Avant la numérisation totale, les factures étaient contrôlées visuellement par les agents. Aujourd'hui les factures sont entièrement dématérialisées, donc personne ne vérifie leur mise en page, leur lisibilité, et leur cohérence avec leurs métadonnées. En France, le contrôle d'un flux de données de factures (ORMC : Order of Multi Creditor Receipt) peut prendre jusqu'à 1 journée complète. Le flux de données ORMC est envoyé par plus de plus de 10 de nos produits comme Sedit GF, eGFEvolution, BL.enfance, E.FACTU (STD) Standard, E.FACTU (PTL) Point de livraison, E.FACTU (EAU) Eau et assainissement, MILORD EAU, MILORD FACFAM (Facturation aux familles), MILORD FACT97 (facturation diverses), MILORD HEB98 (Facturation EHPAD).
DeepFacture est un outil qui résout le problème susmentionné grâce à ses nombreux points forts :
- Formation rapide: seule une vingtaine de documents annotés permettent à l'IA d'apprendre et de fonctionner.
- Puissant: 1 seconde suffit pour analyser un document. 4 min pour un flux de 260 factures !
- Mise en commun: DeepFacture est APIisé (REST / Open API 3.0), Cloud-Ready, facile à intégrer et accessible à tous.
- Extensible: peut être étendu à tous les documents standards : Billets, bulletins d'information, cartes d'identité, passeports, chèques, cartes grises, lettres, formulaires, etc...
- Recherche: le fruit de nos recherches en analyse d'images et en apprentissage profond au fil des ans.
- Source ouverte: exclusivement basé sur des bibliothèques open-source du monde académique.
Comment cela fonctionne-t-il ?
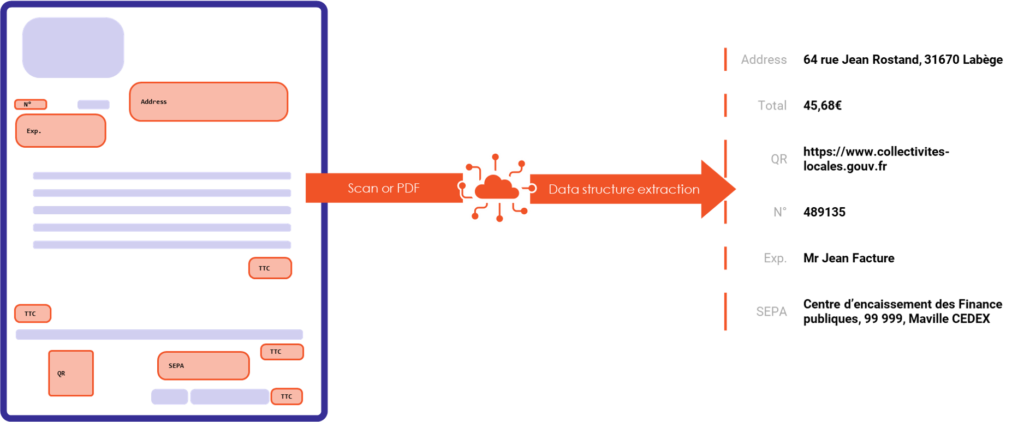
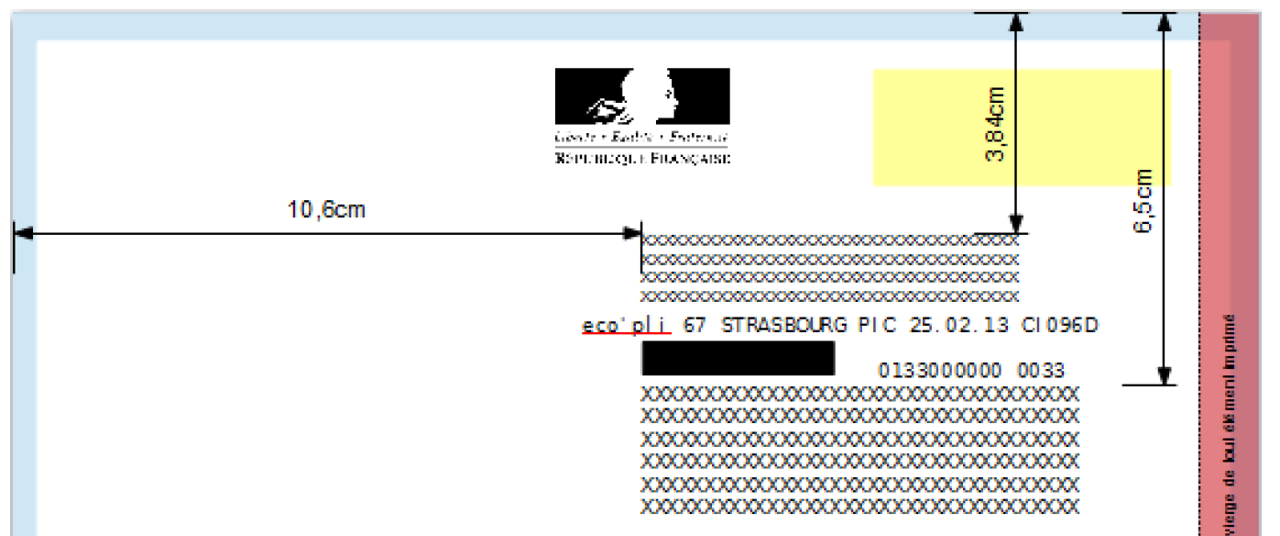
