Before total digitalization, the invoices were visually checked by the agents. Today the invoices are entirely dematerialized, therefore nobody checks their layout, readability, and consistency with their metadata. In France, controlling an invoice dataflow (ORMC: Order of Multi Creditor Receipt) can take up to 1 full day. ORMC data flow is sent by more than 10 of our products such as Sedit GF, eGFEvolution, BL.enfance, E.FACTU (STD) Standard, E.FACTU (PTL) Point de livraison, E.FACTU (EAU) Eau et assainissement, MILORD EAU, MILORD FACFAM (Facturation aux familles), MILORD FACT97 (facturation diverses), MILORD HEB98 (Facturation EHPAD).
DeepFacture is a tool that solves the above-mentioned problem thanks to its many strong points :
- Fast training: only about twenty annotated documents allow AI to learn and function.
- Powerful: 1 second is enough to analyze a document. 4 min for a flow of 260 invoices!
- Pooled: DeepFacture is APIised (REST / Open API 3.0), Cloud-Ready, easy to integrate & accessible to all.
- Extensible: can be extended to all standard documents: Tickets, Newsletters, Identity cards, Passports, Cheques, Vehicle registration documents, letters, Forms, etc…
- Search: the fruit of our research in image analysis and Deep Learning over the years.
- Open Source: exclusively based on open-source libraries from the academic world.
How does it works
Berger-Levrault’s products for local authorities generate invoice flows that are sent to the DGFIP in XML format. Regulations impose a certain number of rules concerning the form and content of these flows, as well as the graphic charter of the invoices. The following figure illustrates an example of these rules. The sender and recipient address frames must be positioned in specific locations. The values of these fields must also be similar to those mentioned in the XML tags of the flow.
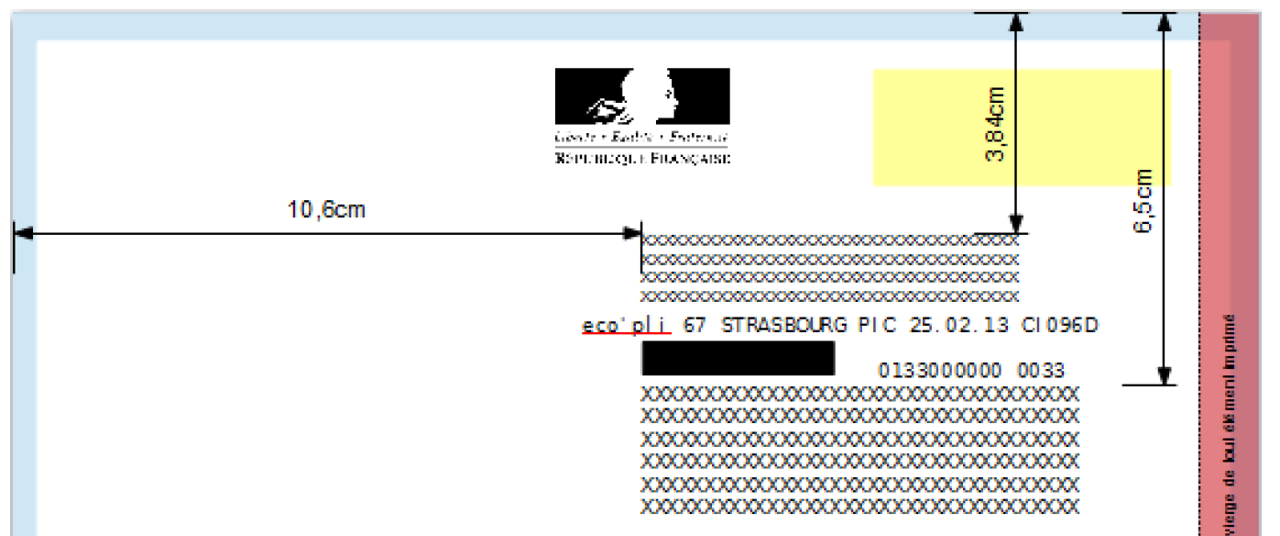
A flow that does not comply is systematically rejected by the DGFIP. Indeed, non-compliance can have harmful consequences for thousands of people: non-receipt of mail due to a non-readable or incorrectly positioned address, failure to take into account a payment, duplicates in the DGFIP database, etc. In order to ensure that the flows generated to comply with the regulations, it is important to include a control phase in the process that explores all the invoices and checks that all the rules are complied with. This control phase is currently carried out by human staff. It is repetitive, tedious, and time-consuming work. Indeed, for a given flow there are dozens of checks to be made on hundreds of invoices. Checking a flow can take several hours.
