

SemEval es una serie de talleres internacionales de investigación sobre el Procesamiento del Lenguaje Natural (PLN) cuya misión es avanzar en el estado actual del arte del análisis semántico y ayudar a crear conjuntos de datos anotados de alta calidad en una serie de problemas cada vez más desafiantes en la semántica del lenguaje natural. El taller de cada año incluye una colección de tareas compartidas en las que se presentan y comparan sistemas de análisis semántico computacional diseñados por diferentes equipos.
En esta edición, SemEval propuso 12 tareas para trabajar.
Como ya sabrás, la PNL es un tema al que nuestro equipo se dedica. SemEval fue una gran oportunidad para desafiarnos a nosotros mismos con una comunidad internacional de PNL. En este artículo, desarrollaremos cómo los miembros de nuestro equipo se enfrentaron a esta primera tarea de diccionario inverso que eligieron: CODWOE: Comparación de diccionarios e incrustaciones de palabrasque consiste en comparar dos tipos de descripciones semánticas: glosas de diccionario y representaciones de incrustación de palabras. Básicamente, dada una definición, ¿podemos generar la vector de inclusión de la palabra objetivo?
Las investigaciones recientes se han centrado en el aprendizaje de representaciones de frases y oraciones de longitud arbitraria y el diccionario inverso es uno de los casos más comunes para resolver este problema. El diccionario inverso es la tarea de encontrar la palabra buscada a través de su descripción. Por ejemplo, dando esta descripción: "un escrito sobre un tema concreto en un periódico o revista, o en Internet" al diccionario inverso, debería encontrar la palabra "artículo" correspondiente.
El principal problema que queda es ¿cómo capturar las relaciones entre múltiples palabras y frases en un solo vector?
La organización proporcionó un conjunto de datos de prueba de 200 elementos compuestos por vectores de definición y sus incrustaciones en cinco idiomas: francés, inglés, español, italiano y ruso y en diferentes representaciones de vectores construidas con técnicas conocidas:
- "char" corresponde a incrustación basada en caracterescalculado mediante un autocodificador sobre la ortografía de una palabra.
- "sgns" corresponde a Skip-Gram con incrustación de muestreo negativo, también conocido como Word2Vec (Mikolov et al., 2013).
- "electra" corresponde a Incrustación contextualizada basada en transformadores.
Para que los resultados sean comparables y lingüísticamente significativos, los aspirantes no pudieron utilizar ningún recurso externo.
A continuación, presentaremos nuestras contribuciones para resolver el problema del diccionario inverso.
Nuestra propuesta de modelos
Nuestros enfoques requieren un modelo capaz de aprender a mapear entre frases de longitud arbitraria y vectores de palabras de valor continuo de longitud fija. Exploramos modelos secuenciales, especialmente modelos LSTM (Long-Short Term Memory) y BiLSTM (Bidirectional Long-Short Term Memory). La arquitectura de los siguientes modelos se basa en TensorFlow y Keras bibliotecas.
Antes de presentar nuestros modelos, queremos mencionar que hemos preprocesado los datos de contenido utilizando Stanza que lematiza todas las definiciones y elimina toda la puntuación. Lo hicimos para minimizar las palabras alternativas para un mismo concepto y ayudar a nuestros modelos a procesar correctamente el vocabulario.
Modelo de referencia
Nuestro primer modelo, denominado Modelo de referencia, es intencionadamente sencillo para crear puntuaciones de referencia e introducir manipulaciones en los conjuntos de datos.
