Encuentre el primer enfoque de migración en estos artículos: artículo 1 & artículo 2
En esta sección, presentamos una visión general de las diferentes fases que constituyen nuestro flujo de trabajo de migración global basado en el MDE. En resumen, nuestro flujo de trabajo (véase la figura 1) abarca 4 pasos importantes :
- Extraer un modelo de la aplicación de origen.
- Identificar el MSA candidato de la aplicación e incorporarlo a un modelo de pivote intermedio.
- Transformar el modelo pivote para obtener el modelo MSA objetivo, compuesto por múltiples microservicios y sus entidades asociadas.
- Generar y empaquetar el código fuente de destino a partir del modelo MSA de destino para hacerlo desplegable.
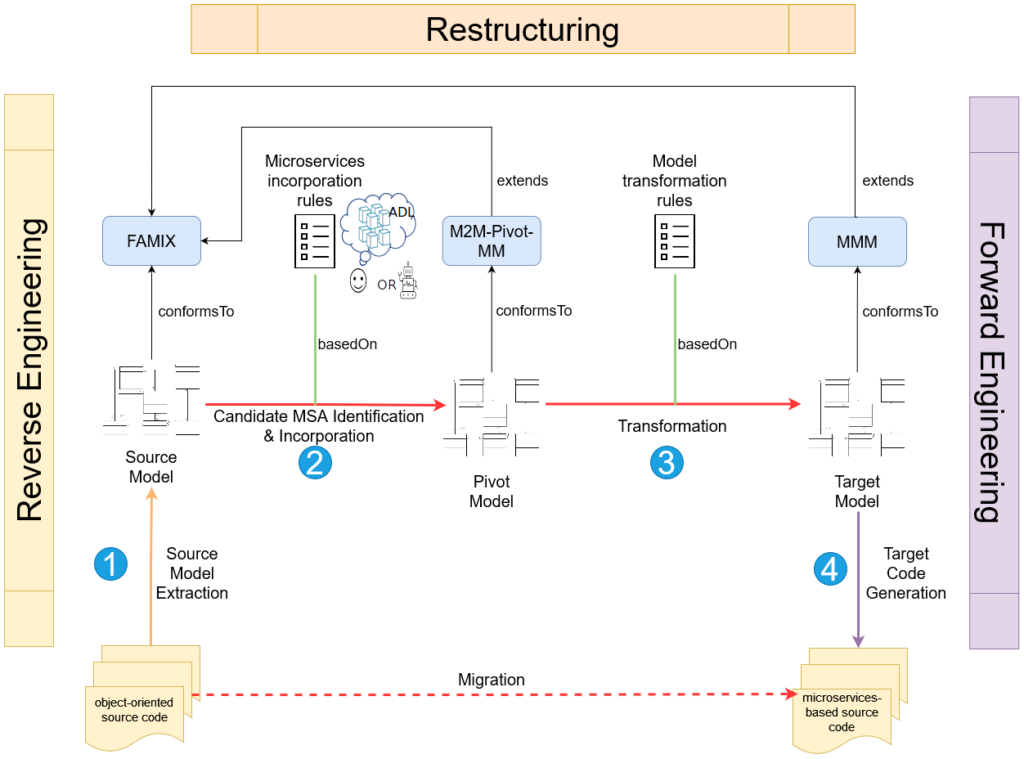
Este flujo de trabajo está orientado principalmente al PIM en lugar de estar orientado al Modelo Específico de Plataforma (PSM), como es el caso de sus homólogos ad-hoc. En particular, cada modelo que interviene en el proceso se describe mediante un metamodelo correspondiente.
Además, la transición de un modelo de origen a otro modelo de destino requiere un conjunto de reglas de transformación del modelo, que mapean uno/muchos elementos en el origen a uno/muchos elementos en el destino. Estas transformaciones se producen a nivel de dominio, por lo que están menos limitadas por las tecnologías y plataformas de sus aplicaciones, lo que las hace más reutilizables para las aplicaciones orientadas a objetos en general.
Además, nuestras contribuciones abarcan la fase de incorporación del candidato a MSA, la fase de transformación del modelo y la fase de exportación del modelo del flujo de trabajo.
Extracción de modelos
La primera fase del proceso de migración basado en MDE consiste en analizar el código fuente del proyecto y extraer su modelo de su correspondiente AST (árbol de sintaxis abstracta). Dependiendo del código fuente del proyecto, se puede utilizar un analizador correspondiente para extraer su AST.