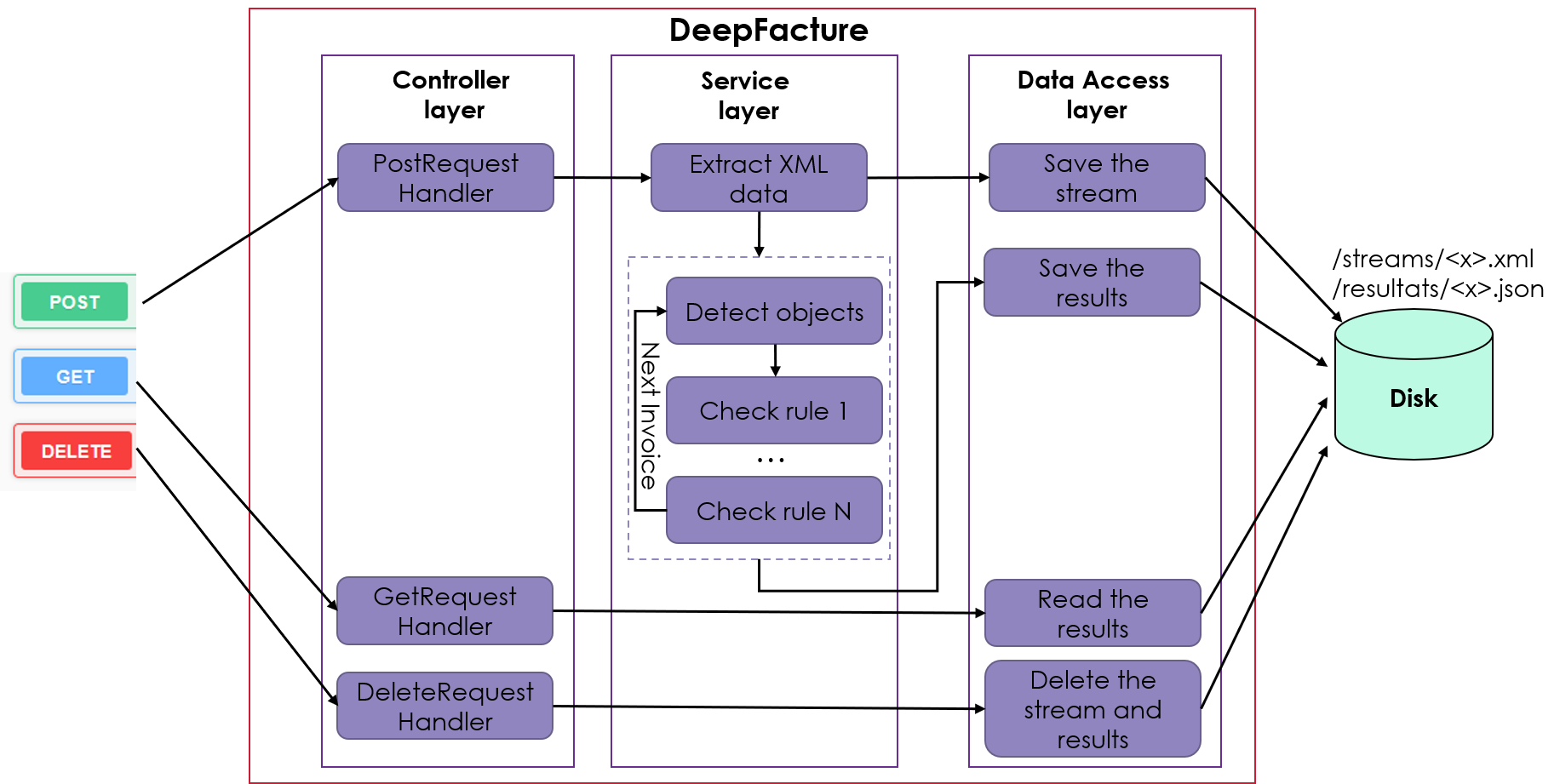
The objective of the DeepFacture project is to develop an API that automates the verification of flows intended for the DGFIP. The following figure shows the interaction of the API with the outside world as well as its internal architecture. The API receives an XML feed as input, analyses the content of each invoice, checks the compliance of each rule, and returns a JSON report as output, specifying whether the feed is compliant, and if not, the reasons why.
