
To improve Berger-Levrault network, we work in collaboration with the sale department to collect the last news about DGS (Director General of Services) in France. The DGS is directly linked to the elected representative and insure the general coordination of services to implement municipality’s projects. This strategic position embodies the management of a regional government.
When a DGS changes, the services contracts of the community are renewed or changed. This is a great occasion for our sales forces to contact the new representative, introduce Berger-Levrault and let them know how we can support them in their daily work with our large product offer. Though, as there are hundreds of DGS in France, it’s hard to be aware of all the changes in regional governments. To help the sale force department we worked on a two steps approach to automatically follow the DGS flow in France and know:
- when a new election happens,
- the municipality than the elected representative come from,
- in which municipality he has been elected.
From these information, our sales representatives can contact the new DGS.
Our approach is composed of a first step to collect the data we are searching on the web and a second step to structured these data using Natural Language Processing (NLP) methods.
Collecting data from the web
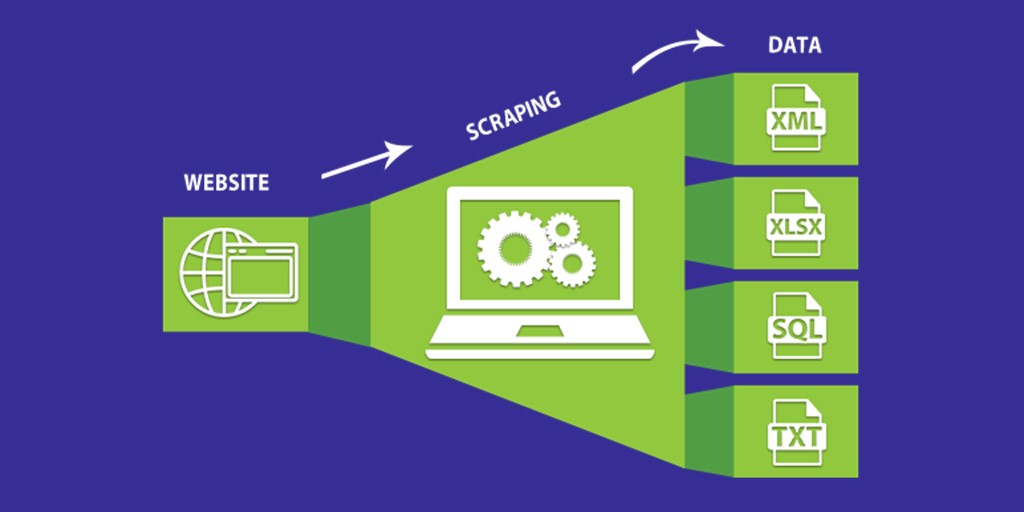
To collect the information we are looking for on the web, we use the web scraping method. This method consists in extracting content from a website using a computer program. It principle is first to specify to the program the way to follow to collect the information we are searching, then choosing a frequency to automatically collect it at a given time.
The program we use is called Scrapcoon 🦝, it is a small raccoon robot allowing to suck data up from the searches engines Qwant and Ecosia with 400 requests a day. Given that all website are not build in the same way and evolve quickly, using search engines instead of specific website as scraping source allows us to build a generic sustainable approach because even if searches engines evolves, their structures stay similar.
To not be blocked in our request process by anti-scrapper tools, the computer program does random request sometimes, introduces break time and the IP address changes every time the Virtual Machine restart.
