
En el contexto socioeconómico actual, las empresas deben trabajar juntas. La interoperabilidad, que es la acción de trabajar juntos a través de sistemas, es un factor incondicional para hacerlo. Para que funcione, la información que se comparte debe ser compatible. La información puede ser incompatible cuando las personas o los sistemas la construyen de forma diferente.
El objetivo de la mediación es gestionar el emparejamiento de información sintáctica y semántica para federar recursos de información entre socios. Hablamos de esquemas de correspondencia basados en métodos de aprendizaje no supervisado: el proceso para identificar automáticamente los elementos semánticamente vinculados.
Así pues, nuestro objetivo es automatizar este proceso con un esquema general de correspondencia que tome dos esquemas de información construidos de forma diferente y produzca uno consistente y semánticamente comprensible.
Como los mensajes son sólo textuales, utilizamos métodos de Procesamiento del Lenguaje Natural (PLN) para detectar la compatibilidad semántica entre los campos de texto.
Un enfoque semántico de mediación para el intercambio de datos entre esquemas
Elección de los parámetros de entrada
Hay que tener en cuenta diferentes parámetros:
- El número de palabras similares: Las palabras se traducen en vectores en el algoritmo. Si hay muchas palabras similares, hay que tener en cuenta que los datos estarán cerca unos de otros (los llamamos vecinos).
- El umbral de aceptación: debe determinarse al principio del algoritmo. Si la distancia entre dos vectores está por debajo de este umbral, los campos pueden considerarse coincidentes, aunque, si la distancia está por encima, la coincidencia no se acepta.
- Los principales candidatos a considerar en la salida: Define el número de términos a considerar al generar los campos de coincidencia. En efecto, durante el proceso se ordenará una lista de candidatos. Esta lista puede ser exhaustiva o no.
Recogida de datos
En el proceso de mediación, tendremos dos esquemas en un formato similar o diferente. El primer paso del proceso será convertirlos en un formato común, conocido y fácil de manipular (CSV, por ejemplo).
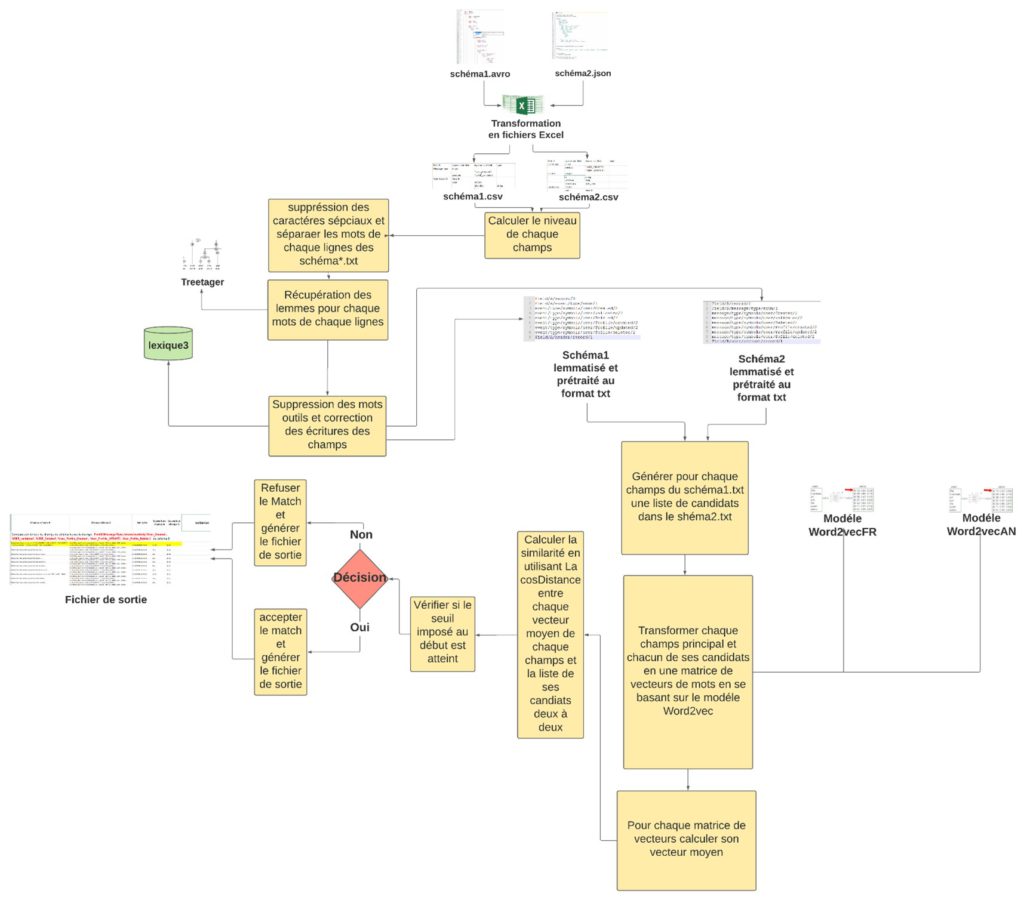
Preprocesamiento de esquemas
Se trata de un paso fundamental en el proceso de emparejamiento. Elimina el ruido de los datos que repercute negativamente en el modelo de cálculo de la similitud (llamamos "ruido" a la variante ortográfica de una misma palabra. Puede ser un error ortográfico o la forma plural de una palabra). Para este paso, aplicamos un preprocesamiento que debe "limpiar" los datos. Hemos creado una cadena de procesos (figura 1):
- Cálculo de los campos de nivel: Se refiere a la posición del campo en la estructura del código.
