Find the first migration approach in these articles: article 1 & article 2
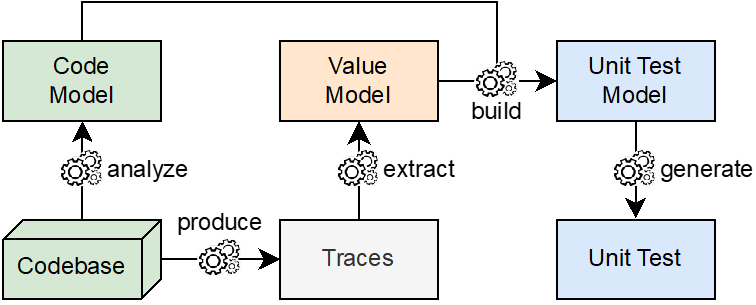
In this section, we introduce a broad overview of the different phases which constitute our global MDE-based migration workflow. In short, our workflow (see Figure 1) encompasses 4 important steps :
- Extracting a model from the source application.
- Identifying the application’s candidate MSA and incorporating it into an intermediary pivot model.
- Transforming the pivot model to obtain the target MSA model, consisting of multiple microservices and their associated entities.
- Generating and packaging the target source code from the target MSA model to make it deployable.
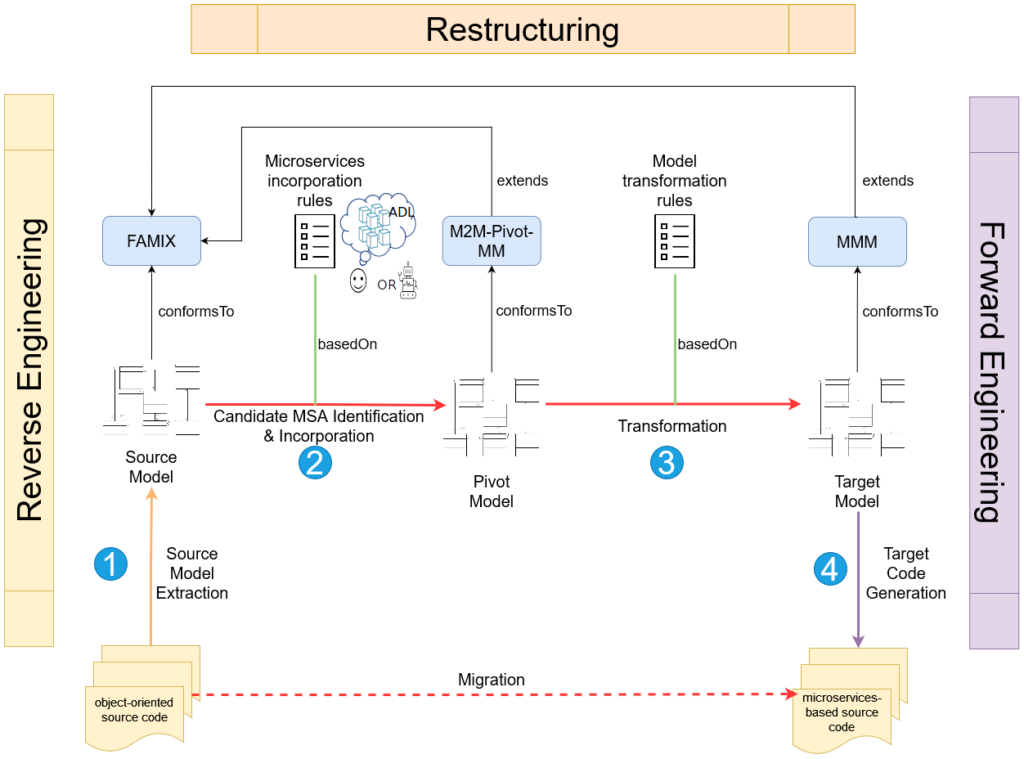
This workflow is mainly PIM-oriented instead of being Platform-Specific Model (PSM)-oriented, as is the case with its ad-hoc counterparts. Particularly, each model intervening in the process is described by a corresponding meta-model.
