
PREAMBULE
Cette page propose des résultats d’analyse du corpus du Grand Débat National réalisé au sein de la DRI à Berger-Levrault. L’objectif de cette page est d’illustrer des analyses possibles sur ce type de corpus textuel. Nous nous sommes efforcés d’etre le plus transparent possible dans les techniques effectuées.
ACCUEIL
Le grand débat est d’intérêt pour les citoyens français. C’est donc tout naturellement qu’au lendemain de l’annonce de la création de la plateforme nous avons commencé à investiguer comment nous pourrions contribuer à ce grand projet de démocratie participative. A l’aide de nos jeunes chercheurs, nous avons donc rapidement commencé à expérimenter le champ d’action possible en termes de Text Mining et de traitement du langage naturel (TAL). Voilà pour Berger-Levrault un exercice intéressant, permettant de mettre à l’épreuve les techniques de linguistique face à un projet démocratique ambitieux. Pour comprendre nos analyses, il est tout d’abord important de comprendre l’exercice du Grand Débat National. Quatre grandes thématiques sont proposées aux citoyens, à savoir :
- Démocratie et citoyenneté
- Fiscalité et dépenses publiques
- Transition écologique
- Organisation de l’État et des services publics
Pour chaque thématique, il est possible de répondre à un questionnaire rapide fait de réponses à choix multiples et aussi de faire une proposition sous la forme d’un questionnaire composé majoritairement de questions ouvertes. Chacun des quatre questionnaires de propositions est composé d’un titre, de réponses à choix multiple, et de réponses en texte libre. L’analyse des réponses à choix multiple étant particulièrement triviale (i.e. il suffit de compter les réponses), elle n’a pas attiré notre attention.
Néanmoins, les propositions et leurs contributions en texte libre nous ont amené à penser qu’un travail d’analyse serait intéressant (et nécessaire) et que les compétences de nos scientifiques pourraient y contribuer.
Une double question s’est alors posées à nous :
- Quels outils sont à notre disposition pour comprendre le contenu de ce corpus textuel ? et
- Quelles analyses, questions aimerions nous poser à ce corpus pour en comprendre son essence ?
Ces deux questions sont évidemment interdépendantes l’une posant le champ des possibles et l’autre relevant de la pertinence des analyses.
Nous avons tout naturellement approché le problème sous l’angle de la fouille de données en utilisant des techniques quantitatives relativement simples. A savoir, quelle quantité de participants, de réponses par topic et quelle distribution géographique en termes de participation.
Nombre de contributions
individuelles analysées:
375357
Nombre de réponses
analysées:
4655044
En termes de participation, les quatres sujets ont suscité un nombre signficatif de contributions. On notera tout de même une participation plus important sur les thèmes de Fiscalité et dépenses publique et sur Transition ecologique. Cela est probablement l’indicateur que ces deux sujets sont les plus importants pour les citoyens.
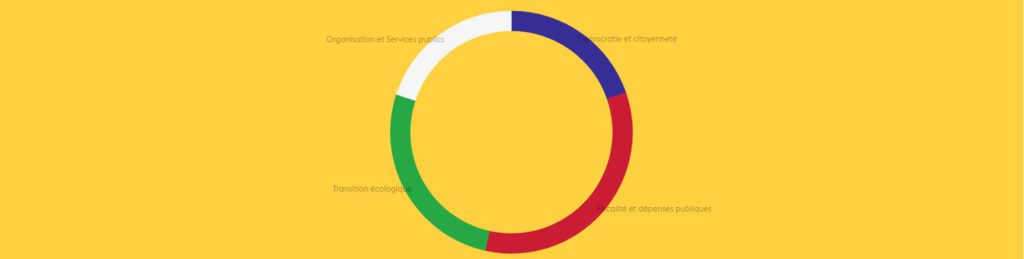
Répartition des contributeurs par sujet
Nous avons également regardé la répartition de la participation par département. Il est important de noter que la localisation de la participation est fournie par les contributeurs en donnant leur code postal et non pas par un mécanisme de géolocalisation. Tout d’abord, nous avons produit une carte illustrant le nombre de participation par département. Cette dernière met en évidence que les départements 75 ,78, 33, 31, 69, 34, 59, 44 et 13 comptent le plus grand nombre de contributeurs. Ces zones de France étant parmi les plus peuplées ce résultat n’est pas surprenant.