Les produits de Berger-Levrault destinés aux collectivités locales génèrent des flux de factures qui sont envoyés à la DGFIP au format XML. La réglementation impose un certain nombre de règles concernant la forme et le contenu de ces flux, ainsi que la charte graphique des factures. La figure suivante illustre un exemple de ces règles. Les cadres d'adresse de l'expéditeur et du destinataire doivent être positionnés à des endroits précis. Les valeurs de ces champs doivent également être similaires à celles mentionnées dans les balises XML du flux.
Un flux qui n'est pas conforme est systématiquement rejeté par l'Office. DGFIP. En effet, la non-conformité peut avoir des conséquences néfastes pour des milliers de personnes : non-réception du courrier en raison d'une adresse non lisible ou mal positionnée, non prise en compte d'un paiement, doublons dans les DGFIP base de données, etc. Afin de s'assurer que les flux générés sont conformes à la réglementation, il est important d'inclure dans le processus une phase de contrôle qui explore l'ensemble des factures et vérifie que toutes les règles sont respectées. Cette phase de contrôle est actuellement réalisée par du personnel humain. Il s'agit d'un travail répétitif, fastidieux et chronophage. En effet, pour un flux donné, il y a des dizaines de contrôles à effectuer sur des centaines de factures. Le contrôle d'un flux peut prendre plusieurs heures.
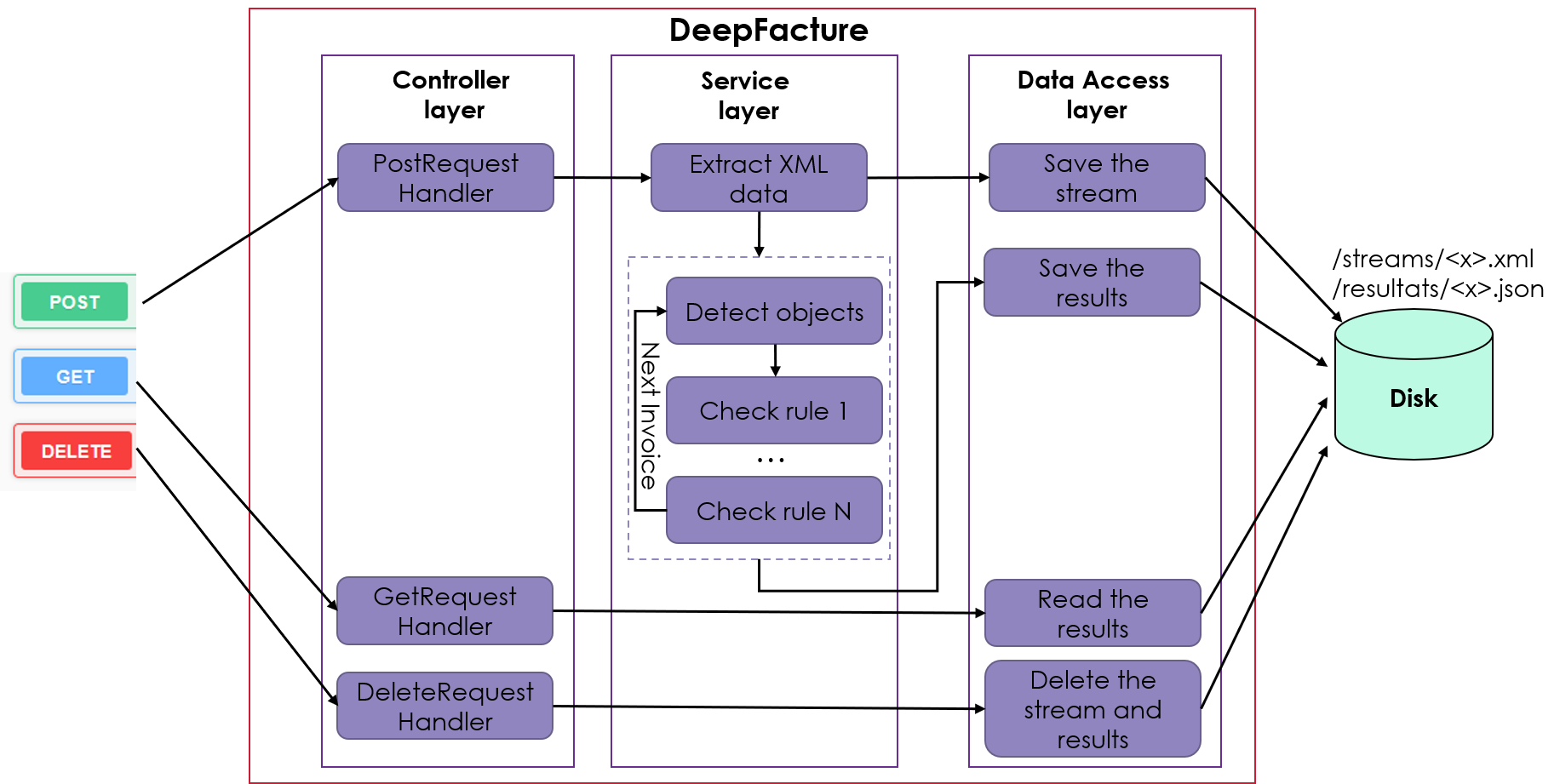
L'objectif du projet DeepFacture est de développer une API qui automatise la vérification des flux destinés à la DGFIP. La figure suivante illustre l'interaction de l'API avec le monde extérieur ainsi que son architecture interne. L'API reçoit un flux XML en entrée, analyse le contenu de chaque facture, vérifie la conformité de chaque règle et renvoie un rapport JSON en sortie, précisant si le flux est conforme et, dans le cas contraire, les raisons de cette conformité.
Localisation d'objets et extraction de données d'un PDF
