
Nowadays, societies evolve at a fast pace. These evolution involve changes in our tools. It’s the case with software, they must evolve and stay updated to answer our needs. But, how to make sure software answer our needs despite evolution? A popular and effective way is testing. A test will check a software behavior to detect possible bugs and make sure it matches to the expectation. In this article we’ll focus on functional testing before releasing a software. Those tests are realized with various scenarios which are composed of sequences. When the sequence comes to its end, it produces a business added value which is compared to the expectation of the tester.
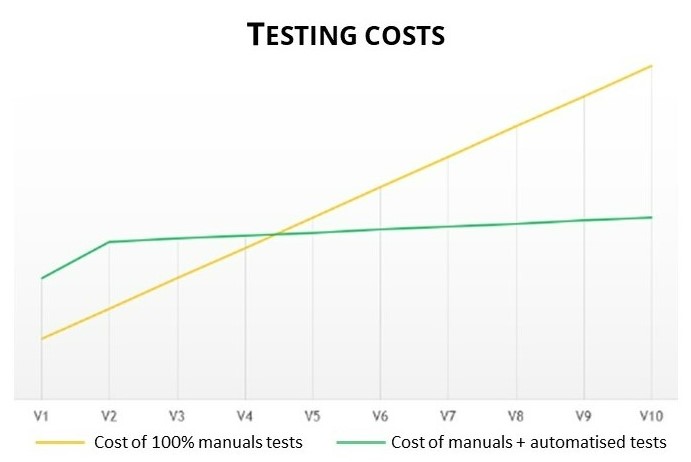
When a software is composed of different software components, it’s humanly impossible to implement testing because the number of scenarios is too important due to the interactions of the different components, so all the scenarios are not tested. An other important point is the maintenance cost to keep the software updated. That’s why searchers have tried to automatize a part of those tests. As you can see on the figure 1, the automatization has well reduced the maintenance cost in time.
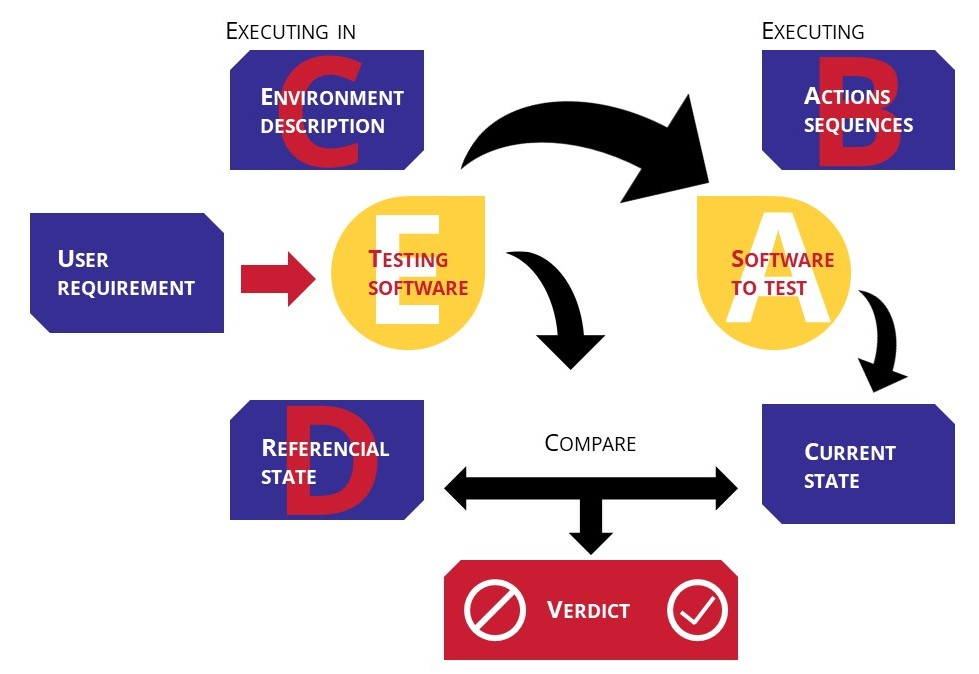
Last progress on Artificial Intelligence gives new opportunities to the hyper automatization testing. The objective is to create a generic software system almost self-sufficient able to verify a software behavior. To work, the software system tester would need to be composed with different data (figure 2):
A. A software to test,
B. Action sequences to realize. Those action will be data to input by the testing software,
C. Contextual and technical data describing the environment the tested software evolves in,
D. A referential state (in line with the expectation),
E. A tester able to compare the test result state with the referential state to interpret the result and give a verdict.
This is an ambitious objective as the artificial intelligence would need to independently generate all the listed data instead the tested software (A). Nowadays a strong artificial intelligence able to do it hasn’t been created.
