The software for public services are always more complex as the regulation evolves constantly and the user requirement continues to refine. Thus, the quality of the software declines, making it more difficult to maintain and use. For example, some anomalies occurring in the production environment cannot be reproduced and therefore cannot be resolved. From the user’s point of view, the software becomes more complex to use and understand, which affects the user experience.
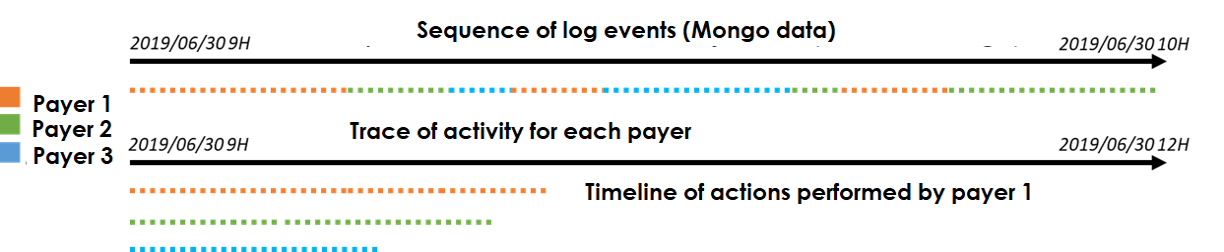
To guarantee an acceptable quality level, we explore the exploitation of user traces. A user trace is a footprint left by a user when using a software. At short term, the objective is providing feedback for the production teams. For example, it we could allow us to confront the acceptance test traces to the actual usage. At long term, a smart assistant could be designed to help the user to perform some tricky tasks or repetitive actions. To do so, it is necessary to model the software from user traces. The analysis of user activity is particularly interesting because it gives a realistic overview of how the user uses the application and how it works. Finally, no action is required on the part of the user to capture, record and collect observations. However, the data collected must respect the user’s privacy and be part of an ethical processing framework.

Many scientific fields study the user’s activity but achieve different objectives. We focus on process discovery because the business process model is the starting point for process adaptation. Right now, he’s the most valuable.


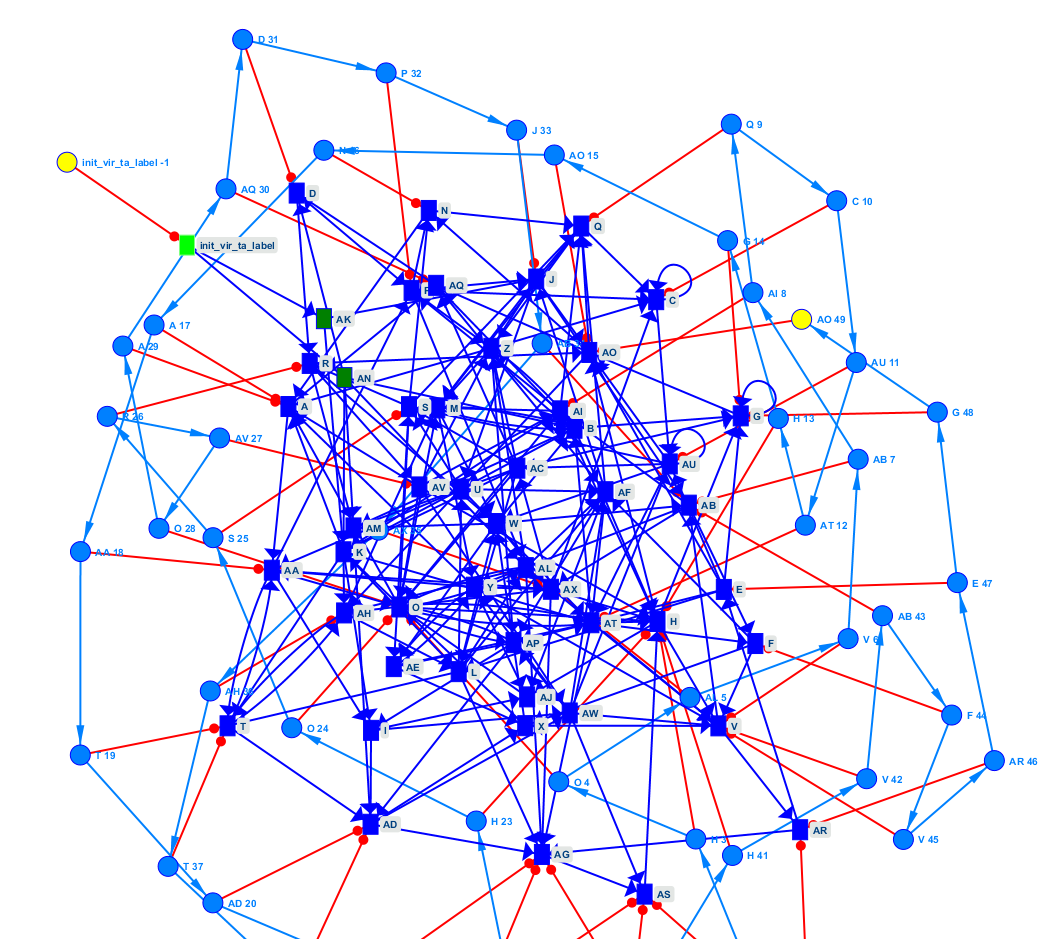
Existing approaches offer different methods for finding a process model from activity traces. The best known is process mining (van der Aalst, 2016). Several experiments were conducted on an open access data set of Berger-Levrault software. The experiments are based on a successful study (Astromskis et al., 2015) but fail to replicate these results. Two points can explain this:
- The design of the logging system is crucial. The best way is to design the logging system according to a known objective. But with existing software this logging system already exists, how can it be improved? More generally: how to design a good logging system?
- he results show characteristics of our data that cannot be addressed by current process extraction methods. For example, the data are noisy and may describe intersecting use cases without labelling information. These data problems stem from the application’s non-structured workflow (❷ and ❸). From a design point of view, workflow ❶ is better, but this can be painful for the user when the business process is complex ❸.
Our objective is to design a multi-agent system. Indeed, adaptive multi-agent systems have already proven their ability to manage complex data. Our work is broken down into step, the first one designs and implements a multi-agent system capable of detecting and correcting errors in the traces. In this step, the process model is assumed to be known. The results of the evaluation are encouraging. The second step adds errors to the process model. New agent behaviors will have to be determined to address this issue. This step prepares for a start without a presupposed model. The model must then be fully discovered.