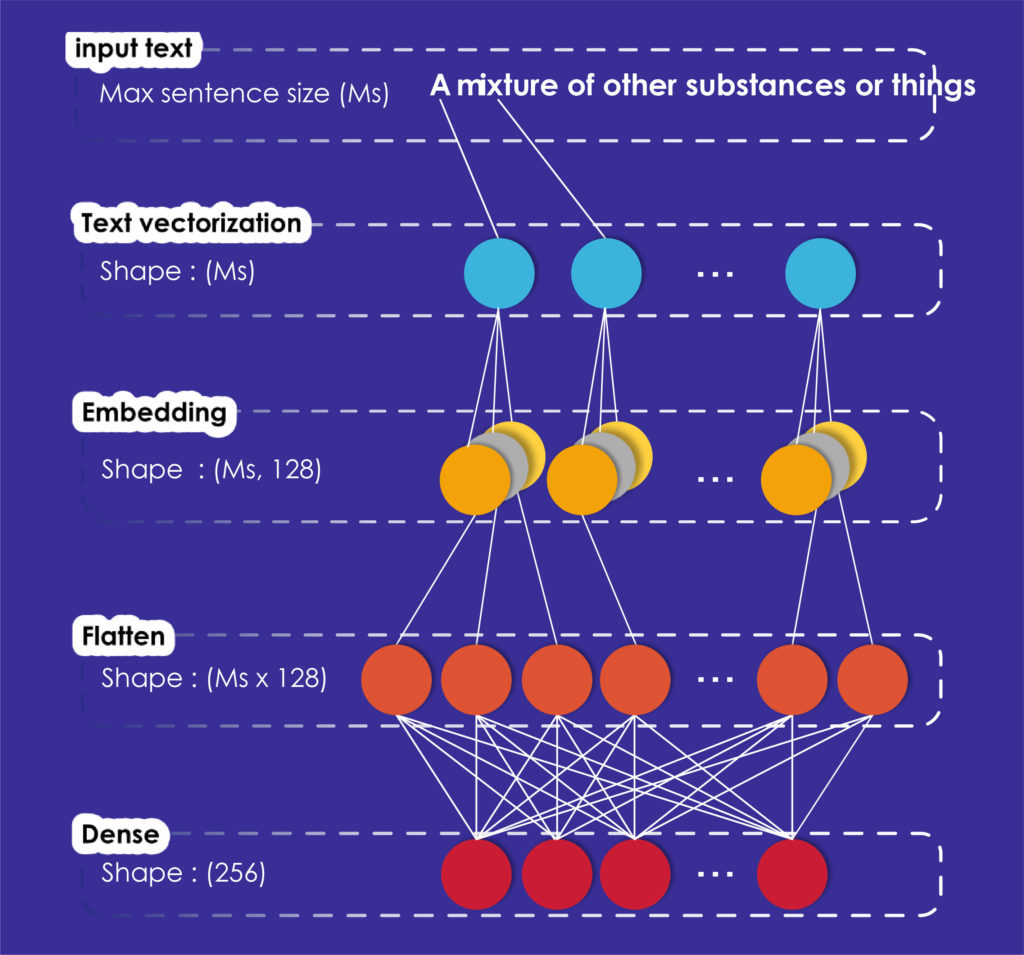
Como se puede ver en la figura 1, nuestro modelo creado con Keras se compone de cuatro capas. Su primera capa, que es la vectorización del texto, transforma el texto de entrada en un vector. Para realizar esta operación, debemos dar un identificador a cada palabra diferente de nuestro corpus, entonces cada frase se representará como un vector de identificadores.
Ahora, la frase de cada vector está lista para ser procesada por la capa de incrustación que convierte los enteros positivos (índices) en vectores densos de tamaño fijo.
Entonces, la capa de aplanamiento cambiará la dimensión de los datos de dos dimensiones a una sin perder ningún valor.
Por último, modelamos los datos de salida utilizando una capa totalmente conectada (capa densa) para que coincida con la incrustación de brillo dada por los organizadores.
Modelo avanzado
Las LSTM son Redes Neuronales Recurrentes (RNN) que tienen una memoria interna que les permite almacenar la información aprendida durante el entrenamiento. Se utilizan con frecuencia en la tarea de diccionario inverso y en las tareas de incrustación de palabras y frases, ya que pueden aprender las dependencias a largo plazo entre las palabras existentes en la frase y, por tanto, calcular los vectores de representación del contexto para cada palabra.
BiLSTM es una variante de los LSTM. Permite una representación bidireccional de las palabras.