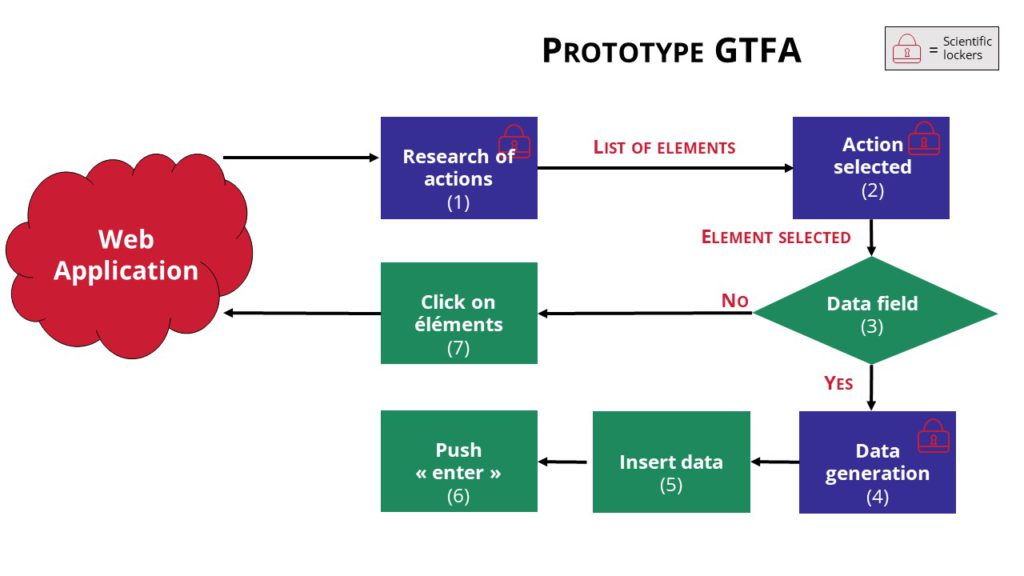
To start this project, we decided to simplify it and only work on a software tester (E) able to explore an other software automatically. We supposed that: the test evaluation is the number of state the software has explored (more state it explores, better it is). It would mean the software can test action sequences untested yet with low human manipulation.
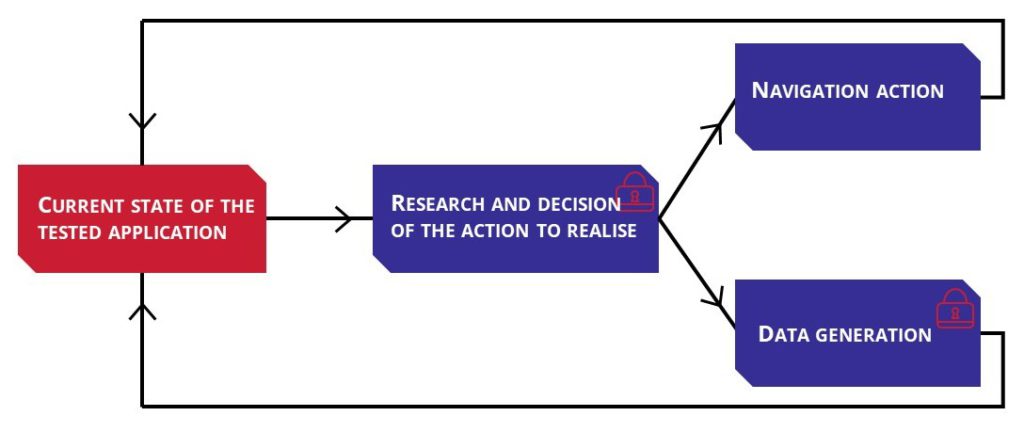
To “explore” the other software (A), the tester (figure 3) will need to first determine the action to realize. This first step can be considered as a “locker” because despite research, it hasn’t been solved yet. On the second step, the tester has two possibilities: generate data (which present another locker) and navigation action (clicking on button for instance). If it can’t generate data, it will try a navigation action then determine if the tested software state has changed and will reason on its own on what to do next. It simplified the problem, but it doesn’t make it easier.