Identificación e incorporación de la MSA candidata
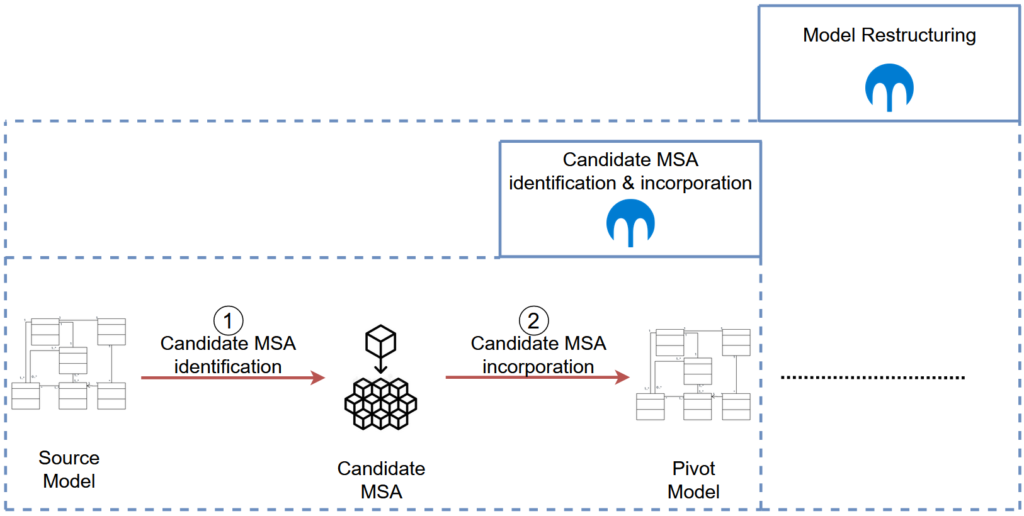
La segunda fase consiste en extraer la arquitectura orientada a los microservicios del modelo fuente e incoporarla a un modelo pivotante (Figura 2). Concretamente, dividimos esta fase en dos pasos :
- La identificación de una MSA candidata,
- Su incorporación a un modelo de pivote.
Identificación de la MSA candidata
La identificación de microservicios es una tarea de ingeniería de software que se produce en el nivel arquitectónico de un monolito y tiene como objetivo aplicar técnicas de ingeniería inversa en sus artefactos de software para identificar los correspondientes candidatos a microservicios y su descripción dentro de un MSA. El proceso de identificación se basa en un conjunto de patrones/estrategias, restricciones y atributos de calidad que conforman y guían su curso.
En el contexto de este proyecto, nos centramos en la identificación de microservicios a partir del código fuente de una aplicación monolítica orientada a objetos. Una forma común de lograrlo es un enfoque basado en gráficos que emplea técnicas de agrupación y visualización de gráficos para identificar los microservicios candidatos a partir del código fuente del monolito. En particular, aplicamos el enfoque propuesto en el Artículo de la primera parte que extrae la arquitectura por capas antes de particionar sus artefactos utilizando un algoritmo de clustering para representar el MSA candidato como un conjunto de clusters LayerEntity.