- Caracteres especiales supresión y la separación de campos en las secuencias de palabras.
- Recuperación del lema: El lema es el infinitivo del verbo y la forma masculina singular de un nombre, un adjetivo o un adverbio. El objetivo de la recuperación de lemas es agrupar los términos que expresan una idea similar para mostrar si los campos son coincidentes o no. La lematización tiene en cuenta el contexto de la palabra que se ha utilizado y encuentra su forma "común".
- Supresión de palabras de parada: Las stop words son muy frecuentes y no contribuyen a la comprensión. Hemos constituido una lista de stop words en francés e inglés con 890 palabras (pronombres, por ejemplo).
- Corrección de errores ortográficos: Las palabras mal escritas no pueden ser lematizadas y no serán reconocidas por nuestro modelo. Para evitar este problema, establecimos una similitud ortográfica en nuestra solución para identificar palabras similares y evitar errores tontos debidos a la ortografía.
Pasos de los esquemas de concordancia
El primer paso de los esquemas de concordancia es generar una lista de candidatos que consiste en listar las palabras candidatas para cada campo del esquema 1 y del esquema 2. Esta lista dependerá del número de palabras similares definidas previamente y la coincidencia sólo se aplicará sobre esta lista. La segunda etapa consiste en transformar los términos en vectores. Las palabras de los dos esquemas originales pueden estar en idiomas diferentes, por lo que es imprescindible traducirlas a un mismo lenguaje: un espacio de un vector. A partir de estos datos, podemos construir la matriz de vectores y calcular las unidades medias para representar un campo con un solo vector. A partir de esta información, el algoritmo podrá ver si los campos son similares o no comparándolos con el umbral determinado anteriormente.

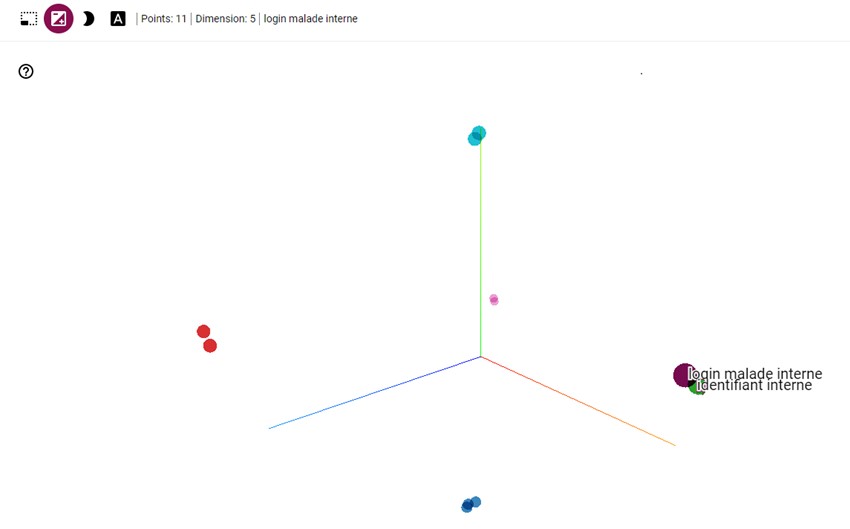
Como se puede observar en la figura, la cercanía de los puntos en la nube determinará la similitud de los campos.
Experimentación y resultados
En la tabla siguiente (figura 4), sintetizamos el resultado de nuestras diferentes experimentaciones y sus evaluaciones. V1, V2, V3 y V4, representan nuestras cuatro variantes según el número de términos vecinos y el umbral que hemos configurado.
- En nuestra primera experimentación, probamos nuestro enfoque de emparejamiento de esquemas en los dos esquemas siguientes: Especificación de evento de rol de aplicación y evento de rol de tipo de mensaje.
- En el curso de la segunda experimentación, medimos el beneficio de nuestro enfoque de correspondencia de esquemas en el sector sanitario. Probamos nuestros esquemas de correspondencia en dos esquemas denominados Sincronización de pacientes y Datos médicos internos de pacientes que construimos manualmente.
- Para la última experimentación, probamos la lematización y la corrección ortográfica de nuestro enfoque utilizando el mismo esquema que en la experimentación 2 sin aplicar la lematización y la corrección ortográfica.

La precisión es la relación entre el par correctamente emparejado y el número de pares emparejados
La recuperación es la relación entre el par correctamente emparejado y el número de pares a emparejar
FMesure es la medida armónica entre Precision y Recall
Los resultados de la experimentación muestran que la consideración de los campos de nivel tiene un beneficio en nuestro enfoqueEn efecto, en el curso de la coincidencia de campos, la F-Mesure llega hasta 83% cuando definimos un número de palabras vecinas.
Los resultados de la tercera experimentación muestran el importancia de la lematización y la corrección ortográfica. Han mejorado el F-Mesure en 35% y permiten cubrir más términos en inglés y francés.
Mediante los experimentos 1 y 2 con V1, observamos que con un umbral menor que 1 (0,6) nuestro enfoque sigue cubriendo una gran parte de los campos. Además, el compromiso que elegimos entre el número de "vecinos" y el umbral dio mejores resultados.
En resumen, pudimos observar los mejores resultados a través de nuestro primer enfoque que incluye la lematización y la ortografía corrección. Aunque sería interesante explorar más el tipo de campos y el enfoque distintivo para la coincidencia de esquemas (como los principales términos candidatos y el tipo de campos, por ejemplo).



