
Dans le contexte socio-économique actuel, les entreprises doivent travailler ensemble. L'interopérabilité, qui est l'action de travailler ensemble à travers des systèmes, est un facteur inconditionnel pour y parvenir. Pour fonctionner, les informations partagées doivent être compatibles. Les informations peuvent être incompatibles lorsqu'elles sont construites différemment par des personnes ou des systèmes.
L'objectif de la médiation est de gérer la mise en correspondance syntaxique et sémantique des informations pour fédérer les ressources d'information entre les partenaires. On parle de schéma d'appariement basé sur des méthodes d'apprentissage non supervisé : le processus d'identification automatique d'éléments sémantiquement liés.
Notre objectif est donc d'automatiser ce processus à l'aide d'un schéma de correspondance général qui prend deux schémas d'information construits de manière différente et en produit un cohérent et sémantiquement compréhensible.
Comme les messages sont uniquement textuels, nous avons utilisé des méthodes de traitement du langage naturel (NLP) pour détecter la compatibilité sémantique entre les champs de texte.
Une approche sémantique de médiation pour l'échange de données entre schémas
Choix des paramètres d'entrée
Différents paramètres doivent être pris en compte :
- Le nombre de mots similaires : Les mots sont traduits en vecteurs dans l'algorithme. S'il y a beaucoup de mots similaires, il faut en tenir compte car les données seront proches les unes des autres (on les appelle les voisins).
- Le seuil d'acceptation : il doit être déterminé au début de l'algorithme. Si la distance entre deux vecteurs est inférieure à ce seuil, les champs peuvent être considérés comme concordants, par contre, si la distance est supérieure, la concordance n'est pas acceptée.
- Les meilleurs candidats à considérer à la sortie : Il définit le nombre de termes à prendre en compte lors de la génération des champs de correspondance. En effet, une liste de candidats sera triée au cours du processus. Cette liste peut être exhaustive ou non.
Collecte des données
Dans le processus de médiation, nous aurons deux schémas dans un format similaire ou différent. La première étape du processus sera de les convertir dans un format commun, bien connu et facile à manipuler (CSV par exemple).
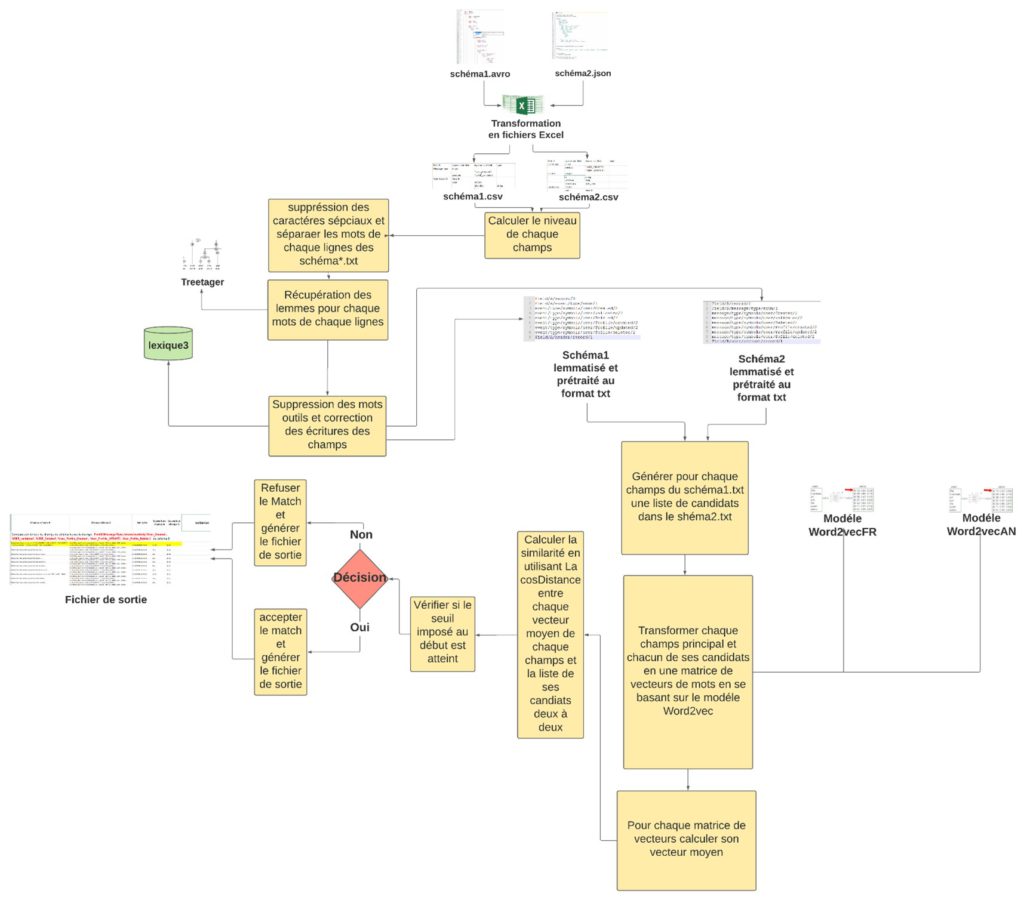
Prétraitement des schémas
Il s'agit d'une étape fondamentale dans le processus de mise en correspondance. Elle élimine le bruit des données qui a un impact négatif sur le modèle de calcul de la similarité (Nous appelons "bruit" la variante orthographique d'un même mot. Il peut s'agir d'une faute d'orthographe ou de la forme plurielle d'un mot). Pour cette étape, nous avons appliqué un prétraitement qui doit "nettoyer" les données. Nous avons mis en place un pipeline de traitement (figure 1) :
- Calcul des champs de niveau : Il fait référence à la position du champ dans la structure du code.