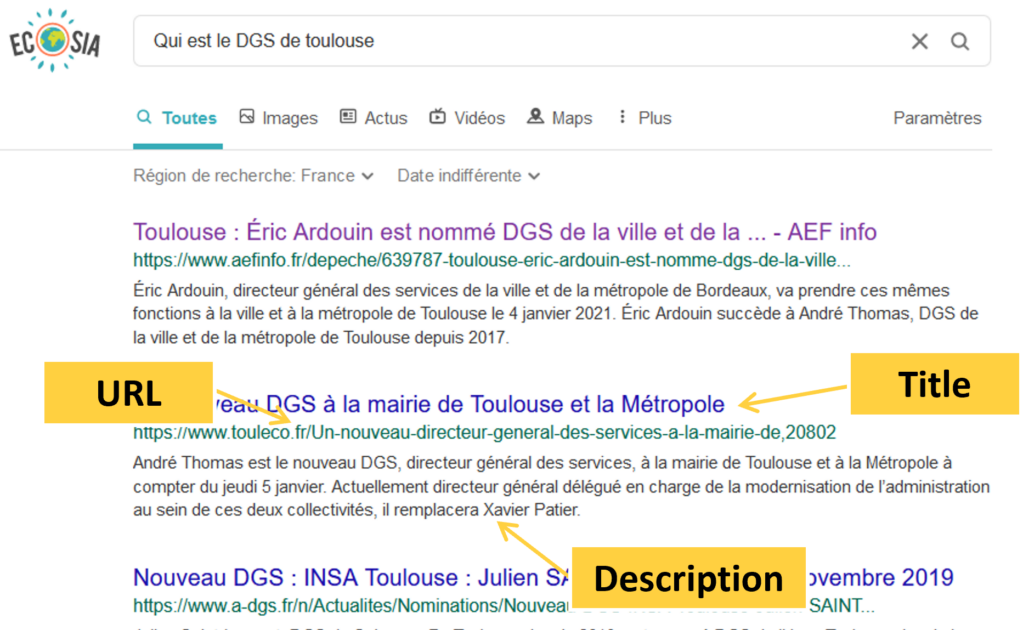
Find below an example of web data scraped.
{'title': 'Saint-Cyprien. Didier Rodière, nouveau DGS en mairie',
'url': 'https://www.leprogres.fr/societe/2022/06/27/didier-rodiere-nouveau-dgs-enmairie',
'description': 'Didier Rodière. Photo Progrès /Éliane BAYON. Didier Rodière a pris
son poste de directeur général des services (DGS) en mairie de Saint-Cyprien le 13
juin. Il remplace Émilie Perrin, partie ...',
'position': 7,
'localization': 'Ambérieu-en-Bugey',
'date_scraping': '2022-06-29 13:55:54',
'source': 'ecosia'}As you can see, we collect the title of the page, the url the information come from, the meta description of the page, the localization, the day the information have been collected and the source it comes from.
Extracting informations using NLP methods
The information collected through our method are unstructured. To make them easily usable we’ll process Natural Language Processing (NLP) methods such as semantic analysis and logic rules. Finally, we use a Question-Answering (QA) model based on CamemBERT and trained on three French datasets made available by the government organization Etalab, specialized in Artificial Intelligence.
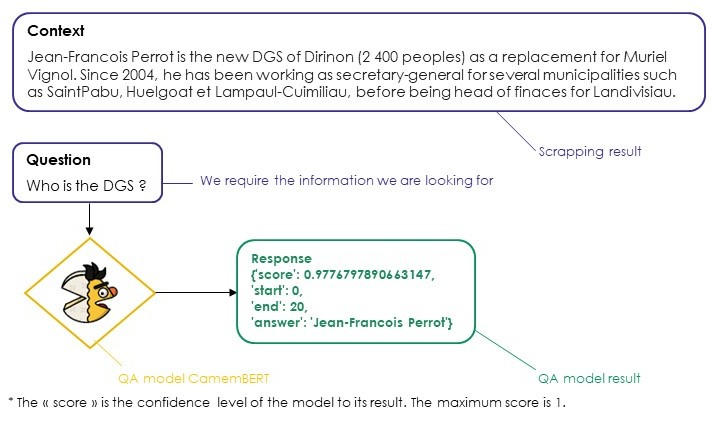
Finally, with the collected information it automatically edits a daily reports of all the changes observed. The added value of our approach is that it is build in a declarative way, which means we do not tell where to search but only what we are looking for. It also means that if we want to find other information like the head of research of private companies for instance, we only have to change the question and we do not have to build a new model.