L'API DeepFacture doit être capable de localiser les différents éléments de la facture (champs d'adresse, logo...) et d'extraire la valeur de chaque élément. Dans l'état de l'art, il existe deux approches pour y parvenir [1] :
Correspondance de motifs: il s'agit d'une approche intuitive qui consiste à identifier des modèles dans les documents et à les utiliser pour extraire des informations. Par exemple, le montant total d'une facture est généralement un nombre décimal à droite du mot "Total". Il existe plusieurs techniques de comparaison de motifs dans la littérature [2]-[5]. Les motifs peuvent être implémentés avec une expression régulière ou générés avec une annotation manuelle et une heuristique.
- Avantage: La comparaison de modèles fonctionne bien lorsque les documents sont homogènes et structurés.
- Désavantagela création et la maintenance des modèles demandent du temps et de l'expertise. De plus, elle ne s'étend pas à d'autres modèles de documents.
Apprentissage automatiqueCette approche est basée sur un modèle entraîné à partir d'un corpus de documents annotés. Certains travaux considèrent la tâche comme une classification de mots. Pour chaque mot du document, on décide de l'extraire ou non. Si plusieurs valeurs doivent être extraites (total, date, etc.), la tâche devient une classification multiclasse. Pour résoudre le problème, ces travaux ont opté soit pour l'ingénierie des caractéristiques plus un modèle classique d'apprentissage automatique tel que les SVM [6], soit pour l'intégration des mots plus les réseaux de neurones [7]-[11]. Il existe également des travaux qui proposent une approche de bout en bout. Dans ce cas, le modèle considère le document dans son ensemble et n'indique pas l'emplacement de l'information à extraire mais renvoie directement la valeur de l'information recherchée [1].