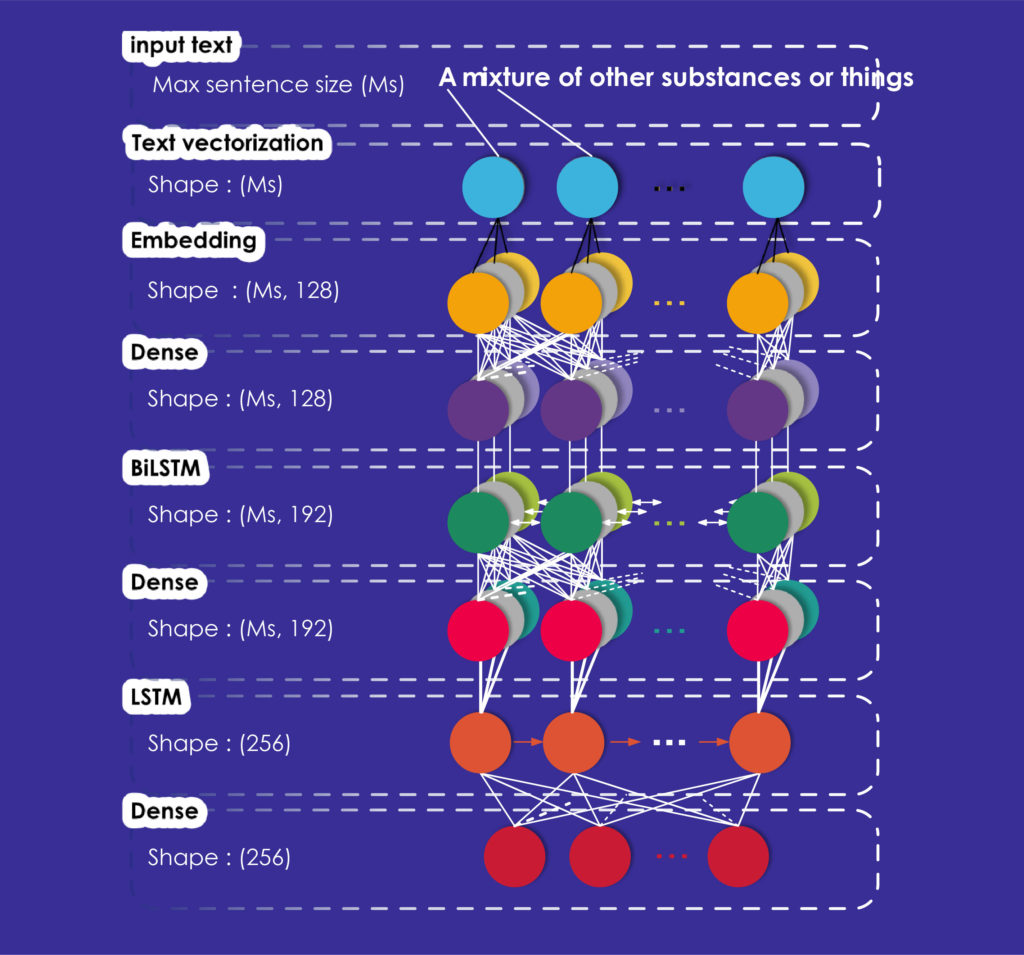
Nuestro segundo modelo, denominado Modelo Avanzado, es una red BiLSTM-LSTM. En cuanto al Modelo Básico, utilizamos un modelo secuencial que puede ser proporcionado por Keras.
Este modelo también comienza con una capa de vectorización de texto, una capa de incrustación y una capa densa que produce vectores. Luego añadimos una capa BiLSTM, que toma una capa recurrente (la primera LSTM de nuestra red) que a su vez toma el "modo de combinación" como argumento. Este modo especifica cómo deben combinarse las salidas hacia delante y hacia atrás; en nuestro caso, se toma la media de las salidas.
A estas tres capas, añadimos otra capa densa totalmente conectada y una capa LSTM de 256 dimensiones correspondientes a las dimensiones de los vectores de salida y una última capa densa con las mismas dimensiones.
Montaje experimental
Dado que en esta tarea compartida se nos propusieron tres tipos de representaciones vectoriales, utilizamos las mismas arquitecturas para producir los tres tipos de vectores. Sin embargo, el formato de los datos de entrada al modelo no es el mismo para los tres tipos. Para los tipos de representación "electra" y "sgns", preparamos un vocabulario que contiene las palabras de las glosas del "conjunto de datos de entrenamiento", las palabras de este vocabulario se obtuvieron siguiendo el paso de preprocesamiento.
Para el tipo de vector "char", construimos un vocabulario de todos los caracteres utilizados en las glosas sin preprocesar los datos. La idea es que, para la representación de tipo "char", el modelo codifica los caracteres de las glosas en vectores y, a continuación, produce la codificación de las glosas en base a los vectores de caracteres que constituyen las glosas.
El modelo que proponemos es un modelo monolingüe (lo entrenamos por separado en el conjunto de datos de entrenamiento de cada idioma). Sin embargo, para evaluar el impacto de utilizar un modelo multilingüe, entrenamos las mismas redes neuronales en cinco idiomas (con vector de caracteres) al mismo tiempo y comparamos los resultados obtenidos con los obtenidos por los modelos monolingües.
Para los tipos de representación "sgns" y "electra", construimos un vocabulario que contiene las palabras de todas las glosas sobre las cinco lenguas, que contiene en total 121.147 palabras. Hicimos lo mismo con los vectores "char", pero preparando en su lugar un vocabulario de caracteres que contiene 405 caracteres, en total. La tabla 1 describe el tamaño del vocabulario para cada modelo monolingüe y para el modelo multilingüe.
