

Conozca nuestro trabajo en la tarea n°1 de SemEval: diccionario inverso
SemEval es una serie de talleres internacionales de investigación sobre el Procesamiento del Lenguaje Natural (PLN) cuya misión es avanzar en el estado actual del arte del análisis semántico y ayudar a crear conjuntos de datos anotados de alta calidad en una serie de problemas cada vez más desafiantes en la semántica del lenguaje natural. El taller de cada año incluye una colección de tareas compartidas en las que se presentan y comparan sistemas de análisis semántico computacional diseñados por diferentes equipos.
En esta edición, SemEval propuso 12 tareas para trabajar.
En este artículo explicaremos cómo procedió nuestro equipo con la tarea n° 8 del desafío: Similitud de artículos de noticias multilingües que consistía en medir la similitud semántica textual entre artículos de noticias en diferentes idiomas. Nuestro objetivo era desarrollar un sistema que utilizara el Procesamiento del Lenguaje Natural (PLN), los métodos de recuperación de información y la inteligencia artificial para identificar artículos de noticias que proporcionen información semántica similar basándose en cuatro características: geolocalización, tiempo, entidades compartidas y narraciones compartidas. Para lograr este objetivo, hay que identificar elementos importantes en el contenido de los artículos de noticias, como el acontecimiento del que se habla, la ubicación, la hora y las personas implicadas.
La tarea de similitud textual semántica (STS) ha sido un tema de investigación en PNL durante muchos años, y se ha celebrado en SemEval desde hace varias ediciones. Pero, en comparación con otras ediciones, este año se ha centrado en medir la similitud entre contenidos de noticias largas y no de frases, fragmentos de textos o textos cortos.
Desafíos de la tarea
Nos encontramos con muchos desafíos al trabajar en esta tarea:
- En primer lugar, el raspado del contenido de la URL proporcionada (en el primer intento, teníamos contenido vacío o incompleto en muchos ejemplos);
- Había muchas lenguas con las que trabajar (algunas lenguas del conjunto de pruebas no estaban presentes en el conjunto de trenes);
- Por último, fue un reto elegir el tipo de puntuación predicha: decimal o entera, que es diferente según el número de anotadores humanos por documento.
Descripción de los datos
Los datos utilizados para el entrenamiento estaban compuestos por 4.964 pares de artículos de noticias escritos en siete idiomas diferentes: Inglés (EN), francés (FR), español (SP), alemán (DE), polaco (PL), árabe (AR) y turco (TR). Las parejas se formaron con la misma lengua o con lenguas diferentes. En el corpus de entrenamiento, siete tipos de parejas eran monolingües y sólo una era interlingüística (DE_EN).
Para el corpus de prueba, había un total de 4 953 pares de artículos de noticias en diez idiomas diferentes. Se añadieron tres nuevas lenguas que eran el ruso (RU), el chino (ZH) y el italiano (IT). En este corpus había ocho tipos de parejas interlingüísticas, con siete tipos de parejas que nunca habíamos visto en el corpus de tren.
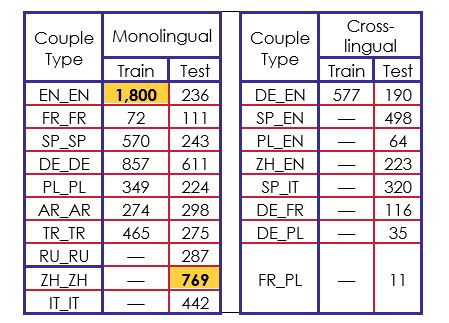
Cada par de documentos fue anotado por uno a ocho anotadores en función de siete categorías de puntuación: "Geografía", "Entidades", "Tiempo", "Narrativa", "Generalidad", "Estilo" y "Tono".. Además, los organizadores proporcionaron los identificadores de los pares de artículos, los idiomas y las URL de cada par. A partir de las URL, pudimos recuperar datos de los artículos como: títulos, textos, palabras clave, etiquetas, autores, fecha de publicación, resúmenes y metadescripciones, junto con otra información irrelevante.
Resumen del sistema
El reto propuesto consistía en elegir entre tres opciones:
- Construir un modelo para cada conjunto de datos de entrenamiento por idioma: Inglés, francés, español, alemán, polaco, árabe y turco.
- Construir un modelo único en inglés (la lengua de referencia mundial y la mejor gestionada por los métodos de PNL) y traducir todos los textos a esa lengua.
- Construir un modelo multilingüe que pueda manejar dos textos en diferentes idiomas.
Hemos optado por construir modelos de aprendizaje en algunos idiomas principales: inglés, francés, español, alemán, árabe y turco. Abandonamos el idioma polaco porque no encontramos ningún modelo preformado adecuado. Cuando dos textos a comparar no estaban en la misma lengua, los tradujimos a la lengua principal seleccionada.