Les documents peuvent également être vus comme des images (dans le cas de scans, par exemple). Dans ce cas, il devient intéressant d'exploiter les méthodes de localisation d'objets dans les images : YOLO [12], Single Shot MultiBox Detector [13], Fast R-CNN [14], Faster R-CNN [15], Feature Pyramid Networks [16]... Une fois l'objet détecté, une OCR est utilisée pour extraire le texte qu'il contient.
- Avantagel'approche est bien généralisée pour de nombreux modèles de documents.
- Désavantage: la nécessité de disposer d'un grand corpus où chaque mot doit être étiqueté. L'annotation manuelle est un processus coûteux et n'est donc pas réalisable dans de nombreux cas.
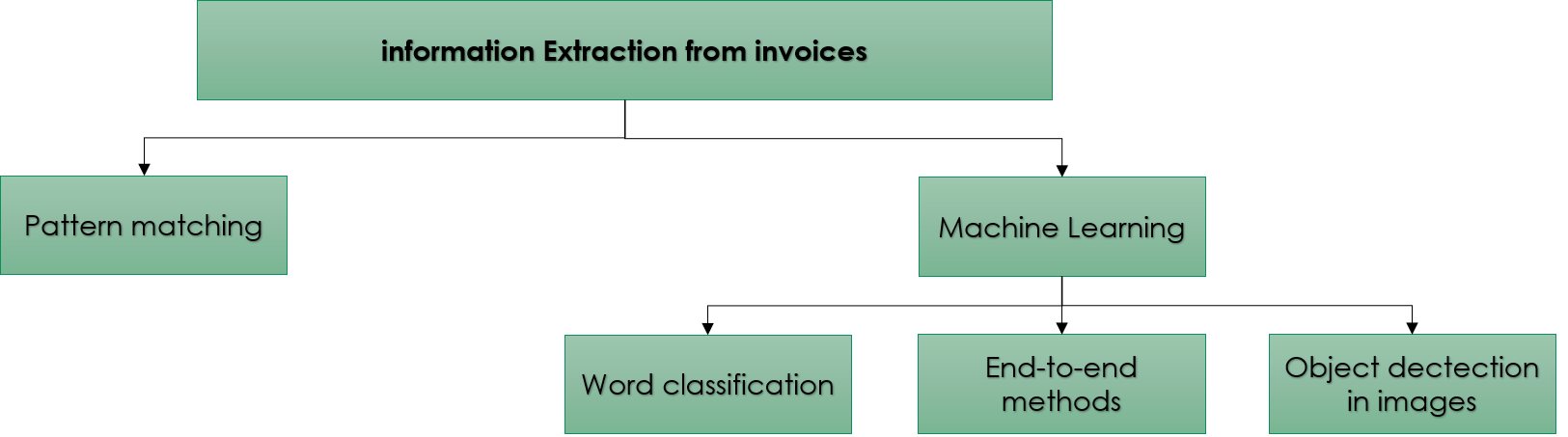
Pour le projet DeepFacture, nous disposons de plusieurs formats de factures avec de possibles éléments mal placés. En outre, DGFIP Les règles peuvent être évaluées à tout moment. L'établissement de toutes les règles possibles est fastidieux et déraisonnable pour une approche de "template-matching". Nous souhaitons adopter une solution qui prend en compte les documents scannés et qui est généralisée à d'autres formats de documents afin d'exploiter le pipeline pour d'autres projets futurs. L'approche adoptée est donc l'extraction d'informations avec " apprentissage automatique ". Plus précisément, nous utilisons des techniques d'apprentissage profond pour localiser des objets dans des images.