La deuxième carte montre la répartition de la participation par département pondérée par la population du département (données de population INSEE 2016). Ici, le résultat est plus étonnant montrant à l’inverse que le Calvados (14) et les Alpes-Maritimes (06) participent fortement en regard du volume de leurs habitants.
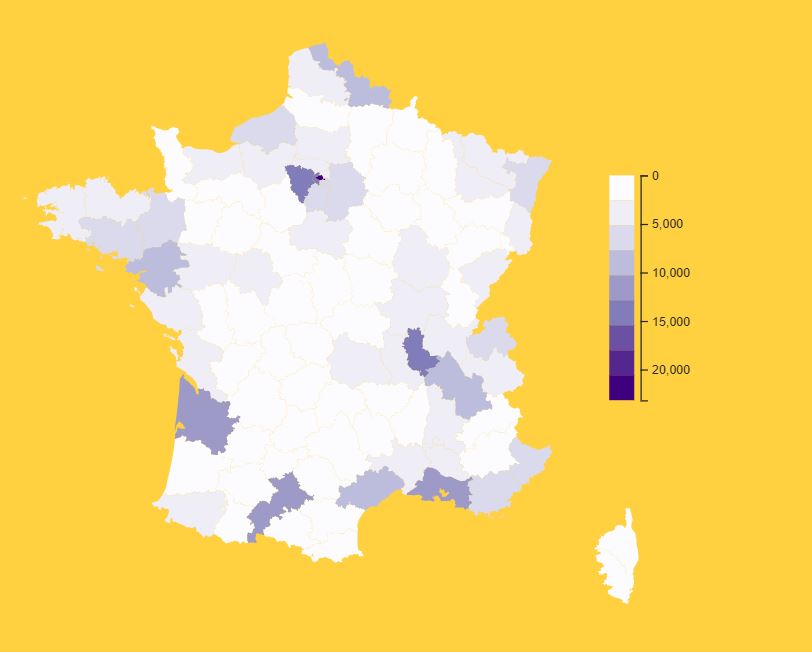
Carte 1: Répartition par département du nombre de contributions
(sur la base des code postaux fournis par les contributeurs)
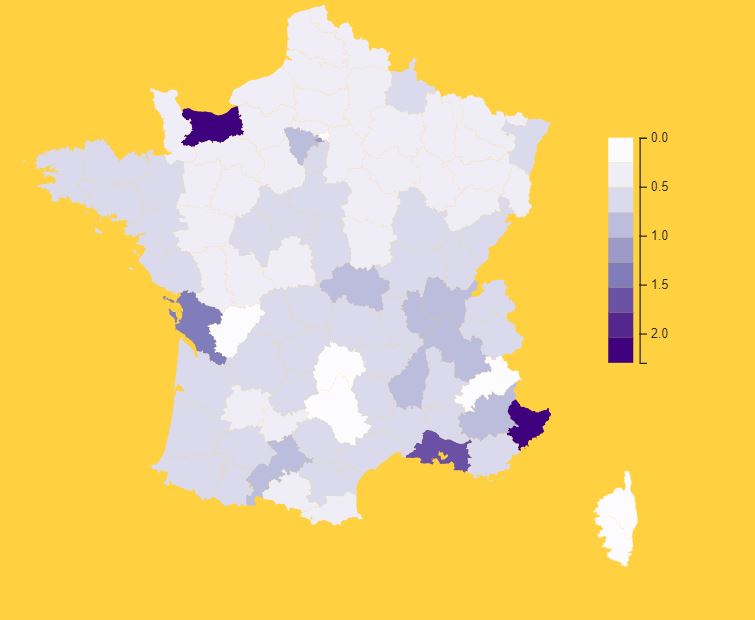
Carte 2: Répartition par département du pourcentage de contributions par la population
(sur la base des code postaux fournis par les contributeurs)
Nous avons ensuite tenté d’aller plus loin en questionnant les contenus en texte libre pour chacune des quatre thématiques. L’ambition était de cerner les sujets discutés dans chacune des thématiques et de les prioriser. Nous avons donc cherché à comptabiliser les expressions contenues dans le texte libre. Ces expressions composées de plusieurs mots sont appelés n-grammes. (https://fr.wikipedia.org/wiki/N-gramme).