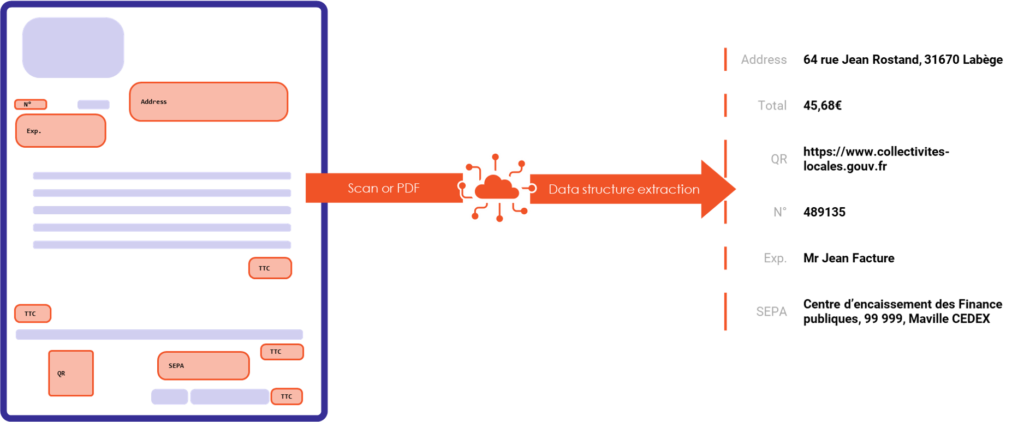
Locating objects and data extraction from a PDF
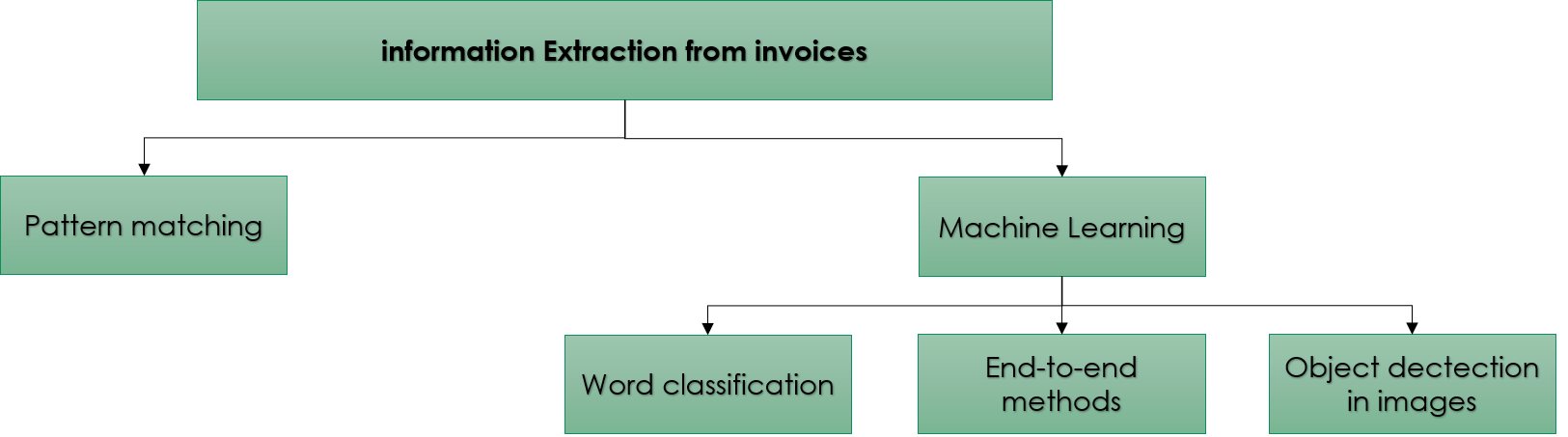
The DeepFacture API must be able to locate the different elements of the invoice (address fields, logo…) and extract the value of each element. In the state of the art, there are two approaches to do this [1] :
Pattern matching: this is an intuitive approach that consists of identifying patterns in documents and using them to extract information. For example, the total amount of an invoice is usually a decimal number to the right of the word “Total”. There are several techniques for pattern matching in the literature [2]-[5]. Patterns can be implemented with a regular expression or generated with manual annotation plus heuristics.