The State of Art
Generations of searcher worked on this problem on two different levels:
1st On an industrial level (it lists tools and framework usable by everyone) with a direct approach. It deducts the code isn’t the easiest language to interpret by everyone, it brings bugs and important cost of maintenance so they semi-automatize the tests to win time on it. This solution if efficient on small or middle size informatic system.
On the second level, the approach is less direct. First, they deduct knowledge on the tested software and input them in a chosen method more or less intelligent like Web Mining or Monkey tester but those methods don’t generate data.
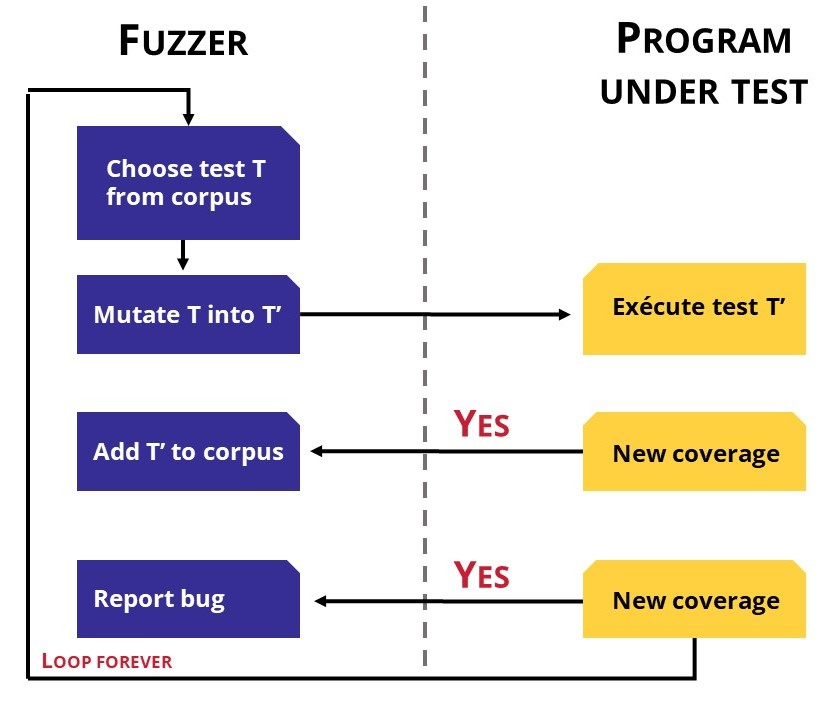
To create a searching intelligent application, it is necessary to generate data. A scientific approach is the fuzzer testing. The fuzzer will generate from a seed. Some of them generate random data (figure 4), other will learn on their own. For instance, if the generated data comes to a new state, the data will be added to the data test but if the resulting state in an error, the bug is reported. But this method doesn’t consider the business environment.
Other fuzzer type based on artificial intelligence like Evolutionary-Based fuzzer will improve some step with Machine Learning and add profession knowledge in the process.
Automatic learning solutions like Q-Learning, neurons network or GAN (Generative Adversarial Network) are good tracks to follow too.
The study of the scientific state of art shows automatizes generation methods. Even if those methods are adaptive from an application to an other, they don’t take many information on the business dimension into account. So the exploration doesn’t generate consistent business scenario. A solution would be to input business preconception to generate more coherent scenario and data. Though business preconception are hardly listable on complex software systems.
This conclusion about the existing state of art, brought us to lead a study on a prototype conception answering the problematics. The method we used exposed as much as possible our prototype to the identified lockers.
Detection and selection of actionable element
We based our project on a middle size existing web application.
Automatic interaction has been made possible with a special program (into our Selenium) able to act on the HMI (Human-Machine Interface) – like clicking or text writing (figure 5).