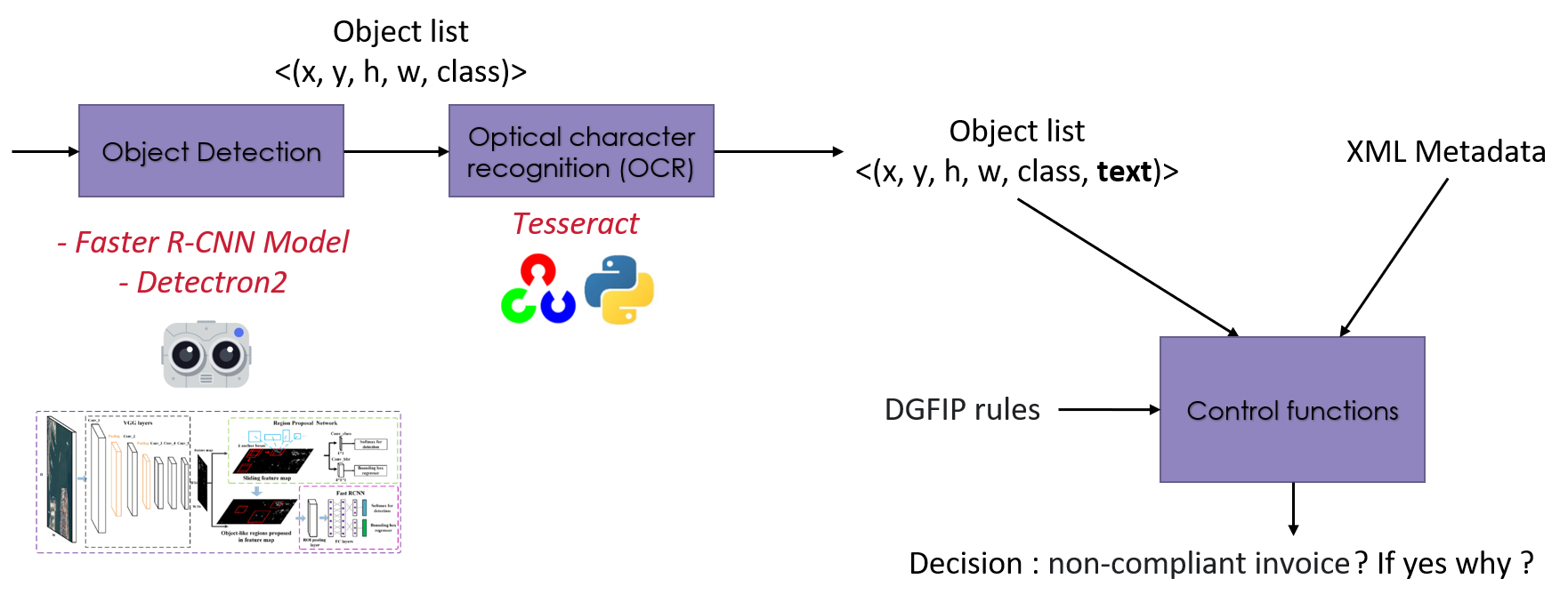
Processus DeepFacture
La réponse à cette question est illustrée dans la figure suivante. Nous utilisons un R-CNN plus rapide (implémenté dans la bibliothèque Python Detectron2) pour localiser les objets dans la facture. Ce modèle renvoie les coordonnées et la classe de chaque objet. Ensuite, nous utilisons une fonction OCR (implémentée dans la bibliothèque Python Detectron2) pour localiser les objets dans la facture. Tesseract ) pour extraire les informations textuelles de l'objet. Enfin, nous utilisons les fonctions de contrôle que nous avons implémentées pour vérifier si la facture est bonne ou non. Ces fonctions sont basées sur la liste des objets (avec leurs coordonnées, leur classe et leur texte), sur les métadonnées du flux XML et sur l'option DGFIP des règles pour analyser la conformité de la facture.