- Advantage: Template comparison works well when documents are homogeneous and structured.
- Disadvantage: the creation and maintenance of templates take time and expertise. Moreover, it does not extend to other document templates.
Machine learning: this approach is based on a model trained from an annotated corpus of documents. Some works consider the task as a classification of words. For each word in the document, it is decided whether or not to extract it. If several values need to be extracted (total, date, etc) the task becomes a multiclass classification. To solve the problem, these works have opted either for feature engineering plus a classical machine learning model such as SVMs [6], or word embeddings plus neural networks [7]-[11]. There are also works that propose an end-to-end approach. In this case, the model considers the document as a whole and does not indicate the location of the information to be extracted but directly returns the value of the information sought [1].
Documents can also be seen as images (in the case of scans, for example). In this case, it becomes interesting to exploit the methods for locating objects in images: YOLO [12], Single Shot MultiBox Detector [13], Fast R-CNN [14], Faster R-CNN [15], Feature Pyramid Networks [16]… Once the object is detected, an OCR is used to extract the text it contains.
- Advantage: the approach is well generalized for many document templates.
- Disadvantage: the need for a large corpus where each word has to be labeled. Manual annotation is an expensive process and therefore not feasible in many cases.
For the DeepFacture project, we have several invoice formats with possible misplaced elements. In addition, DGFIP rules can evaluate at any time. Establishing all possible rules is tedious and unreasonable for a “template-matching” approach. We would like to adopt a solution that takes into account scanned documents and that is generalized to other document formats in order to exploit the pipeline for other future projects. The approach adopted is therefore information extraction with “machine learning”. More specifically, we use deep learning techniques for locating objects in images.
DeepFacture process
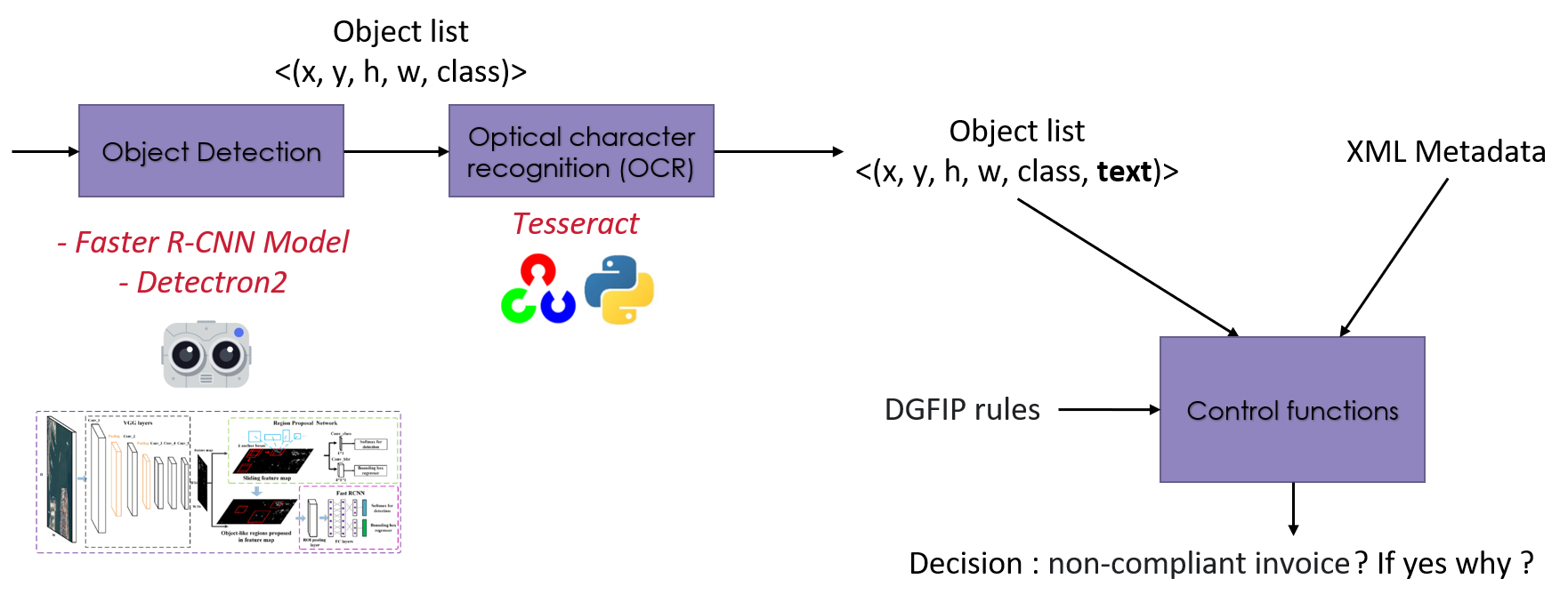
The answer to this question is illustrated in the following figure. We use a Faster R-CNN model (implemented in the Python Detectron2 library) to locate the objects in the invoice. This model returns the coordinates and class of each object. Then we use an OCR function (implemented in the Tesseract library) to extract the textual information from the object. Finally, we use control functions that we have implemented to check if the invoice is good or not. These functions are based on the list of objects (with their coordinates, class, and text), the metadata of the XML flow, and the DGFIP rules to analyze the conformity of the invoice.