A ce stade, la difficulté principale réside dans l’identification de ces n-grammes. Pour un ordinateur le texte n’est ni plus ni moins qu’un signal totalement dénué de sens. Il est donc nécessaire de lui indiquer les mots, ou plutôt groupes de mots qui sont intéressants dans notre langue. Par exemple, “transport en commun” est un n-gramme composé de trois mots qui a du sens en français, alors que “voiture soleil” ne veut à priori rien dire.
Pour identifier des n-grammes dans un texte il est nécessaire de travailler avec un corpus correctement formatté, des étapes de pré-traitement sont nécessaires. Il est par conséquent nécessaire de lemmatiser le texte, de corriger certaines fautes d’orthographe ou de ponctuation (e.g. meme peut devenir même ou mémé) et enfin de filtrer tous les mots vides (https://fr.wikipedia.org/wiki/Mot_vide) ou stop-words en anglais.
La lemmatisation (https://fr.wikipedia.org/wiki/Lemmatisation) consiste à donner une forme neutre et canonique à un mot. Ainsi les mots petit/petits/petite/petites sont remplacés par un seul terme (petit dans notre cas) pour uniformiser le traitement du texte. Le schéma ci-dessous illustre la méthode de comptage que nous avons employé et les différentes étapes de traitement que nous effectuons sur les données.
Pour parvenir à tous ces traitements, nous nous sommes appuyés sur une base de données provenant d’expressions françaises issue du projet Universitaire Jeux de mots. Nous avons ensuite complété cette base de données avec quelques expressions et lemmes manquants. Les listes utilisées dans nos analyses sont téléchargeables ici.
Une fois ce comptage réalisé, nous avons généré des représentations graphiques de ces données. Nous avons produit des nuages de mots et des histogrammes pour chacune des quatres grandes thématiques du grand débat.
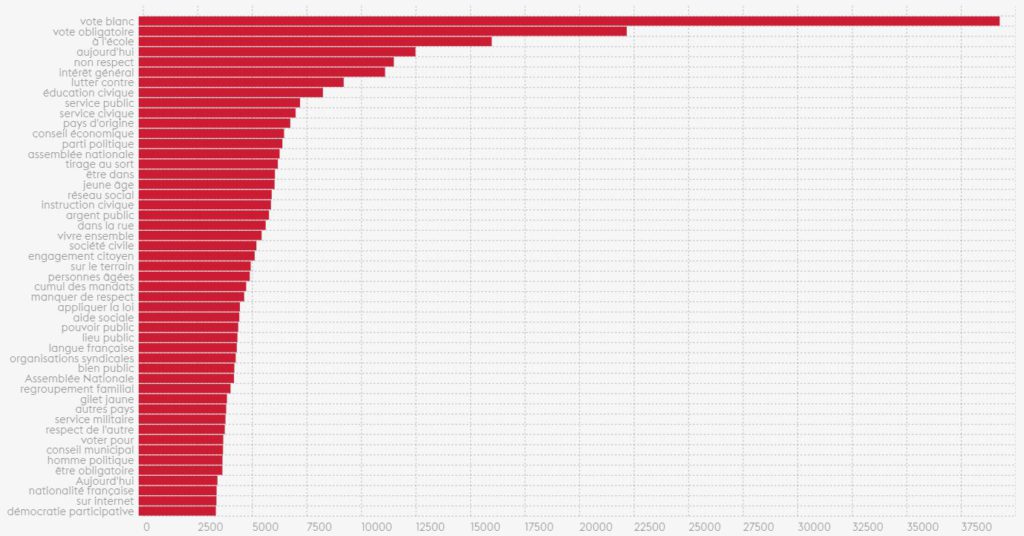
La démocratie et la citoyenneté
Pour le thème démocratie et la citoyenneté, un thème se distingue clairement des autres: Vote blanc. Nous sommes donc en capacité de dire qu’il s’agit du terme le plus discuté dans ce premier thème. Comme le montre bien l’histogramme, vote obligatoire, à l’école et non respect sont les trois termes suivants en termes d’importance.