El paso inicial de la ingeniería inversa de la arquitectura por capas cumple una importante función en el proceso global de migración. Además, en la transformación dirigida por modelos también cumple la función de estructurar la arquitectura interna de cada microservicio identificado. Una vez que se obtiene la MSA candidata a partir del paso de identificación, se enviará al arquitecto de software para su validación. En consecuencia, el arquitecto también puede interactuar con el MSA candidato para modificarlo. En caso contrario, el proceso de identificación termina y el MSA candidato puede incorporarse a un nuevo modelo. Además, para acompañar el proceso iterativo que subyace a la implementación de nuestra migración, añadimos un proceso de identificación manual para permitir el perfeccionamiento/refinamiento de la arquitectura de microservicios por parte de expertos
Candidatura a la incorporación de la MSA
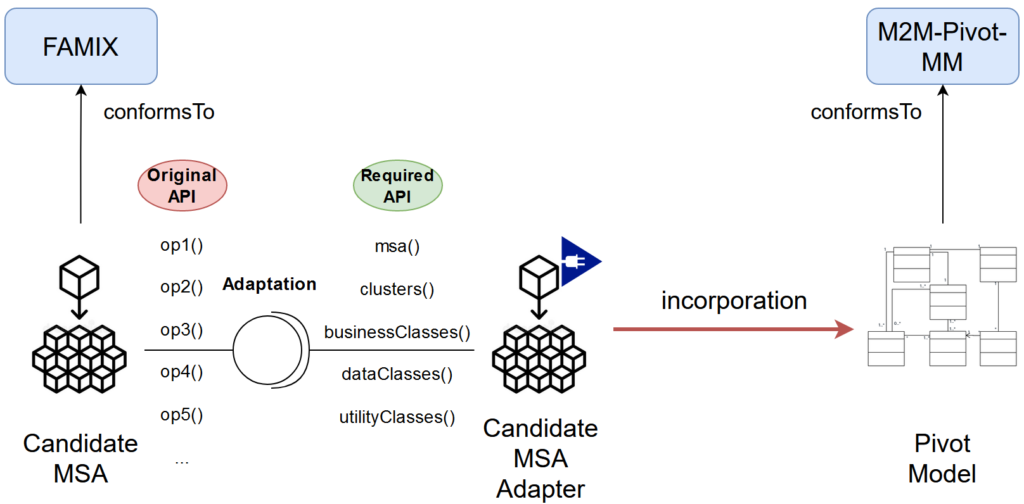
El segundo paso consiste en incorporar el MSA candidato producido por el proceso de identificación del MSA en un metamodelo de pivote intermedio, a saber, el metamodelo de pivote monolítico a microservicios (M2M-Pivot-MM).
De hecho, el proceso de identificación de MSA sólo proporciona un marco incompleto que describe las líneas generales del modelo de MSA objetivo en forma de un MSA candidato. Por lo tanto, para completar este proceso, necesitamos describir el MSA candidato mediante un metamodelo adecuadamente dedicado, seguido de la aplicación de las transformaciones necesarias en su modelo para reflejar realmente la descripción del MSA identificado.
Además, nuestro flujo de trabajo se ocupa de los MSA candidatos extraídos mediante procesos de identificación que utilizan algoritmos de agrupación basados en gráficos. De este modo se obtienen descripciones de MSA con una interfaz específica que expone los clusters de clases de las MSA candidatas y sus entidades asociadas. En consecuencia, nuestras reglas de incorporación dependen conceptualmente de esta interfaz.
No obstante, pretendemos que nuestro enfoque sea lo más reutilizable y genérico posible para reducir los esfuerzos de migración. En otras palabras, queremos que estas reglas de incorporación sean independientes de la interfaz de la descripción MSA. Esto resulta necesario para implementarlas una vez y reutilizarlas en diferentes flujos de trabajo que emplean diferentes procesos de identificación que producen descripciones MSA con diferentes interfaces.
En consecuencia, el mecanismo de incorporación emplea el patrón de diseño Adapter. En particular, un adaptador de MSA candidato mapea la API de un MSA candidato a la API esperada por el metamodelo de pivote (véase la figura 3). En otras palabras, el adaptador de la MSA candidata hace que cualquier MSA candidata identificada implemente su interfaz esperada, es decir, que proporcione medios de acceso a la MSA, a sus microservicios candidatos, a sus clases de negocio, datos y utilidades, y a sus interfaces proporcionadas y requeridas.
Una vez que el MSA candidato implementa la interfaz requerida por el adaptador, éste mapea cada entidad recuperada del MSA candidato a su correspondiente entidad en el modelo pivotante.
