
Data is a key component of decision making. Today, companies deploy complex processes to automate the collection, storage and processing of large amounts of data. Most of this data is in the form of unstructured documents. Berger-Levrault’s software solutions handle documents of various natures: invoices, forms, etc. Unfortunately, this unstructured representation is difficult to exploit by the machine. It is therefore important to design tools for intelligent document processing (IDP). These tools aim to capture, extract and intelligently process data from various document formats. This is achieved by using image analysis, natural language processing and deep machine learning techniques.
BL-IDP was released in 2019, but here we are talking about BL IDP version 2, so we will talk about what is BL IDP v1, what version 2 to bring.
BL IDP version 1
The project “Intelligent Document Processing”, or IDP, was born within the DRIT (Direction de la Recherche et Innovation Technologiques) of Berger Levrault (BL), it allows to capture, extract and process data from various document formats. It transforms non-usable data into structured data that can be easily manipulated by an automated business process. Without IDP solutions, the process requires human intervention to read documents, extract data and enter it. Intelligent document processing unleashes the full potential of automation.
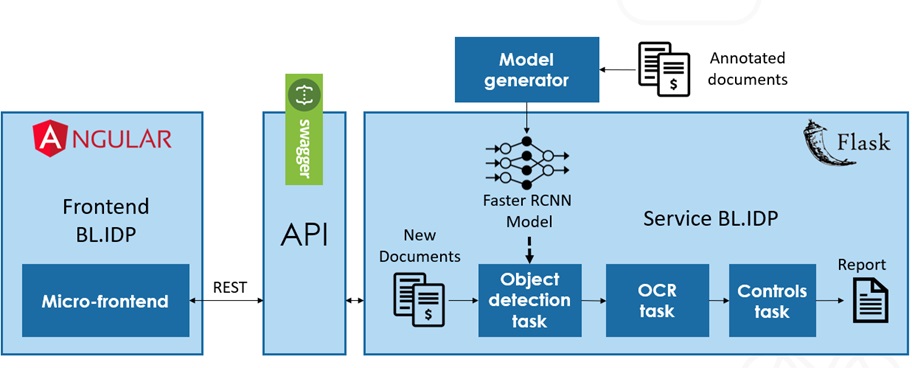
IDP version 1, or ex Deep Facture, is a project for invoices only, at the input we have an image or a PDF of an invoice, and we apply object detection to detect the address of the recipient and the sender, the Logo and the Datamatrix of the invoice, then go through an OCR “Optical Character Recognition” to finish a layer of control of the requirements of the BL invoices.
Here is the global architecture of BL.IDP v1 :
BL IDP version 2
The difference between version 1 and 2 of IDP is the architecture and the use cases and of course the tools used.
For the architecture, the training part of the model in IDP v1 is done locally, then we recover the model (the weights) and we add it manually on the platform to be able to test. And for the annotation part, it is done manually without a dedicated platform for that too.
Here is the proposed architecture for IDP v2:
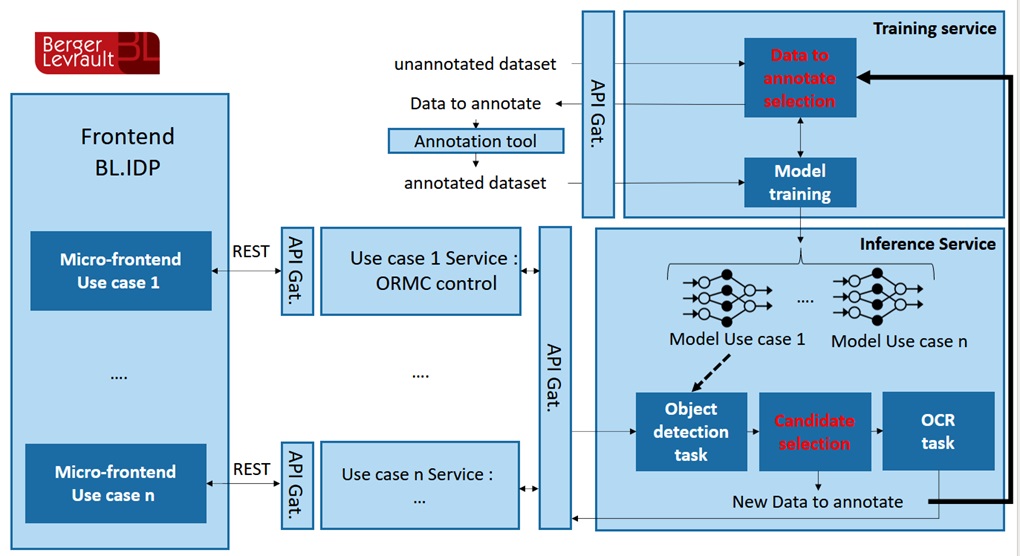
From the architecture we can see that this platform includes several models, several use cases but also a tool for annotation.