Furthermore, transitioning from one source model to another target model requires a set of model transformation rules, mapping one/many elements in the source to one/many elements in the target. These transformations occur at a domain-level, and are thus less constrained by their applications’ technologies and platforms, rendering them consequently more reusable for object-oriented applications in general.
Moreover, our contributions span over the candidate MSA incorporation phase, the model transformation phase, and the model exportation phase of the workflow.
Model extraction
The first phase in the MDE-based migration process consists of parsing the project’s source code and extracting its model from its corresponding AST (Abstract Syntax Tree). Depending on the project’s source code, a corresponding parser can be used to extract its AST.
Candidate MSA identification & incorporation
The second phase consists of extracting the microservice-oriented architecture from the source model and incoperating it into a pivot model (Figure 2). Concretely, we divide this phase into two steps :
- The identification of a candidate MSA,
- Its incorporation into a pivot model.
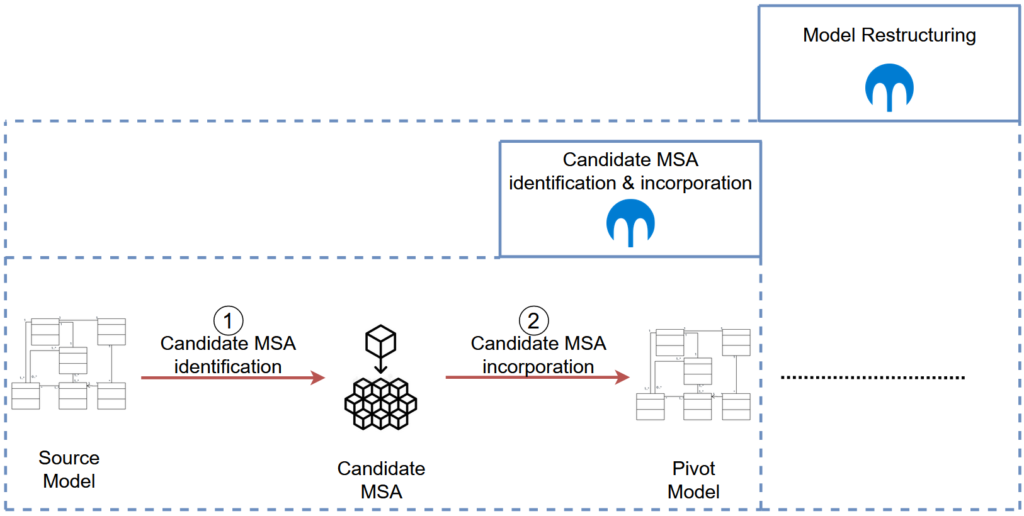
Candidate MSA Identification
Microservices identification is a software engineering task occurring at the architectural level of a monolith and aims to apply reverse engineering techniques on its software artifacts to identify the corresponding microservice candidates and their description within an MSA. The identification process is based on a set of patterns/strategies, constraints, and quality attributes shaping and guiding its course.
In the context of this project, we focus on the identification of microservices based on the source code of an object-oriented monolithic application. One common way to achieve this is a graph-based approach that employs graph clustering and visualization techniques to identify the candidate microservices from the monolith’s source code. In particular, we apply the approach proposed in the 1st part article which extracts the layered architecture before partitioning its artifacts using a clustering algorithm to represent the candidate MSA as a set of LayerEntity clusters.