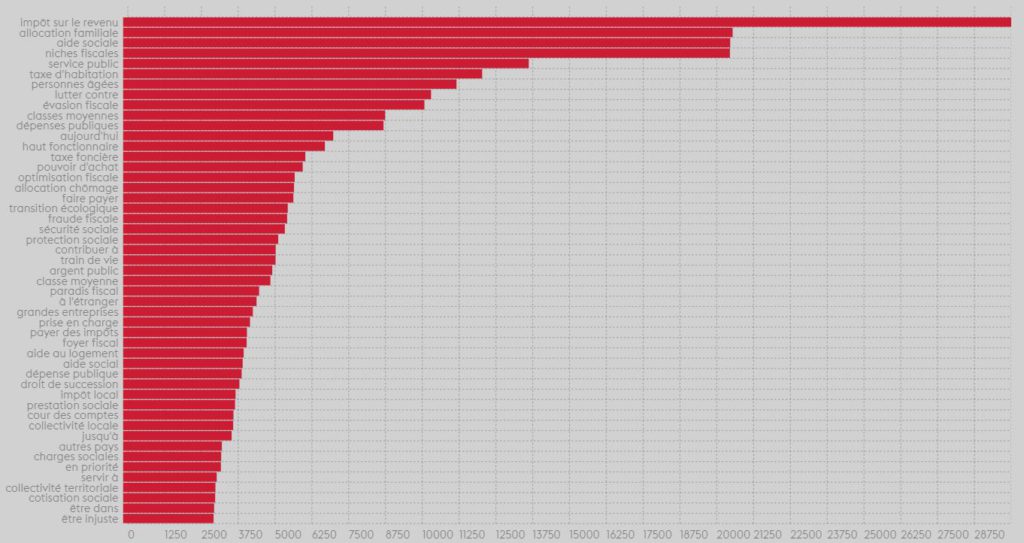
La fiscalité et les dépenses publiques
Pour le thème fiscalité et les dépenses publiques, la distribution des sujets est plus nuancée. l’impot sur le revenu arrive en tête, suivi de près par aides sociales et niches fiscales. Un deuxième groupe de sujets d’importance suit, composé d’allocations familiales, de taxe d’habitation et d’évasion fiscale.

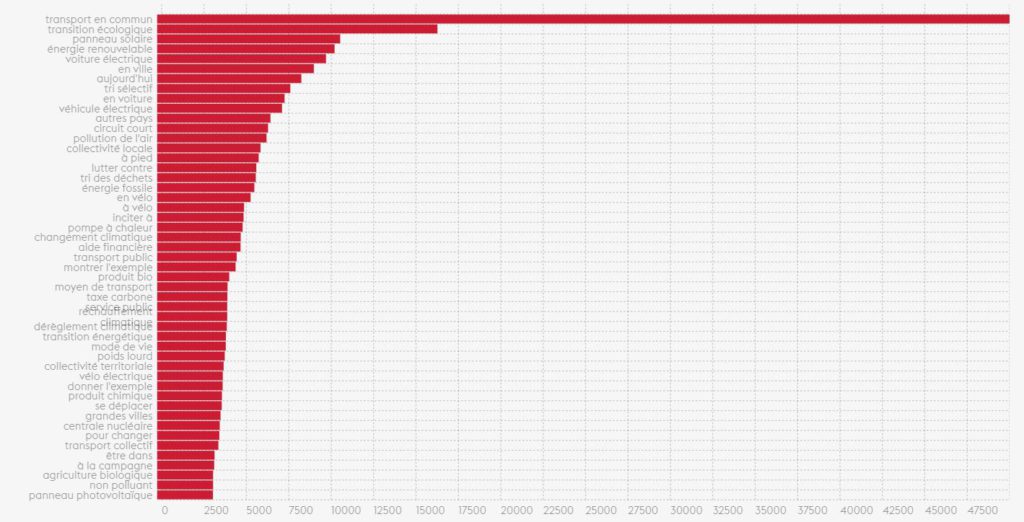
La transition écologique
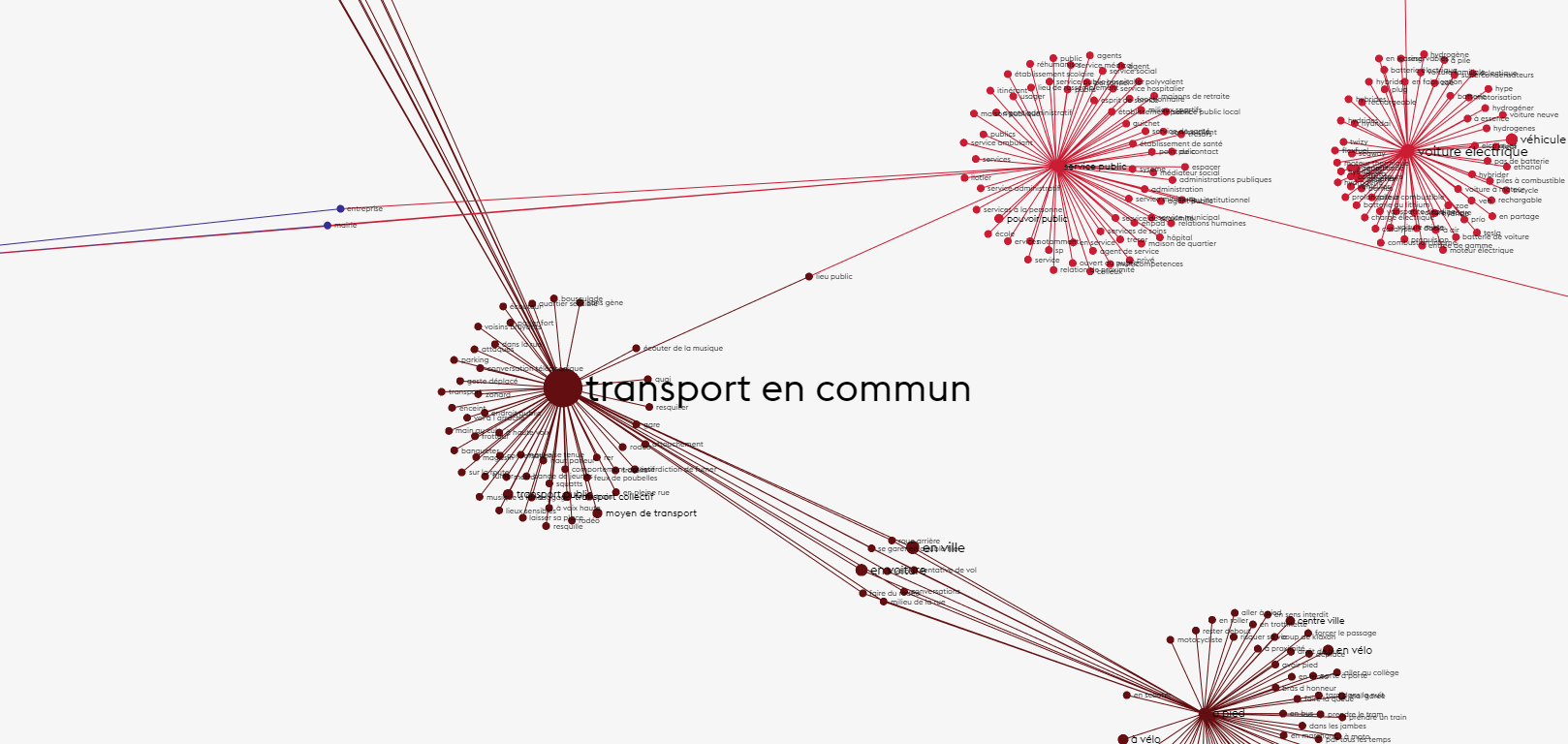
Pour le thème transition écologique, le focus des échanges est sans équivoque. Nos concitoyens parlent de transport en commun. C’est le sujet qui de très très loin ressort des réponses.