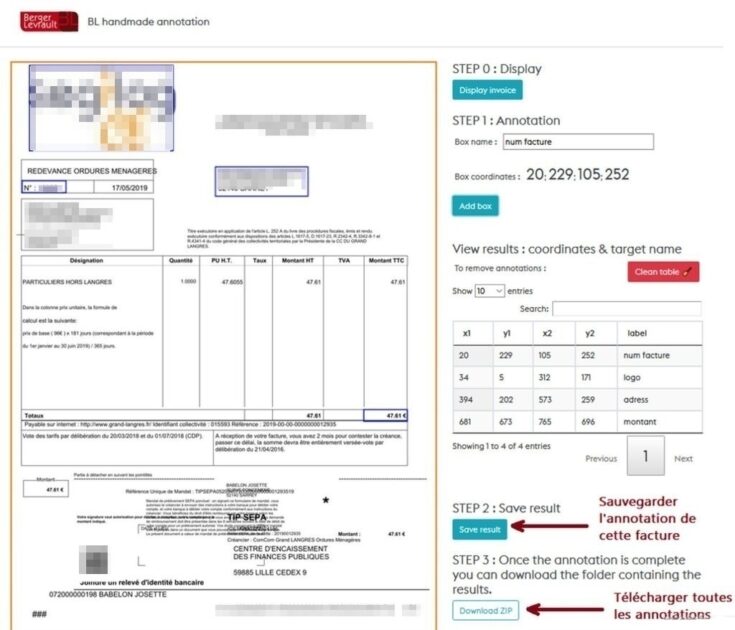
L'apprentissage supervisé a besoin de données annotées
L'approche que nous avons adoptée nécessite des données annotées pour piloter le modèle de localisation des objets. Nous développons actuellement une interface web pour l'annotation d'images. Nous disposons déjà d'une version qui permet de charger une facture, puis d'annoter visuellement les objets et enfin d'écrire le résultat dans un fichier. Le contenu de ce fichier est utilisé pour entraîner le modèle Faster R-CNN. La figure suivante montre un aperçu de cette interface.
Pour évaluer la qualité du modèle, nous nous basons sur la "précision moyenne" [17]. Le code OpenSource pour l'évaluation est disponible sur Internet. Ensuite, la préparation du jeu de test : nous construisons un jeu de factures annotées aussi général que possible en termes de modèle et de types d'erreurs, nous prenons 80% à 85% du total des factures annotées pour entraîner le modèle, le reste des factures pour le tester.
Notre objectif : Annoter le moins possible !
L'apprentissage profond nécessite généralement un grand nombre de données annotées pour converger de manière fiable. Dans notre cas, nous avons réussi à construire un modèle qui ne nécessite que 20 à 30 factures annotées pour converger avec d'excellents résultats. Il existe plusieurs façons d'atteindre cet objectif :
- Générer un corpus artificiel: une base d'adresses préétablie, un texte généré de manière aléatoire ou provenant du web ou d'une autre source, des numéros générés de manière aléatoire, un emplacement généré de manière aléatoire.
- Utilisez "l'augmentation des données".: prendre des factures correctes et bien structurées, puis déplacer, redimensionner et modifier les objets de façon aléatoire.
- Utiliser un modèle pré-entraînéUne première passe d'entraînement avec un grand corpus générique. Une deuxième passe d'entraînement avec le petit corpus spécifique des factures.
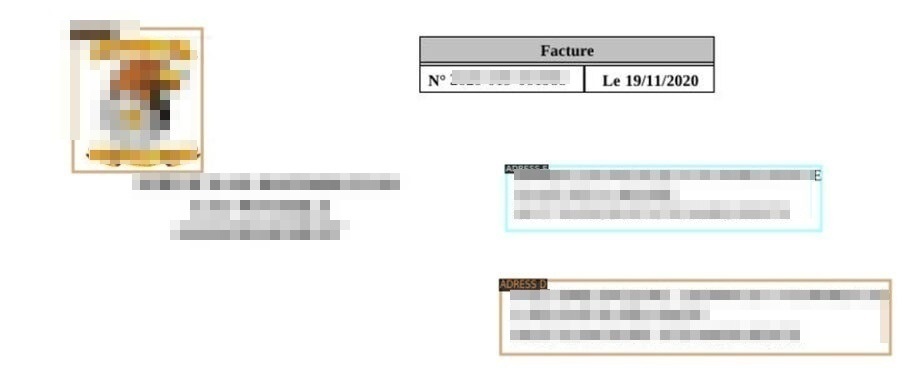
Pour nos premiers tests, nous avons utilisé un modèle pré-formé de Plus rapide-RCNN (avec le Détectron2 bibliothèque). Nous avons effectué une passe d'entraînement avec quelques dizaines de factures que nous avons annotées. Les résultats obtenus ont été satisfaisants. Dans l'exemple suivant, nous avons utilisé le modèle entraîné pour localiser l'adresse du destinataire, l'adresse de l'expéditeur et le logo.