The initial step of reverse-engineering the layered architecture serves an important task towards the overall migration process. Furthermore, in the model-driven transformation it also serves the function of structuring the internal architecture of each identified microservice. Once the candidate MSA is obtained from the identification step, it will be forwarded to the software architect for validation. Accordingly, the architect can also interact with the candidate MSA to modify it. Otherwise, the identification process ends and the candidate MSA can be incorporated into a new model. Furthermore, to accompany the iterative process underlying our migration’s implementation, we added a manual identification process to allow for expert honing/refinement of the microservices architecture
Candidate MSA Incorporation
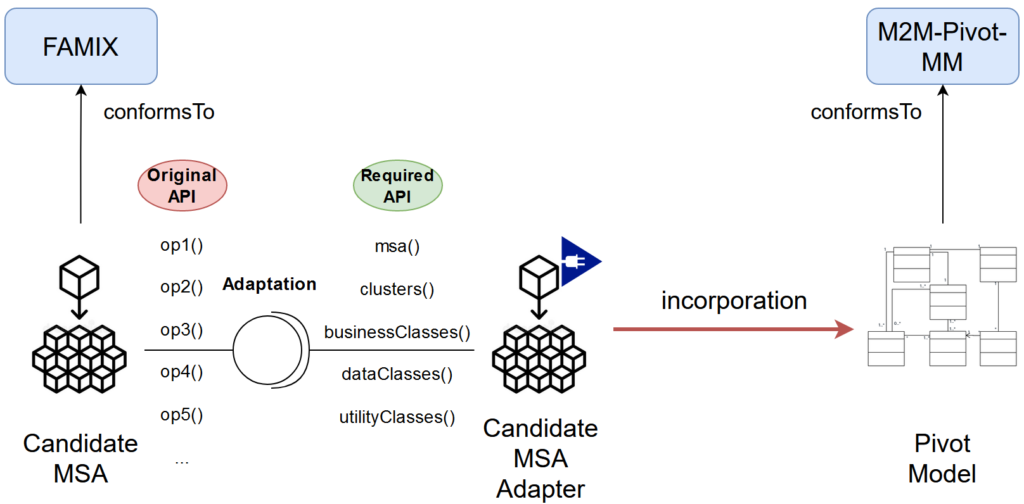
The second step consists of incorporating the candidate MSA yielded by the MSA, identification process into an intermediary pivot meta-model, namely the Monolithic-to-Microservices Pivot Meta-model (M2M-Pivot-MM).
Indeed, the MSA identification process only provides an incomplete framework describing the general outlines of the target MSA model in the form of a candidate MSA. Hence, to further complete this process, we need to describe the candidate MSA by a properly dedicated meta-model, followed by the application of the necessary transformations on its model to actually reflect the identified MSA description.
Moreover, our workflow deals with candidate MSAs extracted through identification processes that use graph-based clustering algorithms. This yields MSA descriptions with a specific interface that exposes the candidate MSAs’ class clusters and their associated entities. As a result, our incorporation rules are conceptually dependent on this interface.
Nevertheless, we aim to make our approach as reusable and generic as possible to reduce migration efforts. In other words, we wish to make these incorporation rules independent of the MSA description’s interface. This proves necessary to implement them once and reuse them across different workflows employing different identification processes that yield MSA descriptions with different interfaces.
Consequently, the incorporation mechanism employs the Adapter design pattern. Particularly, a candidate MSA adapter maps the API of a candidate MSA to the API expected by the pivot meta-model (see Figure 3). In other words, the candidate MSA adapter enforces any identified candidate MSA to implement its expected interface, namely to provide means of access to the MSA, its candidate microservices, their business, data, utility classes, and their provided and required interfaces.
Once the candidate MSA implements the adapter’s required interface, the adapter maps every entity retrieved from the candidate MSA to its corresponding entity in the pivot model.
Model Transformation
The third phase in the MDE-based migration process is the model transformation (see Figure 4). It consists of transforming the pivot model, described by the M2M-Pivot- MM, to obtain the target model, described by the Microservices Architecture Model-Driven Migration Meta-Model (MMM).
