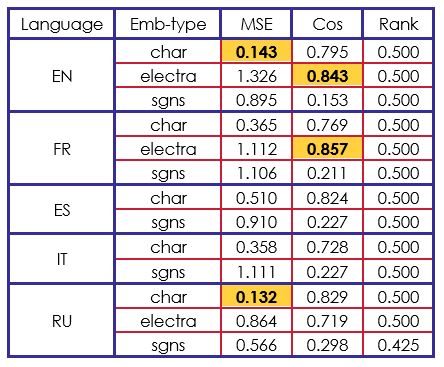
Les résultats de notre deuxième modèle sont complètement opposés. Nous avons obtenu de meilleurs résultats que le modèle de l'organisateur dans les mesures MSE et Cosinus. Par contre, le Rank cosinus semble rester bloqué à .
Si nous comparons nos résultats à ceux des autres participants, nous pouvons dire que notre architecture BiLSTM-LSTM est efficace sur les embeddings "char" et "electra". Par exemple, dans "char" avec l'anglais, le français et l'espagnol, nous avons obtenu le deuxième meilleur score du défi.
Compte tenu de l'ensemble des résultats obtenus, nous constatons que le meilleur score en cosinus a été obtenu en utilisant des incorporations vectorielles électrisées (contextualisées) et que le meilleur score MSE a été obtenu en utilisant des incorporations vectorielles de caractères. De manière plus générale, l'utilisation d'un réseau neuronal à architecture BiLSTM-LSTM a permis d'obtenir des résultats qui dépassent les valeurs de référence lorsque le cosinus et l'EQM sont utilisés comme mesures d'évaluation.
En conclusion
Dans cet article, nous avons présenté nos contributions pour résoudre le problème de la tâche 1 du défi SemEval-2022. Nous avons étudié les effets de l'entraînement des incorporations de phrases avec des données supervisées en testant nos modèles sur cinq langues différentes. Nous avons montré que les modèles appris à l'aide d'enchâssements char ou d'enchâssements contextualisés peuvent être plus performants que les modèles appris à l'aide de données supervisées. Skip-Gram l'incorporation de mots. En explorant différentes architectures, nous avons montré que la combinaison de couches d'incorporation/dense/BiLSTM/Dense/LSTM peut être plus avantageuse que la simple utilisation de la couche d'incorporation.
Dans un prochain article, nous présenterons notre système d'évaluation de la similarité sémantique textuelle au niveau des documents lors de la tâche 8 de SemEval-2022 : "Multilingual News Article Similarity".



