
CONTEXTE
Les documents des marchés publics manifestent une hétérogénéité importante et des similarités trompeuses. Autrement dit, ces documents contiennent généralement des informations typiques comme le nom de l’organisme public, son code SIRET, sa géolocalisation, des dates, les critères et les modalités de choix des candidats, etc. Toutefois, ces informations sont généralement présentées sans aucun format structuré et elles sont exprimées de plusieurs manières.
L’ambition est alors de construire un système qui va permettre à un utilisateur de lancer une requête de recherche et de récupérer un ensemble de documents des marchés publics jugés pertinents par rapport à la requête effectuée. Ensuite, à partir des résultats retournés, une phase d’extraction d’informations, d’entités et de connaissances est réalisée.
De surcroît, cette application illustre une démonstration d’un moteur de recherche, une classification automatique de documents par leur type de marché et finalement une extraction d’informations et des entités d’intérêt.
L’approche utilisée se croise avec plusieurs domaines scientifiques comme la recherche d’information, le traitement du langage naturel et l’apprentissage automatique.
Les technologies impliquées sont basées principalement sur le langage Python et ses librairies (e.g. Flask, Whoosh, Scikit-learn).
Démo 1: MOTEUR DE RECHERCHE D'APPEL D'OFFRE
L’intérêt est de permettre à un utilisateur intéressé par les documents de marchés publics la possibilité de lancer des requêtes et récupérer des documents jugés pertinents par rapport à ces requêtes. Ce système de recherche se base sur l’indexation de documents et il renvoie comme résultats un ensemble de documents classés par un score de pertinence (e.g. Okapi BM25).
Démo 2: EXTRACTION D'INFORMATIONS
Comment ca marche ?
Après la phase de recherche de documents, une phase encore plus importante est exigée. Cette dernière correspond à l’extraction automatique d’informations et d’entités (e.g. la date limite de remise des offres, le type du marché, les critères d’attribution d’un marché).
L’extraction se fait en suivant le schéma ci-dessous :
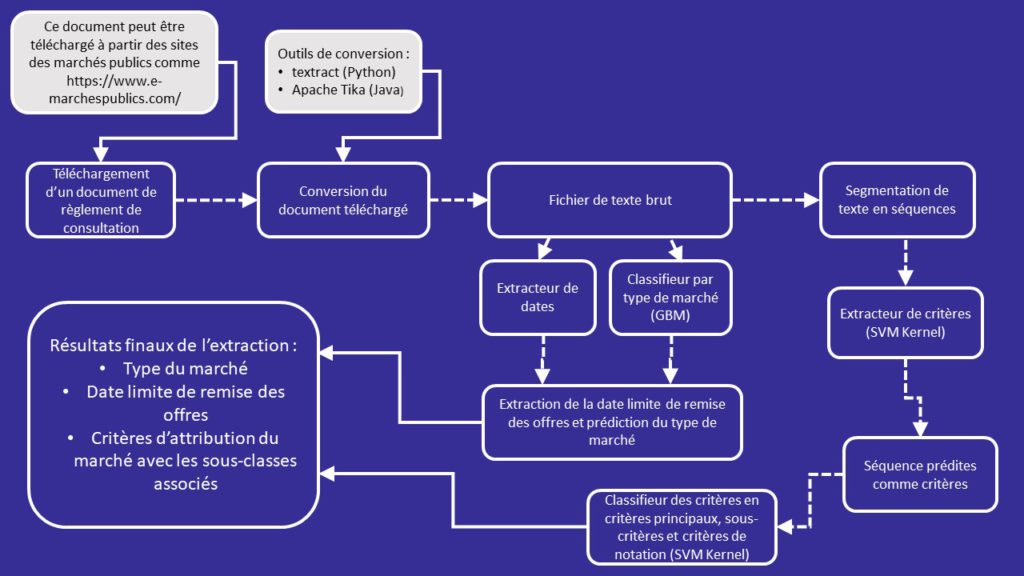
A cette fin, nous avons construit trois robots :
- Le premier qui se base sur une recherche locale avec un pattern assez général d’extraction de la date ;
- Le deuxième qui est une machine intelligente de type GBM et qui tente à classer chaque document selon son type de marché ;
- Le dernier qui combine deux machines intelligentes, de type SVM, entraînées dans un cadre de classification en cascade :
- La première machine prend en entrée un document en texte brut et renvoie en sortie un bout de texte contenant les critères ;
- La deuxième machine va prendre comme input la partie textuelle prédite comme critère et va appliquer une classification plus fine en détectant les critères principaux, les sous critères et les phrases spécifiant la notation appliquée.