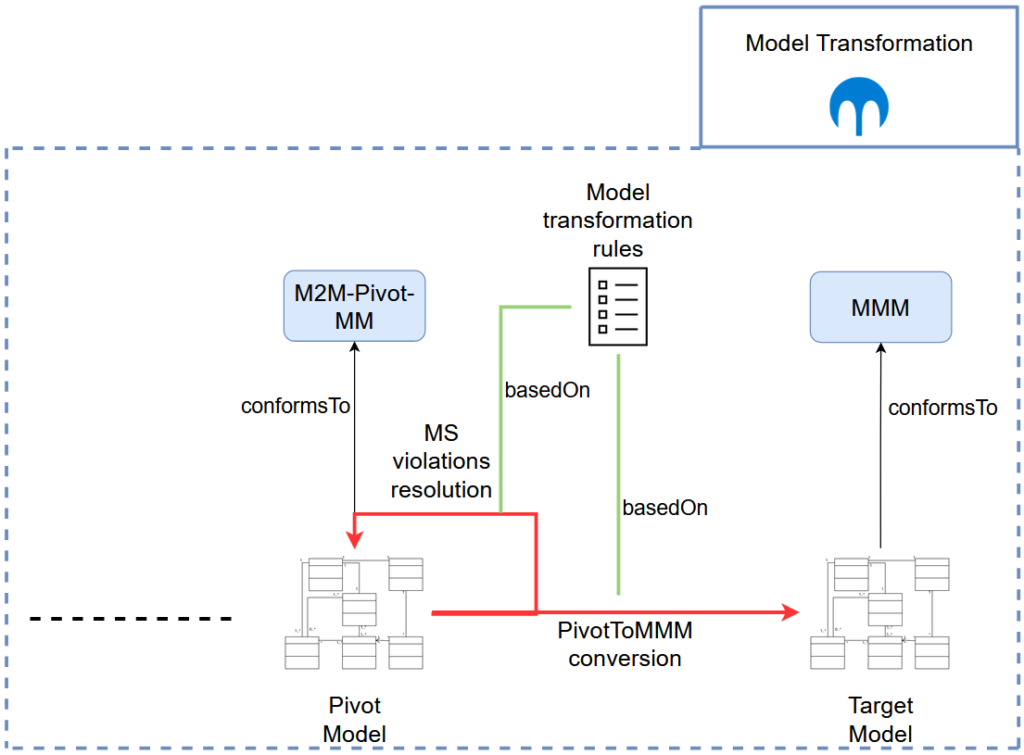
Now that we have recovered the architecture and identified the MSA inside it, we can materialize it through this transformation step, where all recovered cluster will be deployed in their own microservice.
Yet edge classes have dependencies with classes belonging to another cluster. These dependencies between classes of different microservices are called microservice encapsulation violations. All violations must be handled by refactoring methods that convert OO-type dependencies into MS-type before a microservice can be encapsulated then generated.
To encapsulate microservices the sharing mechanism between microservice candidates must be resolved. The characteristic of a MSA to use message-oriented communication between different microservices (method invocations between classes of different clusters) must be restricted to a set of provided and required interfaces that define the web services it provides and those it consumes. In addition, inter-process communications (IPC) calls between microservices are limited to value-based communication (primitives and serialized data). These explicit OO dependencies, implicit dependencies between clusters must be addressed to fully encapsulate the microservice candidates. Inheritance mechanism and exception handling are the two main implicit OO mechanisms that must be addressed. Particularly, an inheritance violation is defined as a class that has a super-class that belongs to another clusters. The exception handling violation is defined as a class throwing an exception that is caught by a class belonging to another cluster.
Both of these OO mechanisms must be addressed and transformed into MS-type dependencies.
Lastly, MSA generated after the transformation step must adhere to 2 additional operational characteristics: (1) microservices must run on their own
process and (2) they must be automatically deployable. To conform to these operational characteristics, each microservice must define an independent project that must be configured for Cloud deployment. Both of these characteristics must be addressed during the generation of the source code for each microservice. (Find more about encapsulation violation in this article)
In particular, we distinguish between two different types of model transformations, each of which accomplishes a well defined objective in the course of the migration process: (1) the microservice encapsulation violations resolution and (2) the Pivot2MMM conversion.