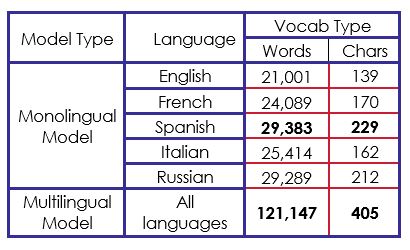
Observamos que, sumando todas las palabras en las cinco lenguas diferentes de los datos originales, hay 129.176 palabras. Sin embargo, nuestro modelo de vocabulario multilingüe da como resultado 121.147 palabras, lo que significa que hay 8.029 palabras comunes entre al menos dos idiomas diferentes.
Resultados y análisis
Nuestro principal objetivo era superar el modelo de referencia y los resultados del organizador.
Nuestro modelo de referencia no obtuvo mejores resultados que los modelos del estado de la técnica, aunque podemos analizar un punto interesante: este sencillo modelo produce sorprendentemente mejores resultados en la medida del coseno de Rank. En los resultados del MSE (error cuadrático medio) medida, sólo tres casos superan al modelo de referencia de los organizadores. Además, todas las medidas de coseno de rango son mejores.
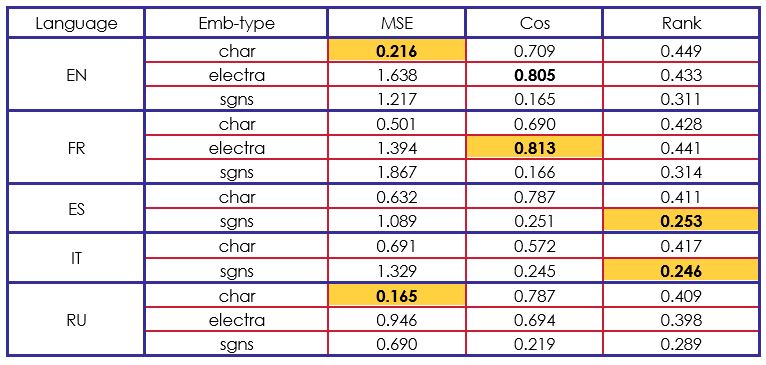
En este punto, podemos analizar que es difícil obtener resultados en las medidas MSE y Coseno, mientras se intenta obtener buenos resultados en la medida Rank y viceversa. Este análisis se apoya en la siguiente evaluación de nuestro modelo avanzado en la tabla 3.
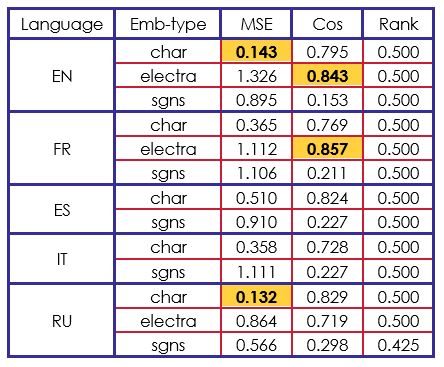
Los resultados de nuestro segundo modelo son completamente opuestos. Hemos obtenido mejores resultados que el modelo del organizador en las medidas MSE y Coseno. Por otra parte, el coseno Rank parece estar atascado en.
Si comparamos nuestros resultados con los de otros participantes, podemos decir que nuestra arquitectura BiLSTM-LSTM es eficiente en las incrustaciones "char" y "electra". Por ejemplo, en "char" con inglés, francés y español, obtuvimos la segunda mejor puntuación del reto.
Teniendo en cuenta el conjunto de resultados obtenidos, encontramos que la mejor puntuación de coseno se obtuvo utilizando incrustaciones vectoriales de electra (contextualizadas) y la mejor puntuación de MSE se obtuvo utilizando incrustaciones vectoriales de caracteres. En general, el uso de la red neuronal de arquitectura BiLSTM-LSTM ha sido beneficioso para obtener resultados que superan las líneas de base cuando se utilizan el coseno y el MSE como medidas de evaluación.
Para concluir
En este artículo, presentamos nuestras contribuciones para resolver el problema de la tarea 1 del reto SemEval-2022. Estudiamos los efectos de entrenar incrustaciones de frases con datos supervisados probando nuestros modelos en cinco idiomas diferentes. Demostramos que los modelos aprendidos con incrustaciones char o incrustaciones contextualizadas pueden rendir mejor que los modelos aprendidos con Skip-Gram incrustaciones de palabras. Al explorar varias arquitecturas, demostramos que la combinación de capas Embedding/Dense/BiLSTM/Dense/LSTM puede ser más beneficiosa que el simple uso de la capa Embedding.
En un próximo artículo presentaremos nuestro sistema de evaluación de la similitud textual semántica a nivel de documento en la tarea 8 de SemEval-2022: "Multilingual News Article Similarity".