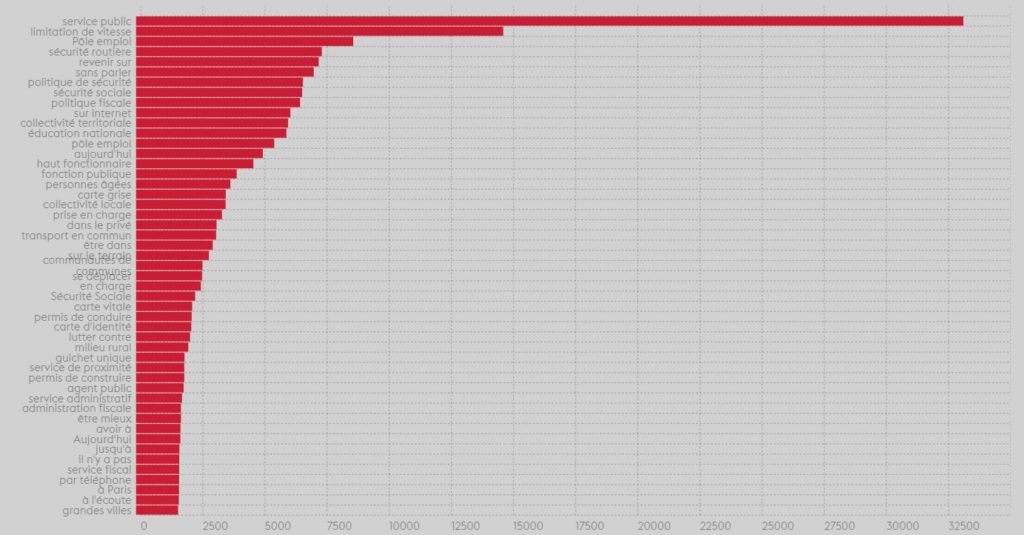
L'organisation de l'État et des services publics
Pour le thème Organisation de l’État et des services publics, le sujet du service public arrive en tête ce qui n’est pas surprenant puisque c’est l’objet principale du thème. Par contre, on notera les trois sujets suivants à savoir limitation de vitesse et sécurité routière qui sont à rapprocher d’une préoccupation de déplacements automobile et Pôle emploi qui suggère une focalisation sur les problématiques liées au chômage.