To understand the reasons behind the distinction between these two types of model transformations, we have to start by examining their input, namely the pivot model. As previously mentioned, the pivot model is obtained following the candidate MSA identification and incorporation phases of the migration process. In particular, the pivot model incorporates the identified candidate MSA, consisting of all candidate microservices, such that each candidate microservice is represented as a cluster of classes obtained from the original source model.
The act of creating microservice candidates from a monolith’s set of classes is defined as microservice encapsulation. In this context, each microservice is its own application.
Therefore, classes residing in one microservice should have their access restricted from classes belonging to other microservices. In other words, a microservice encapsulates its own set of classes. When a class encapsulated by one microservice depends on a class encapsulated by another microservice, a microservice encapsulation violation occurs. These class-level dependencies include method invocations, class instantiations, public attribute accesses, class inheritances, class implementations of interfaces, among others.
As such, we observe that class-level dependencies still exist between classes belonging to different microservice candidates in the pivot model (see Figure 4), despite the microservices identification step. Indeed, the microservices identification task cannot completely eliminate said dependencies, but at best may try to minimize them instead.
Nonetheless, a properly crafted MSA should be devoid of any such violations. Thus, prior to the pivot model’s transformation into the target model, we need to identify these violations in the pivot model and duly resolve them. Consequently, we decompose our model transformation phase into two steps accomplishing the following objectives respectively:
- Identifying and resolving the microservice encapsulation violations in the pivot model
- Converting the violation-free pivot model into the target model.
Model Exportation
The fourth and last phase in the MDE-based migration process consists of generating, packaging, and deploying the project’s target code based on its corresponding target MSA model. Depending on the target MSA model, a model exporter can be configured by an expert to choose how the desired artefacts will be generated. In a nutshell, configurations include choosing the target framework technologies, project builders, dependency managers, and other technologies relevant for microservices, such as the containerisation technology, circuit breakers, service discovery, API clients, or communication protocols.
For example, if the target model is to be exported as a set of Spring Boot2 projects, then the model exporter must generate a Spring Boot project for each microservice in the target MSA model. Furthermore, it must ensure that the packages of the newly generated projects properly import the necessary Spring Boot dependencies. This is done using the project builders and dependency managers (e.g., Maven, Gradle, etc.) used with the source monolith. In addition, the target model exporter must generate a container image for each microservice in the target MSA model, describing the configuration details necessary for the creation and deployment of its corresponding container. For example, if the model exporter is configured to deploy each microservice of the target MSA model in a Docker3 container, then a corresponding Dockerfile must be created to describe its Docker image.
Finally, an MSA-level configuration file can be generated to describe the MSA-level configuration details of its microservices. In the case of Docker containerization, for instance, a docker-compose file can be generated to control, configure, and deploy each microservice through its Docker image.
