Contexte
La veille juridique est une activité cruciale pour les juristes afin de rester en phase avec l'actualité juridique. Elle leur permet d'être en permanence au courant des réglementations en vigueur et d'anticiper leurs évolutions futures, afin de les appliquer dans les meilleurs délais. Cependant, avec l'inflation constante de la législation, les veilleurs eux-mêmes subissent une surcharge d'informations qui complique leurs activités. Il leur devient très difficile d'analyser des centaines voire des milliers d'articles par jour et la synthèse des informations pertinentes demande un effort considérable. La génération automatique de résumés représente donc une solution intéressante pour aider les chiens de garde dans leurs activités de veille juridique. Les approches de résumé peuvent être ≪ extractives ≫ ou ≪ abstractives ≫. Les approches extractives renvoient des extraits des textes à résumer, tandis que les approches abstractives peuvent formuler de nouvelles phrases. Ainsi, les approches abstractives visent à produire des résumés analogues à ceux que produisent les charges horlogères.
Dans cet article, nous examinerons dans quelle mesure nous pouvons appliquer des modèles linguistiques génératifs à des collections de données juridiques, quelles sont leurs limites et comment nous pouvons évaluer la fidélité du résumé qu'ils génèrent.
Données utilisées pour les expériences
Pour cette étude, nous avons utilisé la collection de données françaises Légibase de Berger-Levrault. Légibase est une collection de documents de veille juridique et réglementaire pour les collectivités locales et les administrations publiques. Chaque document comprend (a) un titre, (b) un texte, (c) un résumé et (d) un ensemble de métadonnées associées aux documents. Un exemple de document est présenté à la figure 1. Toutes les informations contenues dans les documents sont rédigées par des experts en la matière dont l'objectif est de maintenir l'information juridique à jour.

LLM utilisés pour les expériences
Nous avons sélectionné 4 modèles de génération de résumés : BART, BARThez, Bert2Bert, T5. Chacun de ces modèles ayant été entraîné sur des données génériques, généralement issues du web et dont le vocabulaire est assez éloigné de celui du domaine juridique, nous avons procédé à une étape de mise au point de ces modèles sur les données Légibase.
Résultats
Afin d'évaluer la performance des modèles que nous avons affinés, nous avons utilisé des métriques de performance dédiées à la génération automatique de résumés ROUGE et BLEU. Ces métriques comparent le nombre de n-grammes (séquence de mots) en commun entre le résumé de référence produit par les experts et le résumé généré par les modèles de langage. Nous avons également utilisé un score de similarité sémantique CosSim qui mesure la proximité sémantique entre le résumé de référence et le résumé généré. Les résultats obtenus sont présentés dans la figure 2 :
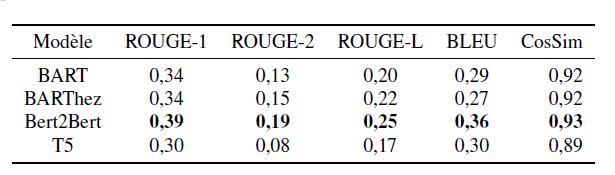
La figure des résultats montre que le modèle Bert2Bert se distingue des autres modèles, suivi des deux modèles BART et BARThez. Le modèle T5 s'avère être celui qui obtient les plus mauvais résultats.
L'importance des entités d'intérêt dans l'évaluation des résumés générés
Les domaines spécialisés tels que le droit, la santé ou la science en général sont des domaines particulièrement sensibles, où chaque concept utilisé, chaque nom propre ou même adjectif a une signification concise. La véracité des informations véhiculées dans ces domaines est donc très importante. Les scores ROUGE et BLEU que nous avons obtenus nous donnent une première indication de la qualité des résumés générés par les modèles de langage. Cependant, ils ne nous permettent pas d'évaluer la couverture des résumés en termes de vocabulaire d'intérêt (vocabulaire métier et entités nommées), ni d'évaluer les incohérences avec le document source. Nous proposons donc de nous concentrer sur une analyse plus avancée des résumés générés. Nous définissons le concept d'entité d'intérêt, c'est-à-dire une entité liée au domaine juridique ou une simple "entité nommée". Dans ce qui suit, nous choisissons d'évaluer la couverture des résumés et leurs incohérences, connues sous le nom d'hallucinations basées sur les entités d'intérêt détectées dans le document source et les résumés générés.
Une illustration des hallucinations est proposée dans l'exemple de la figure 3 :