- Caractères spéciaux suppression et la séparation des champs dans les séquences de mots.
- Récupération du lemme : Le lemme est l'infinitif du verbe et la forme masculine singulière d'un nom, d'un adjectif ou d'un adverbe. L'objectif de la récupération des lemmes est de regrouper les termes qui expriment une idée similaire afin de montrer si les champs correspondent ou non. La lemmatisation tient compte du contexte dans lequel le mot a été utilisé et trouve sa forme "commune".
- Arrêtez la suppression des mots : Les mots vides sont très fréquents et ne contribuent pas à la compréhension. Nous avons constitué une liste de mots vides français et anglais avec 890 mots (pronoms par exemple).
- Correction des fautes d'orthographe : Les mots mal orthographiés ne peuvent pas être lemmatisés et ne seront pas reconnus par notre modèle. Pour éviter ce problème, nous avons établi une similarité orthographique dans notre solution pour identifier les mots similaires et éviter les erreurs stupides dues à l'orthographe.
Étapes de mise en correspondance des schémas
La première étape des schémas de correspondance consiste à générer une liste de candidats qui consiste à lister les mots candidats pour chaque champ du schéma 1 et du schéma 2. Cette liste dépendra du nombre de mots similaires définis précédemment et l'appariement ne sera appliqué que sur cette liste. La deuxième étape consiste à transformer les termes en vecteurs. Les mots des deux schémas originaux peuvent être dans des langues différentes, il est donc essentiel de les traduire dans un même langage : un espace vectoriel unique. A partir de ces données, nous pouvons construire la matrice vectorielle et calculer les unités moyennes pour représenter un champ avec un seul vecteur. Sur la base de ces informations, l'algorithme sera en mesure de voir si les champs sont similaires ou non en les comparant au seuil déterminé auparavant.

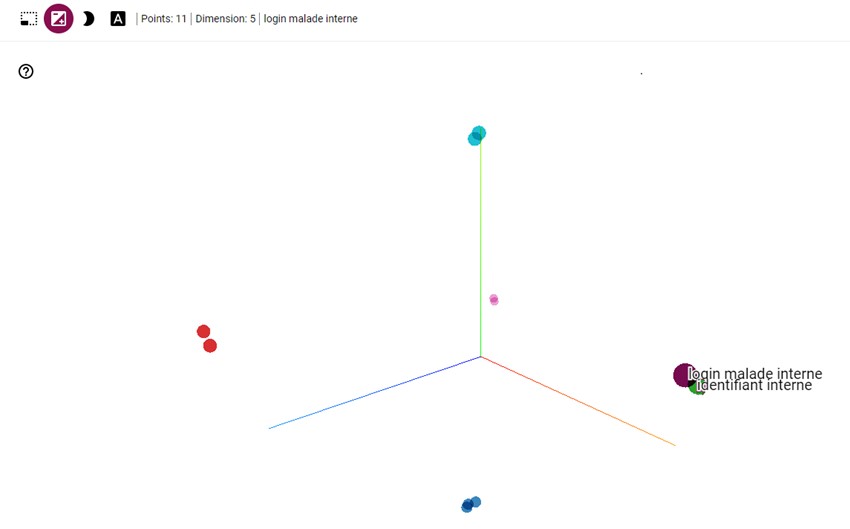
Comme vous pouvez l'observer sur la figure, la proximité des points dans le nuage déterminera la similarité des champs.
Expérimentation et résultats
Dans le tableau ci-dessous (figure 4), nous synthétisons le résultat de nos différentes expérimentations et leurs évaluations. V1, V2, V3 et V4, représentent nos quatre variantes en fonction du nombre de termes voisins et du seuil que nous avons configuré.
- Dans notre première expérimentation, nous avons testé notre approche de mise en correspondance des schémas sur les deux schémas suivants : Application Role Event Specification et Message Type Role Event.
- Au cours de la deuxième expérimentation, nous avons mesuré l'intérêt de notre approche de mise en correspondance des schémas dans le secteur de la santé. Nous avons testé nos schémas de correspondance sur deux schémas nommés Synchronisation des patients et Données médicales internes des patients que nous avons construits manuellement.
- Pour la dernière expérimentation, nous avons testé la lemmatisation et la correction orthographique de notre approche en utilisant le même schéma que dans l'expérimentation 2 sans appliquer la lemmatisation et la correction orthographique.

La précision est la relation entre les paires correctement appariées et le nombre de paires appariées.
Le rappel est la relation entre la paire correctement appariée et le nombre de paires à apparier.
FMesure est la mesure harmonique entre Precision et Recall.
Les résultats de l'expérimentation montrent que la prise en compte des champs de niveau présente un avantage pour notre approche.En effet, au cours de la comparaison des champs, la F-Mesure atteint 83% lorsque l'on définit un nombre de mots voisins.
Le troisième résultat de l'expérimentation montre que importance de la lemmatisation et de la correction orthographique. Ils ont amélioré la F-Mesure de 35% et permettent de couvrir plus de termes anglais et français.
A travers les expérimentations 1 et 2 utilisant V1, nous avons remarqué qu'avec un seuil plus petit que 1 (0.6) notre approche couvre toujours une grande partie des champs. De plus, le compromis que nous avons choisi entre le nombre de "voisins" et le seuil donne de meilleurs résultats.
En résumé, nous avons pu observer les meilleurs résultats grâce à notre première approche qui inclut la lemmatisation et l'orthographe. correction. Cependant, il serait intéressant d'explorer davantage le type de champs et l'approche distinctive pour la mise en correspondance des schémas (comme les principaux termes candidats et le type de champs par exemple).