To summarize
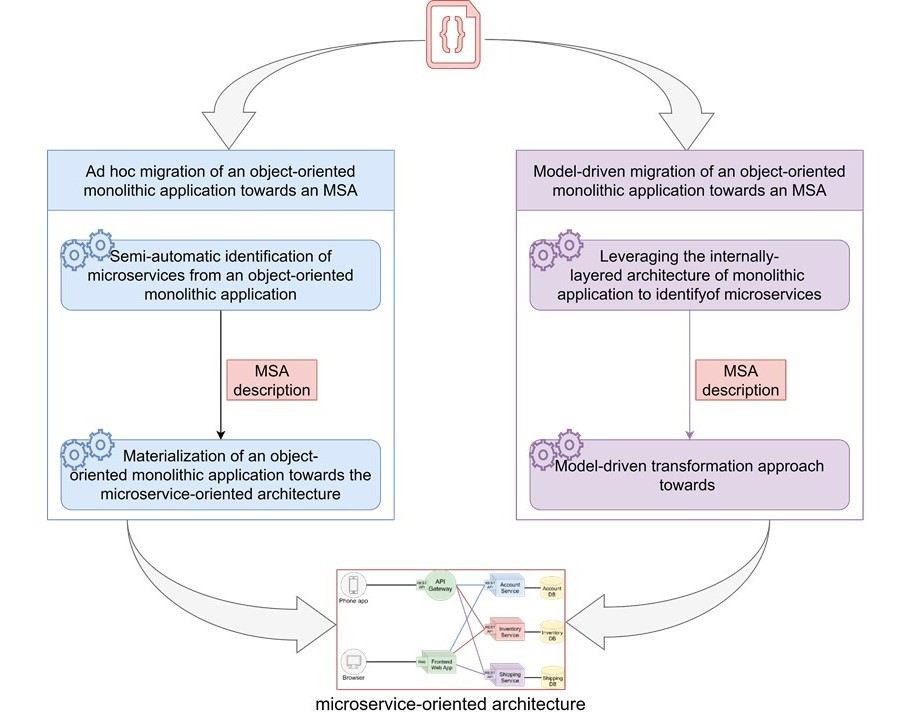
In this project, we present two different approaches to migrating a monolithic architecture toward an MSA architecture.
The first method consists in transforming the source code to match it to the architecture (represented in blue in figure 6), while in the second method we go through a model to represent the target architecture and then generate the code that corresponds to it (represented in purple in figure 6).
References
[1] E. Barry, C. Kemerer, and S. Slaughter, “Toward a detailed classification scheme for software maintenance activities,” AMCIS 1999 Proceedings, p. 251, 01 1999.
[2] J. Bisbal, D. Lawless, B. Wu, and J. Grimson, “Legacy information system migration: A brief review of problems, solutions and research issues,” IEEE software, vol. 16, no. 5, pp. 103–111, 06 1999.
[3] I. Sommerville, Software Engineering, 9th ed. USA: Addison-Wesley Publishing Company, 2010.
[4] J. Bisbal, D. Lawless, B. Wu, and J. Grimson, “Legacy information systems: Issues and directions,” Software, IEEE, vol. 16, pp. 103 – 111, 10 1999.
[5] C. Wagner, Model-Driven Software Migration: A Methodology: Reengineering, Recovery and Modernization of Legacy Systems. Springer Science & Business
Media, 03 2014.
[6] J. Lewis and M. Fowler, “Microservices: A definition of this new architectural term,” https://martinfowler.com/articles/microservices.html, 2014, accessed: 2020-06-20.
[7] X. J. Hong, H. S. Yang, and Y. H. Kim, “Performance analysis of restful api and rabbitmq for microservice web application,” in 2018 International Conference on Information and Communication Technology Convergence (ICTC). IEEE, 10 2018, pp. 257–259.
[8] C. Richardson, Microservices Patterns: With Examples in Java. Manning Publications, 2018. [Online]. Available: https://books.google.de/books?id=UeK1swEACAAJ
[9] S. Newman, Building Microservices: Designing Fine- Grained Systems. ” O’Reilly Media, Inc.”, 2015.
[10] P. Zaragoza, A.-D. Seriai, A. Seriai, H.-L. Bouziane, A. Shatnawi, and M. Derras, “Refactoring monolithic object-oriented source code to materialize microserviceoriented architecture,” in ICSOFT, 2021.
[11] F. Fleurey, E. Breton, B. Baudry, A. Nicolas, and J.-M. J´ez´equel, “Model-driven engineering for software migration in a large industrial context,” in Model Driven Engineering Languages and Systems, G. Engels, B. Opdyke, D. C. Schmidt, and F. Weil, Eds. Berlin, Heidelberg: Springer Berlin Heidelberg, 2007, pp. 482–497.