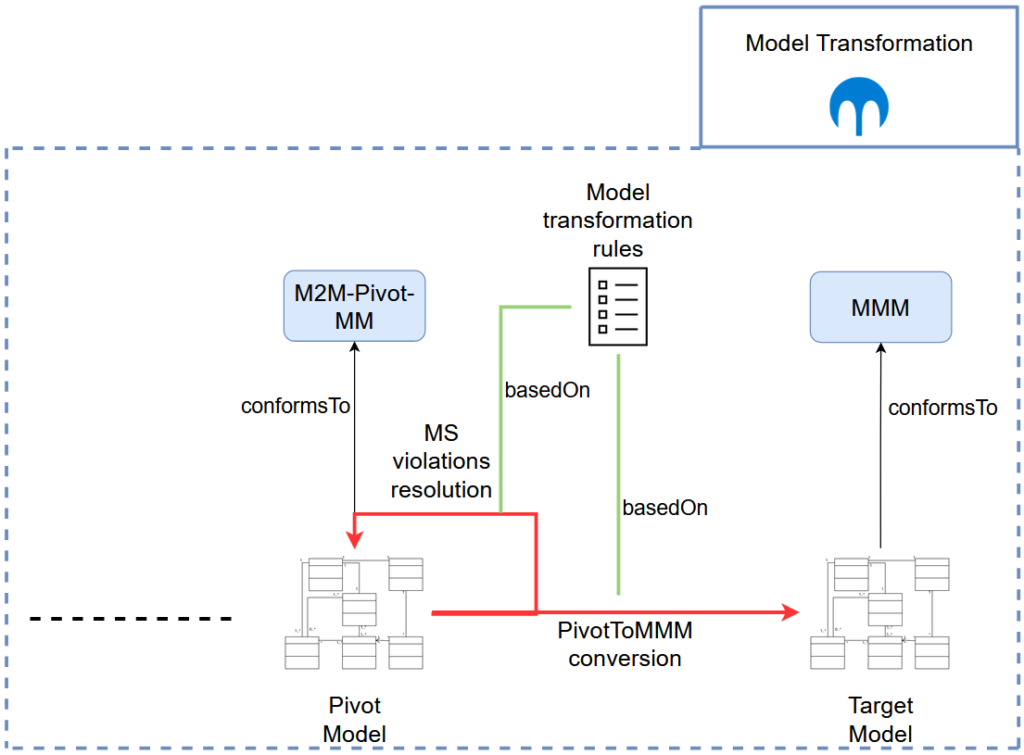
Transformación del modelo
La tercera fase del proceso de migración basado en el MDE es la transformación del modelo (véase la figura 4). Consiste en transformar el modelo de pivote, descrito por el M2M-Pivote- MM, para obtener el modelo de destino, descrito por el Metamodelo de Migración Dirigida por Modelos (MMM) de la Arquitectura de Microservicios.
Ahora que hemos recuperado la arquitectura y hemos identificado el MSA dentro de ella, podemos materializarlo a través de este paso de transformación, donde todo el cluster recuperado será desplegado en su propio microservicio.
Sin embargo, las clases de borde tienen dependencias con clases que pertenecen a otro clúster. Estas dependencias entre clases de diferentes microservicios se denominan violaciones de encapsulación de microservicios. Todas las violaciones deben ser manejadas por métodos de refactorización que convierten las dependencias de tipo OO en tipo MS antes de que un microservicio pueda ser encapsulado y luego generado.
Para encapsular los microservicios se debe resolver el mecanismo de compartición entre los candidatos a microservicio. La característica de un MSA de utilizar comunicación orientada a mensajes entre diferentes microservicios (invocaciones de métodos entre clases de diferentes clusters) debe restringirse a un conjunto de interfaces proporcionadas y requeridas que definen los servicios web que proporciona y los que consume. Además, las llamadas de comunicación entre procesos (IPC) entre microservicios se limitan a la comunicación basada en valores (primitivas y datos serializados). Estas dependencias OO explícitas, las dependencias implícitas entre clusters deben ser abordadas para encapsular completamente los candidatos a microservicios. El mecanismo de herencia y el manejo de excepciones son los dos principales mecanismos OO implícitos que deben ser abordados. En particular, una violación de la herencia se define como una clase que tiene una superclase que pertenece a otro clúster. La violación del manejo de excepciones se define como una clase que lanza una excepción que es capturada por una clase que pertenece a otro clúster.
Ambos mecanismos OO deben ser abordados y transformados en dependencias de tipo MS.
Por último, los MSA generados tras la etapa de transformación deben cumplir dos características operativas adicionales: (1) los microservicios deben ejecutarse en su propio
y (2) deben ser desplegables automáticamente. Para ajustarse a estas características operativas, cada microservicio debe definir un proyecto independiente que debe ser configurado para su despliegue en la nube. Ambas características deben abordarse durante la generación del código fuente de cada microservicio. (Más información sobre la violación de la encapsulación en este artículo)
En particular, distinguimos entre dos tipos diferentes de transformaciones del modelo, cada una de las cuales cumple un objetivo bien definido en el curso del proceso de migración: (1) la resolución de violaciones de encapsulación de microservicios y (2) la conversión Pivot2MMM.