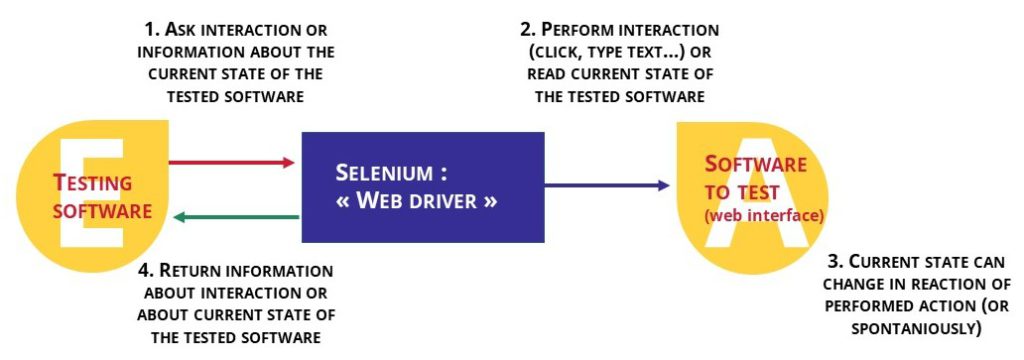
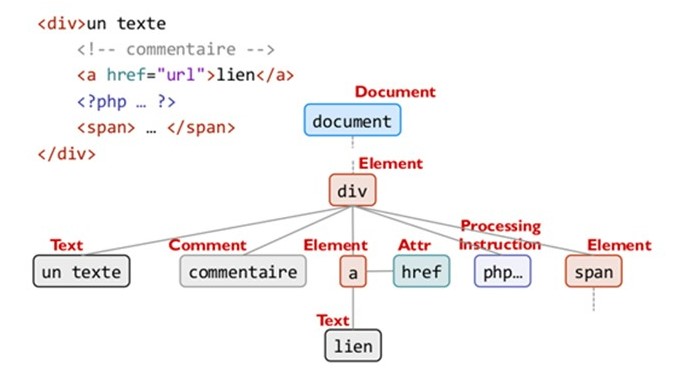
It can also read the DOM (Document Object Model) (figure 6) and detect the actions possibilities on the website page.
When a button on the page is clicked, it products an event which change the state of the DOM (so on the web page). Through the DOM, we found a solid way to determine if an element of the DOM will cause an event or not. Once all the actionable elements have been detected in the DOM, one is activated by Selenium. Its activation will eventually modify the DOM, then a new research of actionable element starts. The program calculates a print of the original DOM, then register all the DOM version generated to recognize the state of DOM already encountered and not repeat a same action. If the DOM is composed of professional data, the exploration will be oriented scenario.
This method is a good way to detect all the possible actions, but it shows its limits. Sometimes, the actions listed can’t be activate for different reasons:
- Even if it is visible, an element can be partially or totally covered by an other (see figure 7)
- The element is outside of the screen
- The element is too small
Part of those cases are automatically managed. For instance, in the case of superposed elements, the click can be intercepted by a parent element. It results in an error. Though, all cases aren’t managed (like outsider elements) and the management takes longer to process.
As all visible elements are not actionable, we added a visual analyze to the DOM analyze. Each element of the DOM is colorized to define a zone to attribute the click. Combining the two methods allow to detect all the actionable elements and determine if they are actionable in the zone the analyser is.
On some cases, the DOM analysis shows its limits. With some Framework (like ReactJS) which don’t feed their DOM as usual but use their own event models. New dynamic trend of the web application makes the analysis very difficult as the DOM is always changing. We didn’t work on the scroll case in our study, but it brings a strong combinatorial complexity, and would request a better synergy between the DOM and visual analyses.
Data generation
We worked on the data generation through artificial intelligence. We questioned ourselves on how it would help to generate sufficient professional data. We crossed the data generated by fuzzer with those from the Q-Learning.
In this architecture (figure 8) the fuzzer generate from implemented seeds already selected by the Q-Learning. The Q-Learning base its choice on contextual data from the application. For instance, if it detects a field “name”, the Q-Learning will associate it to a “textual” seed. The reward function of the algorithm (which allow it to learn on its experience) is based on the validation or reject of the form.
From our study of the state of the art, we can conclude that it’s very difficult to create an hyper automatized solution able to be versatile on different level and business environment. To do so, different scientific lockers have to be solved: determine action to realize, data generation, detection of a new state.
Though the DOM analysis combine to a visual analysis is interesting do determine accurately realizable action, even if problems still exists (the scroll for instance).
It’s very difficult to create a generic software without user requirements inputs because website are build in different way.
Through our study we learned about existing tester tools trend and different analysis approach. Considering the main scientific lockers identified, we couldn’t find a satisfying answer, but we’ll remind our state of the art study and crucial knowledge for our future work.