[12] D. C. Schmidt, “Guest editor’s introduction: Modeldriven engineering,” Computer, vol. 39, no. 2, p. 25–31, Feb. 2006. [Online]. Available: https://doi.org/10.1109/ MC.2006.58
[13] M. Waseem, P. Liang, G. M´arquez, M. Shahin, A. A. Khan, and A. Ahmad, “A decision model for selecting patterns and strategies to decompose applications into microservices,” 2021.
[14] A. Selmadji, A.-D. Seriai, H. L. Bouziane, R. Oumarou Mahamane, P. Zaragoza, and C. Dony, “From monolithic architecture style to microservice
one based on a semi-automatic approach,” in 2020 IEEE International Conference on Software Architecture (ICSA), 2020, pp. 157–168.
[15] S. Demeyer, S. Tichelaar, and S. Ducasse, “Famix 2.1 – the famoos information exchange model,” University of Bern, Tech. Rep., 01 2001.
[16] S. Demeyer, S. Ducasse, and E. Tichelaar, “Why famix and not uml? uml shortcomings for coping with roundtrip engineering,” in In Proceedings of¡¡ UML’99¿¿, Fort Collins. Citeseer, 09 1999.
[17] S. Tichelaar, S. Ducasse, and S. Demeyer, “Famix and xmi,” in Proceedings Seventh Working Conference on Reverse Engineering. IEEE, 02 2000, pp. 296 – 298.
[18] S. Ducasse, M. Lanza, and E. Tichelaar, “Moose: an extensible language-independent environment for reengineering object-oriented systems,” in Proceedings of the Second International Symposium on Constructing Software Engineering Tools (CoSET 2000), vol. 4. Citeseer, 04 2000.
[19] S. Ducasse, N. Anquetil, M. Bhatti, A. Hora, J. Laval, and T. Girba, “Mse and famix 3.0: an interexchange format and source code model
family,” Laboratoire d’Informatique Fondamentale de Lille, Research Report, 05 2012. [Online]. Available: https://hal.inria.fr/hal-00646884
[20] F. Rademacher, J. Sorgalla, S. Sachweh, and A. Z¨undorf, “Towards a viewpoint-specific metamodel for modeldriven development of microservice architecture,” 04 2018.
[21] A. Levcovitz, R. Terra, and M. T. Valente, “Towards a Technique for Extracting Microservices from Monolithic Enterprise Systems,” CoRR, vol. abs/1605.0, 2016. [Online]. Available: http://arxiv.org/abs/1605.03175
[22] R. Chen, S. Li, and Z. Li, “From Monolith to Microservices: A Dataflow-Driven Approach,” Proceedings Asia-Pacific Software Engineering Conference, APSEC, pp. 466–475, 2018.
[23] M. Gysel, L. K¨olbener, W. Giersche, and O. Zimmermann, “Service cutter: A systematic approach to service decomposition,” in European Conference on Service-Oriented and Cloud Computing, 09 2016, pp. 185–200.
[24] G. Mazlami, J. Cito, and P. Leitner, “Extraction of Microservices from Monolithic Software Architectures,” in 2017 IEEE ICWS. IEEE, jun 2017, pp. 524–531.
[Online]. Available: http://ieeexplore.ieee.org/document/8029803/
[25] C. Pahl and P. Jamshidi, “Microservices: A systematic mapping study,” in Proceedings of the 6th International Conference on Cloud Computing and Services Science Volume 1 and 2, ser. CLOSER 2016. Setubal, PRT: SCITEPRESS – Science and Technology Publications, Lda, 2016, p. 137–146. [Online]. Available: https: //doi.org/10.5220/0005785501370146
[26] Z. Al-Shara, “Migrating Object Oriented Applications into Component-Based ones,” Theses, Université Montpellier, Nov. 2016. [Online]. Available: https:
//tel.archives-ouvertes.fr/tel-01816975
[27] A. Bucchiarone, K. Soysal, and C. Guidi, “A modeldriven approach towards automatic migration to microservices,” in Software Engineering Aspects of Continuous Development and New Paradigms of Software Production and Deployment. Springer International Publishing, 2020, pp. 15–36.