Un punto fundamental para que se genere la puntuación final es la elección sobre la precisión de la respuesta en términos de decimales. Observamos que, en algunas lenguas, la puntuación global obtenida era un número entero. En inglés, por ejemplo, se obtuvo una puntuación decimal y más anotadores. El número real de anotaciones no podía determinarse de antemano. Por lo tanto, hemos definido reglas para completar nuestra evaluación en función de la puntuación obtenida y del idioma. No utilizamos los metadatos de los artículos de noticias porque estaban incompletos. Nos limitamos a conservar tanto los títulos como el contenido del texto.
También nos dimos cuenta:
- Fuertes correlaciones entre la puntuación global y las puntuaciones de Entidades, Narrativa y Geografía.
- El conjunto de datos de entrenamiento está desequilibrado, especialmente en inglés. Teníamos más de cuatro puntuaciones.
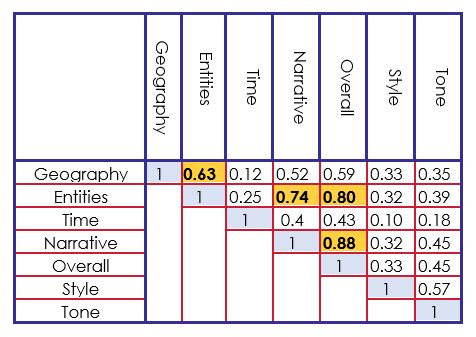
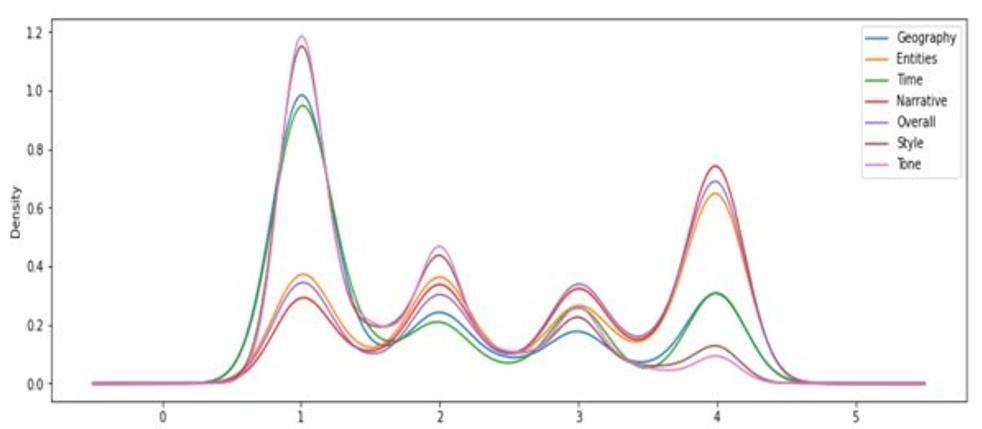
Siguiendo las observaciones que se ven en la tabla 2 y en la figura 1, implementamos un sistema de puntuación basado en cada idioma a las características para alimentar un sistema supervisado. A continuación detallamos nuestras características:
- Una puntuación de similitud de títulos basada en transformadores de frases con un modelo codificador preentrenado.
- Para medir una puntuación de similitud entre estos resúmenes, utilizamos un resumen de texto basado en transformadores preentrenados en cada idioma. Probamos varios modelos con algunos ejemplos y seleccionamos los que parecían ser los mejores. Según el idioma, pudimos obtener uno o dos modelos de resúmenes y, por tanto, una o dos puntuaciones. Los modelos se preentrenaron en diferentes variantes de corpus de resúmenes.
- Se utilizó la identificación y extracción de palabras clave/'key terms' en los títulos y textos de contenido. Las etiquetas extraídas eran nombres, nombres propios, verbos y adjetivos, y se añadían las diez palabras más cercanas desde el punto de vista semántico. A continuación, calculamos el número de términos comunes en ambos textos.
- Se utilizó la identificación y extracción de entidades con nombre común entre los títulos y los textos de contenido, a saber: lugares, personas, organizaciones y fechas. En cuanto a las palabras clave y los términos clave, calculamos el número de entidades idénticas en ambos textos.
- Para las distintas entidades geográficas detectadas (ciudades, regiones, países), utilizamos la puntuación de los lugares de proximidad con geocodificación.
- Utilizamos el modelos de clasificación de disparo cero basado en temas de prensa que definimos manualmente: política, deporte, salud, economía y tecnología. La puntuación de similitud obtenida refleja el número de temas comunes entre dos textos.
- Finalmente, modelos de análisis del sentimiento se utilizaron para identificar si la polaridad del sentimiento es positiva, negativa o neutra en ambos textos. La puntuación de similitud obtenida reflejaba así el número de puntos comunes.