Para entender las razones de la distinción entre estos dos tipos de transformaciones del modelo, tenemos que empezar por examinar su entrada, es decir, el modelo pivote. Como se ha mencionado anteriormente, el modelo pivote se obtiene tras las fases de identificación e incorporación de las MSA candidatas del proceso de migración. En particular, el modelo pivote incorpora el MSA candidato identificado, que consiste en todos los microservicios candidatos, de manera que cada microservicio candidato se representa como un grupo de clases obtenidas del modelo fuente original.
El acto de crear candidatos a microservicio a partir del conjunto de clases de un monolito se define como encapsulación de microservicios. En este contexto, cada microservicio es su propia aplicación.
Por lo tanto, las clases que residen en un microservicio deben tener su acceso restringido desde las clases que pertenecen a otros microservicios. En otras palabras, un microservicio encapsula su propio conjunto de clases. Cuando una clase encapsulada por un microservicio depende de una clase encapsulada por otro microservicio, se produce una violación de la encapsulación del microservicio. Estas dependencias a nivel de clase incluyen invocaciones de métodos, instancias de clases, accesos a atributos públicos, herencias de clases, implementaciones de interfaces de clases, entre otras.
De este modo, observamos que siguen existiendo dependencias a nivel de clase entre las clases que pertenecen a diferentes candidatos a microservicio en el modelo de pivote (véase la figura 4)a pesar de la etapa de identificación de los microservicios. De hecho, la tarea de identificación de microservicios no puede eliminar por completo dichas dependencias, sino que, en el mejor de los casos, puede intentar minimizarlas.
Sin embargo, un MSA bien elaborado debería carecer de tales violaciones. Por lo tanto, antes de la transformación del modelo pivotante en el modelo objetivo, debemos identificar estas violaciones en el modelo pivotante y resolverlas debidamente. En consecuencia, descomponemos nuestra fase de transformación del modelo en dos pasos que cumplen los siguientes objetivos respectivamente:
- Identificar y resolver las violaciones de encapsulación de microservicios en el modelo de pivote
- Convertir el modelo de pivote sin violaciones en el modelo objetivo.
Exportación de modelos
La cuarta y última fase del proceso de migración basado en MDE consiste en generar, empaquetar y desplegar el código de destino del proyecto basándose en su correspondiente modelo MSA de destino. Dependiendo del modelo MSA de destino, un experto puede configurar un exportador de modelos para elegir cómo se generarán los artefactos deseados. En pocas palabras, las configuraciones incluyen la elección de las tecnologías del marco de trabajo de destino, los constructores de proyectos, los gestores de dependencias y otras tecnologías relevantes para los microservicios, como la tecnología de contenerización, los interruptores, el descubrimiento de servicios, los clientes de API o los protocolos de comunicación.
Por ejemplo, si el modelo de destino debe exportarse como un conjunto de proyectos Spring Boot2, el exportador de modelos debe generar un proyecto Spring Boot para cada microservicio del modelo MSA de destino. Además, debe asegurarse de que los paquetes de los nuevos proyectos generados importen correctamente las dependencias necesarias de Spring Boot. Esto se hace utilizando los constructores de proyectos y los gestores de dependencias (por ejemplo, Maven, Gradle, etc.) utilizados con el monolito de origen. Además, el exportador del modelo de destino debe generar una imagen de contenedor para cada microservicio del modelo MSA de destino, describiendo los detalles de configuración necesarios para la creación y el despliegue de su correspondiente contenedor. Por ejemplo, si el exportador de modelos está configurado para desplegar cada microservicio del modelo MSA de destino en un contenedor Docker3, entonces se debe crear un Dockerfile correspondiente para describir su imagen Docker.
Por último, se puede generar un archivo de configuración a nivel de MSA para describir los detalles de configuración a nivel de MSA de sus microservicios. En el caso de la contenedorización Docker, por ejemplo, se puede generar un archivo docker-compose para controlar, configurar y desplegar cada microservicio a través de su imagen Docker.