CONNEXITE DES SUJETS PAR THEME
Bien que ces premières analyses nous informent sur la nature du contenu des contributions ouvertes du grand débat national, elles ne sont pas suffisantes pour donner du sens et comprendre dans le détail le contenu des échanges.
Pour aller plus loin, nous travaillons désormais sur de nouvelles analyses impliquant des algorithmes plus évolués, dont certain entre dans la catégorie de l’Intelligence Artificielle. A titre d’exemple, nous utilisons l’algorithme ‘Word2Vec’ un réseau de neurone dédié au traitement du langage naturel (https://skymind.ai/wiki/word2vec). Cet algorithme permet de calculer un vecteur pour chaque mot d’un corpus textuel. Le but et l’utilité de Word2vec est de regrouper les vecteurs de mots similaires dans un espace vectoriel. C’est-à-dire qu’il détecte mathématiquement les similitudes entre mots. Word2vec crée des vecteurs qui sont des représentations numériques distribuées des caractéristiques des mots, tenant compte du contexte individuels des mots. Ce qui est étonnant c’est que cet algorithme fonctionne sans intervention humaine. Il n’y a donc pas besoin d’avoir un corpus annoté par l’être humain comme le nécessite beaucoup d’algorithmes d’apprentissage machine.
Avec suffisamment de données, Word2vec peut faire des suppositions très précises sur la signification d’un mot à partir des apparences passées. Ces suppositions peuvent être utilisées pour établir l’association d’un mot avec d’autres mots (par exemple, “homme” est à “garçon” ce que “femme” est à “fille”), ou regrouper des documents et les classer par sujet.
Dans la suite nous présentons, par theme, des graphes représentants les résultats de Word2Vec. Les gros noeuds sont les 30 premiers n-grammes ressortant en termes d’occurrence dans l’analyse précédente. Pour chaque gros noeud, les petits noeuds sont les 70 termes connexes ayant les plus forts vecteurs (donc ayant la plus grande probabilité de proximié sémantique). La taille des noeuds est fonction du nombre d’occurrence du n-grammes dans le corpus. Plus un n-gramme est présent plus son noeud est gros.
ATTENTION: Les couleurs n’ont pour l’instant aucune signification (si ce n’est d’aider à la distinction des noeuds) et la longueur des arc et le placement des noeuds est calculée automatiquement pour minimiser les chevauchements (nous utilisons l’algorithme ForceAtlas2).
Le graphe est zoomable et les noeuds sont cliquables pour isoler leurs voisins.
La démocratie et la citoyenneté
La fiscalité et les dépenses publiques
La transition écologique
L'organisation de l'État et des services publics
A VENIR
Nous tentons également de définir des métriques pertinentes pour classer automatiquement les réponses à chacune des questions. L’ambition est de pouvoir identifier s’il existe des grandes catégories de réponses/proposition pour chaque question des quatre thèmes. Ainsi nous serions en mesure d’identifier les grandes tendances dans les contributions des citoyens. Des algorithmes non-supervisés tel que ‘DBScan’ et ‘K-Means’ sont en cours d’expérimentation.
Cette page sera mise à jour dès que nous aurons de nouveaux résultats pertinents. Nous y expliquerons également les méthodes et algorithmes utilisés, et les limites de nos résultats.