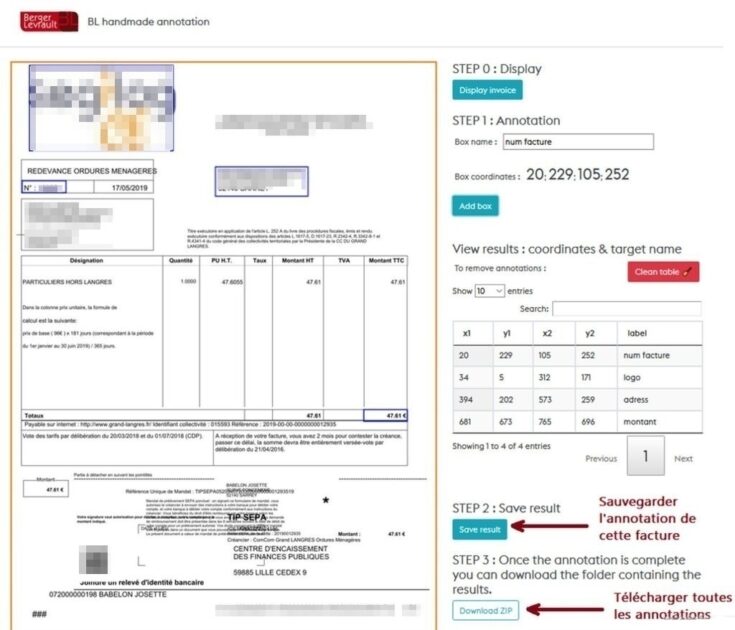
Supervised learning needs annotated data
The approach we have adopted requires annotated data to drive the object location model. We are currently developing a web interface for image annotation. We already have a version that allows you to load an invoice, then visually annotate the objects and finally write the result to a file. The content of this file is used to train the Faster R-CNN model. The following figure in a preview in this interface.
To assess the model quality we rely on “mean Average Precision” [17]. OpenSource code for evaluation is available on the Internet. Then, the preparation of the Test-set: we build a set of annotated invoices as general as possible in terms of Template and types of errors, we take 80% to 85% of the total annotated invoices to train the template, the rest of the invoices to test it.
Our goal: Annotate as less as possible !
Deep learning generally requires a lot of annotated data to converge reliably. In our case we manage to build a model which requires only 20 to 30 anotated invoices to converge with excellent results. There are several way to achieve that goal:
- Generate an artificial corpus: a pre-established address base, randomly generated text or from the web or other source, randomly generated numbers, randomly generated location.
- Use “data augmentation”: take correct and well-structured invoices, then move, resize and modify objects randomly.
- Use a pre-trained model: a first training pass with a large generic corpus. A second training pass with the small specific corpus of invoices.
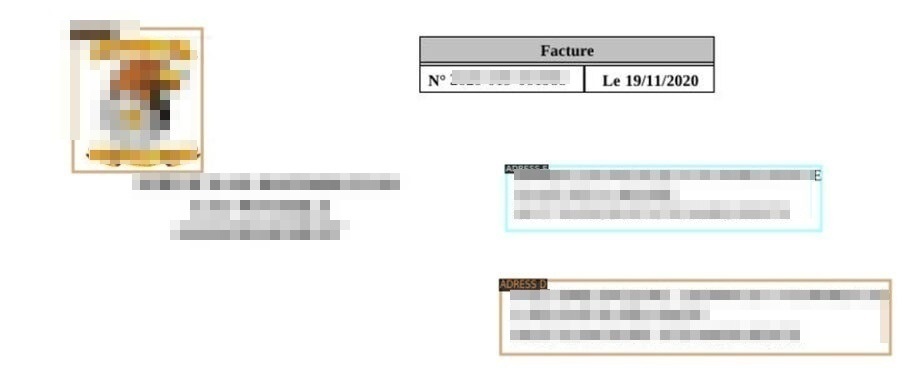
For our first tests, we used a pre-trained Faster-RCNN model (with the Detectron2 library). We made a training pass with a few dozen invoices that we annotated. The results obtained were satisfactory. In the following example, we used the trained template to locate the recipient address, the sender address, and the logo.