En resumen
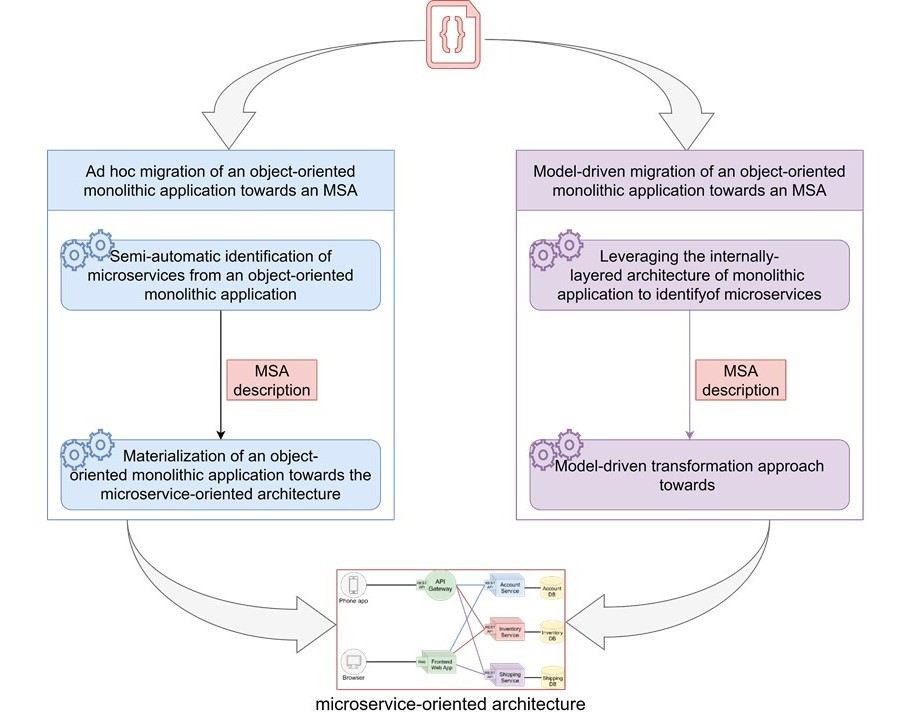
En este proyecto, presentamos dos enfoques diferentes para migrar una arquitectura monolítica hacia una arquitectura MSA.
El primer método consiste en transformar el código fuente para adaptarlo a la arquitectura (representado en azul en la figura 6), mientras que en el segundo método pasamos por un modelo para representar la arquitectura objetivo y luego generamos el código que le corresponde (representado en púrpura en la figura 6).
Referencias
[1] E. Barry, C. Kemerer y S. Slaughter, "Toward a detailed classification scheme for software maintenance activities", AMCIS 1999 Proceedings, p. 251, 01 1999.
[2] J. Bisbal, D. Lawless, B. Wu y J. Grimson, "Legacy information system migration: A brief review of problems, solutions and research issues", IEEE software, vol. 16, no. 5, pp. 103-111, 06 1999.
[3] I. Sommerville, Software Engineering, 9th ed. USA: Addison-Wesley Publishing Company, 2010.
[4] J. Bisbal, D. Lawless, B. Wu y J. Grimson, "Legacy information systems: Issues and directions", Software, IEEE, vol. 16, pp. 103 - 111, 10 1999.
[5] C. Wagner, Model-Driven Software Migration: A Methodology: Reingeniería, recuperación y modernización de sistemas heredados. Springer Science & Business
Medios de comunicación, 03 2014.
[6] J. Lewis y M. Fowler, "Microservicios: Una definición de este nuevo término arquitectónico", https://martinfowler.com/articles/microservices.html, 2014, acceso: 2020-06-20.
[7] X. J. Hong, H. S. Yang y Y. H. Kim, "Performance analysis of restful api and rabbitmq for microservice web application", en 2018 International Conference on Information and Communication Technology Convergence (ICTC). IEEE, 10 2018, pp. 257-259.
[8] C. Richardson, Microservices Patterns: Con Ejemplos en Java. Manning Publications, 2018. [En línea]. Disponible: https://books.google.de/books?id=UeK1swEACAAJ
[9] S. Newman, Building Microservices: Designing Fine- Grained Systems. "O'Reilly Media, Inc., 2015.
[10] P. Zaragoza, A.-D. Seriai, A. Seriai, H.-L. Bouziane, A. Shatnawi, y M. Derras, "Refactoring monolithic object-oriented source code to materialize microserviceoriented architecture", en ICSOFT, 2021.
[11] F. Fleurey, E. Breton, B. Baudry, A. Nicolas y J.-M. J'ez'equel, "Model-driven engineering for software migration in a large industrial context", en Model Driven Engineering Languages and Systems, G. Engels, B. Opdyke, D. C. Schmidt y F. Weil, Eds. Berlín, Heidelberg: Springer Berlin Heidelberg, 2007, pp. 482-497.