The internal architecture of this project is composed of two essential parts, the training service and the inference service, it is quite logical that the result of the training service is the input of the inference service, the training service is the producer of the models, while the inference is the consumer.
Everything starts with a dataset, not annotated, and we want to make a model capable of detecting objects in this dataset, we pass this dataset to the training service, the latter applies the selection of images, then the selected images will be sent to the annotation tool, in this tool we choose the objects to be annotated, we annotate and the training begins.
At the end of the training, the generated model will be stored in a storage server of Amazon, Aws s3, and by Kafka we inform the inference service that the model is on s3 so it must recover it.
For each well specified use case, a model is generated and stored for it, so if the user calls the inference service, and the model associated with the use case is existing, the following steps will happen:
- The model makes a prediction on the image sent;
- We check if this example is good to redo the training with or not, if it is the case, send the image to the training service;
- Apply OCR to the results found.
What also differs from version 2 in its previous version is the active learning that is applied
Active learning
Active learning is a sub-domain of AI, the key assumption of this type of approach is: if the learning algorithm is allowed to choose the data from which it will learn, it will perform better with less annotated data.
Active learning systems attempt to eliminate the lack of annotated data or availability of annotators, by requesting queries in the form of unlabeled instances that must be annotated by an oracle.
There are several different problem scenarios in which the algorithm can query the oracle, the three main scenarios are:
- Membership-based query synthesis,
- Selective sampling based on the flow,
- Active learning based on the pool,
In BL IDP v2, we applied active learning based on the pool.
Active learning based on the pool
For many real-world problems, a huge amount of unlabeled data can be retrieved, and this is what motivates this scenario, we assume that we have a small, labeled dataset and an unannotated data pool, queries are selectively drawn from the pool, and the instances are queried in a greedy manner, based on informativeness metrics used to evaluate all the instances in the pool or a sub-sample of it.
This scenario is used in several areas of machine learning, such as text classification, information extraction, image, video and audio extraction and classification.
Use case Diagram
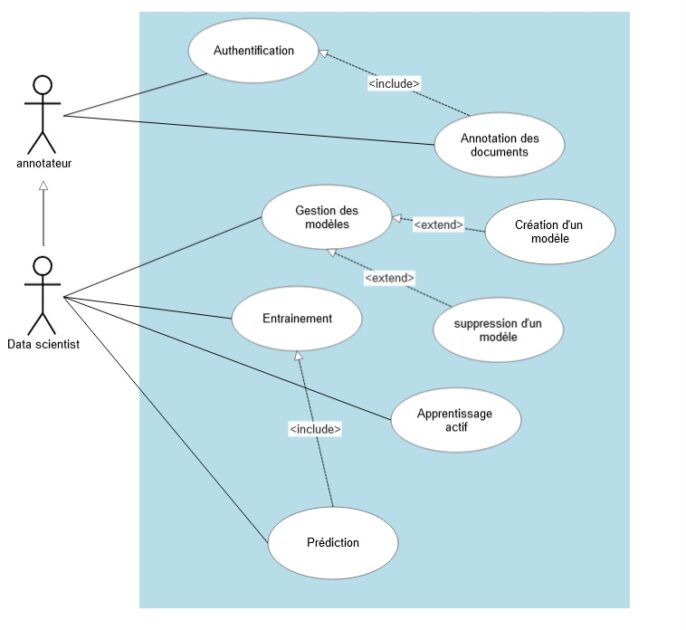
For the diagram above, we notice that in the system we have two actors, annotator and a data scientist, who can be an annotator too, the role of annotator is to annotate the documents that have been assigned to him, as long as the data scientist, to several missions as follows:
- The management of models: which consists in creating models and deleting them with the possibility of modifying the number of iterations for the training
- Launch the training of the models
- Adjust the accuracy with active learning
- Make prediction on new documents for a visual test
Conclusion
The IDP v2 project has taken the right path, it has been implemented on three use cases, with promising performances. The next step is to compare the solution with the existing one, refine the accuracy of the results and generalize the method for other types of documents.
By Toufik Kerdjou