Conclusion
In this article, we have presented DeepFacture, a project to meet the needs of our meticulous teams concerning the automation of the control of invoices sent to the DGFIP. The approach adopted to extract information is the use of neural network techniques for the detection of objects in images. We are currently interested in developing a generic web interface that allows us not only to annotate images, but also to parameterize, run training, and re-training the model. Experience has shown that the proposed pipeline can be extended to other case studies. In the future, we will be interested in other uses. For example, the extraction of information from hospital ID cards, etc.
References
[1] R. B. Palm, F. Laws, and O. Winther, “Attend, copy, parse end-to-end information extraction from documents,” in 2019 International Conference on Document Analysis and Recognition (ICDAR), 2019, pp. 329–336.
[2] E. Medvet, A. Bartoli, and G. Davanzo, “A probabilistic approach to printed document understanding,” Int. J. Doc. Anal. Recognit., vol. 14, no. 4, pp. 335–347, 2011.
[3] D. Esser, D. Schuster, K. Muthmann, M. Berger, and A. Schill, “Automatic indexing of scanned documents: a layout-based approach,” in Document recognition and retrieval XIX, 2012, vol. 8297, p. 82970H.
[4] D. Schuster et al., “Intellix–End-User Trained Information Extraction for Document Archiving,” in 2013 12th International Conference on Document Analysis and Recognition, 2013, pp. 101–105.
[5] M. Rusinol, T. Benkhelfallah, and V. Poulain dAndecy, “Field extraction from administrative documents by incremental structural templates,” in 2013 12th International Conference on Document Analysis and Recognition, 2013, pp. 1100–1104.
[6] Y. Li, K. Bontcheva, and H. Cunningham, “SVM based learning system for information extraction,” in International Workshop on Deterministic and Statistical Methods in Machine Learning, 2004, pp. 319–339.
[7] T. Mikolov, I. Sutskever, K. Chen, G. Corrado, and J. Dean, “Distributed representations of words and phrases and their compositionality,” arXiv Prepr. arXiv1310.4546, 2013.
[8] J. Pennington, R. Socher, and C. D. Manning, “Glove: Global vectors for word representation,” in Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), 2014, pp. 1532–1543.
[9] X. Ma and E. Hovy, “End-to-end sequence labeling via bi-directional lstm-cnns-crf,” arXiv Prepr. arXiv1603.01354, 2016.
[10] G. Lample, M. Ballesteros, S. Subramanian, K. Kawakami, and C. Dyer, “Neural architectures for named entity recognition,” arXiv Prepr. arXiv1603.01360, 2016.
[11] C. N. dos Santos and V. Guimaraes, “Boosting named entity recognition with neural character embeddings,” arXiv Prepr. arXiv1505.05008, 2015.
[12] J. Redmon and A. Farhadi, “YOLO9000: better, faster, stronger,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 7263–7271.
[13] W. Liu et al., “Ssd: Single shot multibox detector,” in European conference on computer vision, 2016, pp. 21–37.
[14] R. Girshick, “Fast r-cnn,” in Proceedings of the IEEE international conference on computer vision, 2015, pp. 1440–1448.
[15] S. Ren, K. He, R. Girshick, and J. Sun, “Faster r-cnn: Towards real-time object detection with region proposal networks,” arXiv Prepr. arXiv1506.01497, 2015.
[16] T.-Y. Lin, P. Dollár, R. Girshick, K. He, B. Hariharan, and S. Belongie, “Feature pyramid networks for object detection,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 2117–2125.
[17] R. Padilla, S. L. Netto, and E. A. B. da Silva, “A survey on performance metrics for object-detection algorithms,” in 2020 International Conference on Systems, Signals and Image Processing (IWSSIP), 2020, pp. 237–242.