Paramètres pris en compte
Deux types de mesures sont proposés : la couverture et le taux d'hallucination/abstraction.
Soit N(d), N(r), N(g) les nombres d'entités d'intérêt présentes respectivement dans le document source d, dans le résumé de référence r (gold standard) et dans le résumé généré g.
Une première catégorie de mesures concerne la couverture des résumés :
- le taux de couverture cg des résumés générés :
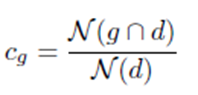
Où N(g ∩ d) est le nombre d'entités d trouvées dans le résumé généré.
- Le taux de couverture Cr des résumés de référence :
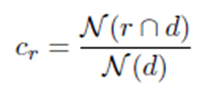
Où N(r ∩ d) est le nombre d'entités d trouvées dans le résumé de référence rédigé par les experts. Cr peut être considéré comme un maximum réalisable par les différents modèles.
Une deuxième catégorie de mesures est liée à l'apparition d'entités dans les résumés générés/de référence, entités qui n'étaient pas présentes dans les documents sources. Nous définissons :
- le taux d'hallucination (extrinsèque) h :
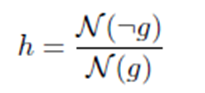
Où N(¬r) est le nombre d'entités abstraites dans r, c'est-à-dire le pourcentage d'entités dans r qui ne font pas partie des entités dans d.
Ces abstractions peuvent être comparées à des hallucinations extrinsèques des résumés générés dans le sens où elles ne se rapportent pas aux connaissances présentes dans d. Elles proviennent des experts qui ont rédigé les résumés de référence : ces derniers peuvent en effet utiliser leurs connaissances a priori pour rédiger les résumés. Il faut cependant noter que même si elles sont comparables à des hallucinations extrinsèques, les abstractions sont factuelles, c'est-à-dire qu'elles peuvent être considérées comme vraies, contrairement à certaines hallucinations extrinsèques.
Résultats
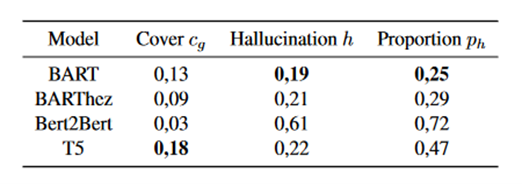
Les résultats de la figure 4 montrent des différences significatives dans les taux obtenus par les différents modèles. Bien que le modèle Bert2Bert ait obtenu les meilleurs scores ROUGE et BLEU, il obtient le taux de couverture le plus faible, le taux d'hallucination le plus élevé (>60%) ainsi que la proportion la plus élevée de résumés hallucinés. Le modèle T5, en revanche, a la meilleure couverture des entités du document source, dépassant même celle des résumés de référence. Enfin, le modèle BART présente le taux et la proportion d'hallucinations les plus faibles.
Une autre analyse a porté sur l'étude des taux de couverture et d'hallucination en fonction des entités impliquées (personne, organisation, lieu et juridique). Les entités juridiques sont les plus hallucinées, probablement en raison de leur forte présence dans la collecte de données. Les personnes, les organisations et les lieux sont hallucinés de manière relativement similaire.
Enfin, pour examiner les hallucinations plus en détail, nous avons calculé le pourcentage d'intersection entre les entités hallucinées dans les résumés générés et les entités abstraites dans les résumés de référence.
Les résultats sont présentés dans la figure 5. Ils donnent une indication de la factualité des hallucinations. Une fois de plus, Bert2Bert obtient les résultats les moins convaincants, en contradiction avec les résultats des métriques traditionnelles. Cependant, ces analyses doivent être approfondies : sans mise en contexte des entités hallucinées, leur factualité exacte ne peut être déduite. Elles peuvent en effet être utilisées de manière à provoquer des contre-sens ou de manière erronée.

Tous ces résultats confirment qu'une simple analyse sur les métriques ROUGE et BLEU n'est pas suffisante dans un contexte commercial. Le modèle Bert2Bert, qui semblait le plus performant sur les métriques classiques, s'avère être celui qui génère le plus d'hallucinations "incontrôlées". Nous envisageons donc de poursuivre une étude plus détaillée des modèles T5 et BART.
Quelle est la prochaine étape ?
Cette étude ouvre plusieurs perspectives. A court terme, nous souhaitons poursuivre l'évaluation des hallucinations : (i) en détectant les hallucinations intrinsèques, et (ii) en analysant la factualité des hallucinations dans leur ensemble.
A plus long terme, les modèles génératifs peuvent être améliorés selon deux axes : (i) limiter les hallucinations, ce qui passe par la suppression des abstractions dans les résumés de référence, et (ii) les contrôler, en apprenant aux modèles à halluciner des informations factuelles (véridiques). Ces deux perspectives pourraient conduire à des résultats plus précis et plus fiables dans la génération de résumés dans le domaine juridique, un domaine d'activité dans lequel la véracité de l'information est cruciale.