Conclusion
Dans cet article, nous avons présenté DeepFacture, un projet destiné à répondre aux besoins de nos équipes méticuleuses concernant l'automatisation du contrôle des factures envoyées à la DGFIP. L'approche adoptée pour extraire l'information est l'utilisation de techniques de réseaux de neurones pour la détection d'objets dans les images. Nous nous intéressons actuellement au développement d'une interface web générique qui nous permette non seulement d'annoter les images, mais aussi de paramétrer, d'exécuter l'entraînement et le réentraînement du modèle. L'expérience a montré que le pipeline proposé peut être étendu à d'autres études de cas. À l'avenir, nous nous intéresserons à d'autres utilisations. Par exemple, l'extraction d'informations à partir de cartes d'identité d'hôpitaux, etc.
Références
1] R. B. Palm, F. Laws, et O. Winther, "Attend, copy, parse end-to-end information extraction from documents," in Conférence internationale 2019 sur l'analyse et la reconnaissance des documents (ICDAR)2019, p. 329-336.
2] E. Medvet, A. Bartoli et G. Davanzo, "A probabilistic approach to printed document understanding" (Une approche probabiliste de la compréhension des documents imprimés). Int. J. Doc. Anal. Recognit., vol. 14, no. 4, pp. 335-347, 2011.
3] D. Esser, D. Schuster, K. Muthmann, M. Berger, et A. Schill, "Automatic indexing of scanned documents : a layout-based approach," in Reconnaissance et recherche de documents XIX2012, vol. 8297, p. 82970H.
4] D. Schuster et al." Intellix-End-User Trained Information Extraction for Document Archiving ", dans 2013 12e conférence internationale sur l'analyse et la reconnaissance des documents.2013, pp. 101-105.
5] M. Rusinol, T. Benkhelfallah, and V. Poulain d'Andecy, "Field extraction from administrative documents by incremental structural templates," in 2013 12e conférence internationale sur l'analyse et la reconnaissance des documents.2013, p. 1100-1104.
6] Y. Li, K. Bontcheva, et H. Cunningham, "SVM based learning system for information extraction," in Atelier international sur les méthodes déterministes et statistiques dans l'apprentissage automatique2004, p. 319-339.
7] T. Mikolov, I. Sutskever, K. Chen, G. Corrado, et J. Dean, "Distributed representations of words and phrases and their compositionality," arXiv Prepr. arXiv1310.4546, 2013.
8] J. Pennington, R. Socher, et C. D. Manning, "Glove : Global vectors for word representation," in Actes de la conférence 2014 sur les méthodes empiriques de traitement des langues naturelles (EMNLP).2014, p. 1532-1543.
[9] X. Ma et E. Hovy, "End-to-end sequence labeling via bi-directional lstm-cnns-crf," arXiv Prepr. arXiv1603.01354, 2016.
10] G. Lample, M. Ballesteros, S. Subramanian, K. Kawakami, et C. Dyer, "Neural architectures for named entity recognition" (Architectures neuronales pour la reconnaissance des entités nommées). arXiv Prepr. arXiv1603.01360, 2016.
11] C. N. dos Santos et V. Guimaraes, "Boosting named entity recognition with neural character embeddings", [11]. arXiv Prepr. arXiv1505.05008, 2015.
12] J. Redmon et A. Farhadi, "YOLO9000 : better, faster, stronger," in Actes de la conférence de l'IEEE sur la vision par ordinateur et la reconnaissance des formes.2017, p. 7263-7271.
13] W. Liu et al., "Ssd : Single shot multibox detector", dans Conférence européenne sur la vision par ordinateur2016, p. 21-37.
[14] R. Girshick, "Fast r-cnn," in Actes de la conférence internationale de l'IEEE sur la vision par ordinateur.2015, p. 1440-1448.
15] S. Ren, K. He, R. Girshick et J. Sun, "Faster r-cnn : Towards real-time object detection with region proposal networks" (accélération de la détection des objets par les réseaux de proposition de régions). arXiv Prepr. arXiv1506.01497, 2015.
16] T.-Y. Lin, P. Dollár, R. Girshick, K. He, B. Hariharan, et S. Belongie, "Feature pyramid networks for object detection," in Actes de la conférence de l'IEEE sur la vision par ordinateur et la reconnaissance des formes.2017, p. 2117-2125.
17] R. Padilla, S. L. Netto, et E. A. B. da Silva, "A survey on performance metrics for object-detection algorithms," in Conférence internationale 2020 sur le traitement des systèmes, des signaux et des images (IWSSIP)2020, p. 237-242.