[12] D. C. Schmidt, "Guest editor's introduction: Modeldriven engineering", Computer, vol. 39, nº 2, p. 25-31, febrero de 2006. [En línea]. Disponible: https://doi.org/10.1109/ MC.2006.58
[13] M. Waseem, P. Liang, G. M'arquez, M. Shahin, A. A. Khan y A. Ahmad, "A decision model for selecting patterns and strategies to decompose applications into microservices", 2021.
[14] A. Selmadji, A.-D. Seriai, H. L. Bouziane, R. Oumarou Mahamane, P. Zaragoza y C. Dony, "From monolithic architecture style to microservice
uno basado en un enfoque semiautomático", en 2020 IEEE International Conference on Software Architecture (ICSA), 2020, pp. 157-168.
[15] S. Demeyer, S. Tichelaar y S. Ducasse, "Famix 2.1 - the famoos information exchange model", Universidad de Berna, Tech. Rep., 01 2001.
[16] S. Demeyer, S. Ducasse, y E. Tichelaar, "Why famix and not uml? uml shortcomings for coping with roundtrip engineering," in Proceedings of¡¡ UML'99¿¿, Fort Collins. Citeseer, 09 1999.
[17] S. Tichelaar, S. Ducasse y S. Demeyer, "Famix and xmi", en Proceedings Seventh Working Conference on Reverse Engineering. IEEE, 02 2000, pp. 296 - 298.
[18] S. Ducasse, M. Lanza y E. Tichelaar, "Moose: an extensible language-independent environment for reengineering object-oriented systems", en Proceedings of the Second International Symposium on Constructing Software Engineering Tools (CoSET 2000), vol. 4. Citeseer, 04 2000.
[19] S. Ducasse, N. Anquetil, M. Bhatti, A. Hora, J. Laval y T. Girba, "Mse and famix 3.0: an interexchange format and source code model
family", Laboratoire d'Informatique Fondamentale de Lille, Informe de investigación, 05 2012. [En línea]. Disponible: https://hal.inria.fr/hal-00646884
[20] F. Rademacher, J. Sorgalla, S. Sachweh y A. Z¨undorf, "Towards a viewpoint-specific metamodel for modeldriven development of microservice architecture", 04 2018.
[21] A. Levcovitz, R. Terra y M. T. Valente, "Towards a Technique for Extracting Microservices from Monolithic Enterprise Systems", CoRR, vol. abs/1605.0, 2016. [En línea]. Disponible: http://arxiv.org/abs/1605.03175
[22] R. Chen, S. Li y Z. Li, "From Monolith to Microservices: A Dataflow-Driven Approach", Proceedings Asia-Pacific Software Engineering Conference, APSEC, pp. 466-475, 2018.
[23] M. Gysel, L. K¨olbener, W. Giersche y O. Zimmermann, "Service cutter: A systematic approach to service decomposition", en European Conference on Service-Oriented and Cloud Computing, 09 2016, pp. 185-200.
[24] G. Mazlami, J. Cito y P. Leitner, "Extraction of Microservices from Monolithic Software Architectures", en 2017 IEEE ICWS. IEEE, jun 2017, pp. 524-531.
[en línea]. Disponible: http://ieeexplore.ieee.org/document/8029803/
[25] C. Pahl y P. Jamshidi, "Microservicios: A systematic mapping study", en Proceedings of the 6th International Conference on Cloud Computing and Services Science Volume 1 and 2, ser. CLOSER 2016. Setubal, PRT: SCITEPRESS - Publicaciones de Ciencia y Tecnología, Lda, 2016, p. 137-146. [En línea]. Disponible: https: //doi.org/10.5220/0005785501370146
[26] Z. Al-Shara, "Migrating Object Oriented Applications into Component-Based ones" (Migración de aplicaciones orientadas a objetos a aplicaciones basadas en componentes), Tesis, Universidad de Montpellier, noviembre de 2016. [En línea]. Disponible: https:
//tel.archives-ouvertes.fr/tel-01816975
[27] A. Bucchiarone, K. Soysal y C. Guidi, "A modeldriven approach towards automatic migration to microservices", en Software Engineering Aspects of Continuous Development and New Paradigms of Software Production and Deployment. Springer International Publishing, 2020, pp. 15-36.