Con todas estas características, fue posible hacer una calificación final basada en la técnicas de clasificación o regresión.
Para la clasificaciónProbamos Clasificador Random Forest y Regresión logística para los algoritmos que lograron el mejor rendimiento.
Para la regresiónProbamos Regresión lineal, Mínimos cuadrados parciales (PLS) y Regressor de árboles adicionales. De este modo, podemos obtener una evaluación final de la estrategia seleccionada. Para optimizar la Correlación de Pearson (la medida elegida por los organizadores para la evaluación), utilizamos Biblioteca PyCaret para comparar todos los modelos posibles (utilizando la validación cruzada con 10 pliegues).
Para nuestro modelo inglésLos distintos elementos encontrados nos permitieron obtener rápidamente un buen rendimiento (aproximadamente 0,85 de correlación de Pearson). La única preocupación era el fuerte desequilibrio del conjunto de datos de entrenamiento que necesitábamos reequilibrar.
El modelo francés tenía un conjunto de datos de entrenamiento pobre (sólo 72 ejemplos de pares). Por lo tanto, seleccionamos un modelo más eficiente Modelo de transformación NER (Named Entity Recognition) que Spacy. También nos centramos en optimizar el modelo turco de la misma manera con un Transformador NER. No hemos trabajado para optimizar el modelo alemán, que podría haber sido mucho mejor.
Montaje experimental
Aplicamos nuestros modelos de puntuación a cada par de títulos y textos de contenido. Para el idioma polaco y los nuevos idiomas observados en el conjunto de datos de evaluación, todos los textos se tradujeron al inglés con la biblioteca Deep Translator y luego se aplicó el modelo inglés. Cuando había dos idiomas diferentes, se traducían al inglés.
Resultados y análisis
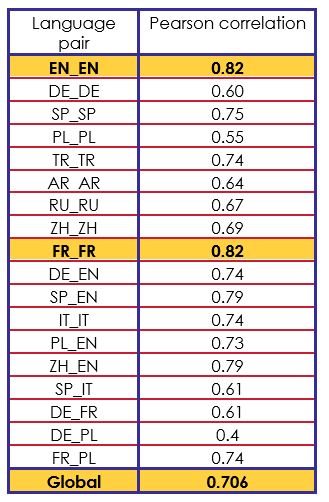
Nuestra correlación de Pearson final en el corpus de prueba fue de 0,706. Indicó resultados muy irregulares en función de la lengua de los pares. Cuadro 3 muestra los resultados obtenidos en el corpus de prueba para cada tipo de pareja lingüística.
El resultado final para una lengua específica fue generalmente consistente con las evaluaciones realizadas previamente en el subconjunto (validación cruzada) del conjunto de datos de entrenamiento.
En cuanto a la parte de la traducción, observamos una rápida deriva según los idiomas: los ejemplos ZH_EN traducidos al inglés siguieron siendo muy correctos (0,79), pero los ejemplos ZH_ZH sólo obtuvieron una puntuación media de 0,69. De este modo, tuvimos una reducción significativa del rendimiento en IT_IT (0,74) y SP_IT (0,61) en comparación con los casos en los que se utilizó el inglés.
Descubrimos que la mayoría de las grandes desviaciones en la evaluación estaban relacionadas con errores de raspado (texto en blanco o incoherente).
En conclusión, observamos que las puntuaciones de 71% de las parejas eran excelentes (por debajo de 0,1), 84% eran buenas (por debajo de 0,5) y 96% por debajo de 1. Creemos que nuestros modelos en inglés, francés, turco y español son correctos y podrían haberse optimizado más limpiamente. Tuvimos dificultades técnicas para hacer un modelo árabe correcto, al igual que para el modelo alemán.
Conclusión
Nuestro sistema utilizó diferentes características que reflejan la similitud que puede obtenerse, por ejemplo, entre los términos clave compartidos y las entidades con nombre, o incluso los temas mediante el uso del aprendizaje de tiro cero para los sistemas de clasificación de textos. Además, utilizamos la geolocalización para las entidades de localización y medimos la similitud semántica mediante el uso de incrustaciones léxicas a nivel de frase (título del texto) y de párrafo (resumen del texto obtenido automáticamente mediante el uso de transformadores).
Más allá del uso de un sistema supervisado para medir el grado de similitud entre dos textos dados, nos encontramos en un contexto de documentos que pueden provenir de diferentes lenguas procesando tanto pares de documentos monolingües como pares de documentos translingüísticos. Dado que el corpus de prueba puede contener documentos escritos en lenguas naturales no procesadas durante la fase de aprendizaje, nuestro sistema pudo realizar una traducción automática a una lengua pivote para proyectar los nuevos documentos en espacios ya conocidos
Obtuvimos una puntuación de correlación de Pearson de 0,706 en comparación con la mejor puntuación de 0,818 de los equipos que participaron en esta tarea.



