Company data is a key part of decision making, but unfortunately, much of this data is in an unstructured format: PDF documents, JPG scans, emails, etc. This unstructured representation is difficult to exploit by the machine, which complicates the automation of business processes. Intelligent Document Processing (IDP) captures, extracts, and processes data from a variety of document formats. It transforms non-exploitable data into structured data easily manipulated by an automated business process. Without IDP solutions, the process will require human intervention to read documents, extract data and enter them. Intelligent document processing unlocks the full potential of automation. To fulfill its role, an IDP solution uses artificial intelligence tools, such as image analysis, natural language processing [1-6], and deep machine learning [7-10]. These tools have been very successful in recent years, thanks to the large amount of data generated globally, the availability of on-demand computing capacity with reasonable costs, and the methods and theoretical models provided by researchers in the field.
Document processing is at the heart of the Berger-Levrault business sectors. We can cite as examples: the flow control embedding PDFs before they are sent to DGFIP, the extraction of information from identity cards, the digitization of paper forms, etc. Recently, within the DRIT, we have developed a service for the automatic control of invoice flows. Berger-Levrault’s products generate invoice flows that are sent to the DGFIP in XML format. Regulations impose a certain number of rules concerning the form and content of these flows, as well as the graphic charter of the invoices. A flow that does not comply is systematically rejected by the DGFIP. Indeed, non-compliance can have harmful consequences for thousands of people (see the detailed article here).
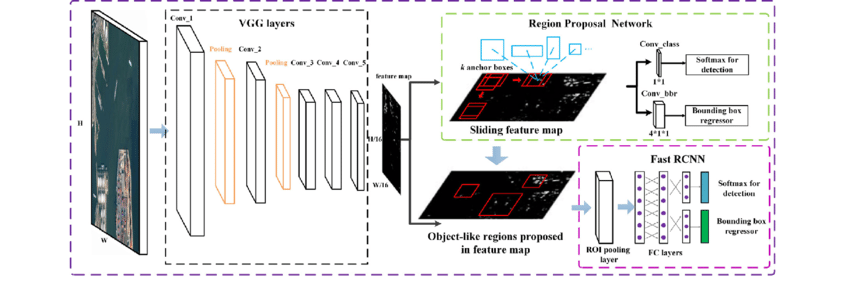
The service embeds a Faster R-CNN-type deep learning model that captures relevant elements from invoices, including sender’s address, recipient address, data matrix, and logo. This model is trained with a very small number of labeled documents (a few dozen invoices), and despite its complexity, it can be run quickly on a machine equipped with a GPU (less than 10 minutes for a flow made up of 260 invoices).
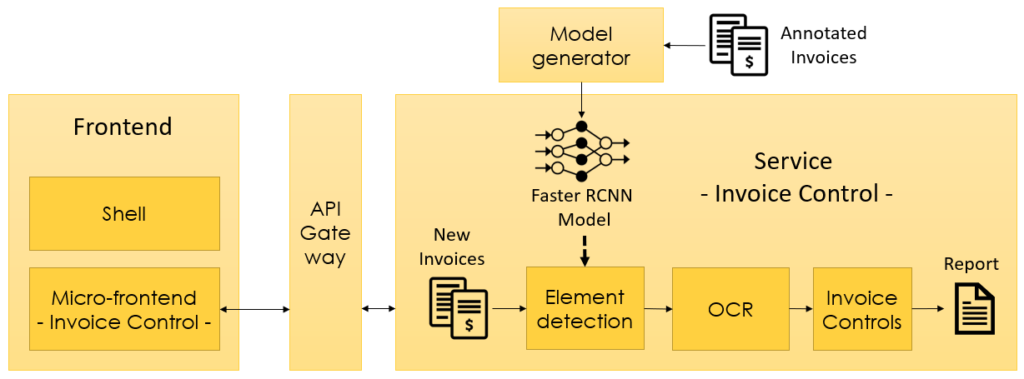
The service is exposed through a REST API. We then developed a UI in Angular with a micro-frontend architecture, which is based on BL.Identity. The “invoice control” service, the REST API and the “invoice control” micro-frontend are the first use case of BL.IDP. The following diagram shows the global architecture:
The following video shows a demonstration of BL.IDP. The user will load an invoice in PDF format. Once the document is loaded, BL.IDP will in the background:
- Transform the PDF into an image,
- Capture the different elements of each invoice (sender’s address, Datamatrix, and logo) with the Faster-RCNN model,
- Extract the text via OCR,
When the report is available, the UI allows you to view it. We can see an image with the elements captured by the model and the extracted data.
We are currently interested in evaluating the effort required to exploit an element localization model for other use cases. We recall that the model is trained on a set of annotated data. We seek to determine the level of sensitivity of the model to variation in the structure of documents. For example, a model trained on invoices with annotation on recipient addresses, will it be efficient to locate addresses in ID cards? What is the sensitivity metric to use? If the model is not performing well enough, should it be retrained from scratch with several sample ID cards? Should we keep the current model and then do some fine-tuning with some sample ID cards? Is it feasible to set up a generic and automated platform for generating models for intelligent document processing with the least amount of manual and repetitive adjustments by a data scientist?
References
[1] Y. Li, K. Bontcheva, and H. Cunningham, “SVM based learning system for information extraction,” in International Workshop on Deterministic and Statistical Methods in Machine Learning, 2004, pp. 319–339.
[2] T. Mikolov, I. Sutskever, K. Chen, G. Corrado, and J. Dean, “Distributed representations of words and phrases and their compositionality,” arXiv Prepr. arXiv1310.4546, 2013.
[3] J. Pennington, R. Socher, and C. D. Manning, “Glove: Global vectors for word representation,” in Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), 2014, pp. 1532–1543.
[4] X. Ma and E. Hovy, “End-to-end sequence labeling via bi-directional lstm-cnns-crf,” arXiv Prepr. arXiv1603.01354, 2016.
[5] G. Lample, M. Ballesteros, S. Subramanian, K. Kawakami, and C. Dyer, “Neural architectures for named entity recognition,” arXiv Prepr. arXiv1603.01360, 2016.
[6] C. N. dos Santos and V. Guimaraes, “Boosting named entity recognition with neural character embeddings,” arXiv Prepr. arXiv1505.05008, 2015.
[7] W. Liu et al., “Ssd: Single shot multibox detector,” in European conference on computer vision, 2016, pp. 21–37.
[8] R. Girshick, “Fast r-cnn,” in Proceedings of the IEEE international conference on computer vision, 2015, pp. 1440–1448.
[9] S. Ren, K. He, R. Girshick, and J. Sun, “Faster r-cnn: Towards real-time object detection with region proposal networks,” arXiv Prepr. arXiv1506.01497, 2015.
[10] T.-Y. Lin, P. Dollár, R. Girshick, K. He, B. Hariharan, and S. Belongie, “Feature pyramid networks for object detection,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 2117–2125.
[11] Z. Deng, H. Sun, S. Zhou, J. Zhao, L. Lei, and H. Zou, “Multi-scale object detection in remote sensing imagery with convolutional neural networks,”. ISPRS journal of photogrammetry and remote sensing, 145, 2018, 3-22.