Code generation has gradually become a prominent aspect of today’s software development. The process of writing software requires developers to frequently rewrite similar code repeatedly. This practice can be both time-consuming and tedious. Developers aim to occasionally write abstraction to keep their applications DRY (do not repeat yourself), however writing an abstraction is not always optimal, it can make the produced code less clear and harder to work on. This is where code generation comes in handy, it can present an effective means to manage the tedious labor of rewriting repetitive and boilerplate code. Presently at Berger-Levrault (BL), the development of modules/connectors for publication and consumption of data, ensuring the interoperability of internal and external systems is done manually. Further, the remediation of malfunctions is done on an ad hoc basis. In addition to the development and correction costs involved, this does not meet the reactivity requirements of certain business domains. Hence the need to build adaptable exchange systems using interoperability nodes that are partially or completely automatically generated. Thus, helping to manage the complexity of developing such interoperability connectors from scratch and reduce the time of manually rewriting their code.

Interoperability and BL.MOM
The concept of interoperability has become an essential criterion to be met by information systems. When information systems are put into production, they are part of a network of multiple systems. If these systems can share and exchange information without depending on the intervention of a particular actor, we can label them as interoperable systems. Once interoperability is established between communicating information systems, it ensures an increase in the productivity and efficiency of intra- and inter-enterprise processes. The lack of interoperability among applications and their sub-systems is a critical issue that can affect the overall quality of service.
Data interoperability is implemented through data transport and exchange systems, the latter must be reliable and secure to guarantee a high level of interoperability. In the context of data interoperability, BL MOM (Message Oriented Middleware) is an API developed by Berger Levrault as one of the means for setting up data exchanges among BL communicating applications and with external ones. BL MOM is a messaging-based API, meaning that data is conveyed in the form of messages. The sending and receiving of messages are handled by establishing a publish/subscribe communication pattern allowing the applications to be loosely coupled. BL MOM does that by using the AMQP protocol with the support of RabbitMQ that implements the concepts of this protocol. For more information on RabbitMQ and its overall process, the reader is referred to [1] and [2].
Code generation: solutions and techniques
Code generators are programs that can produce the source code for another piece of software, helping developers to solve repetitive code problems that cannot be solved by writing abstractions. Such tools can be beneficial in increasing code quality and productivity, easing maintenance, and shortening the development time of software. Moreover, a generated code would most probably contain fewer errors and could be easily adapted to maintain the evolution of the generated software. The use of automatic/semi-automatic configuration and generation techniques to produce message schema creators and connector modules ensuring interoperability in the context of Berger-Levrault would promote the reusability of existing code and the possibility of on-the-fly generation of interoperability modules. In turn, this generation process should help to reduce the time and effort required to develop new connectors from scratch whenever the need arises. This will subsequently promote the principle of automatic linking of the senders and receivers of the data exchanged, under the control of a trusted authority.
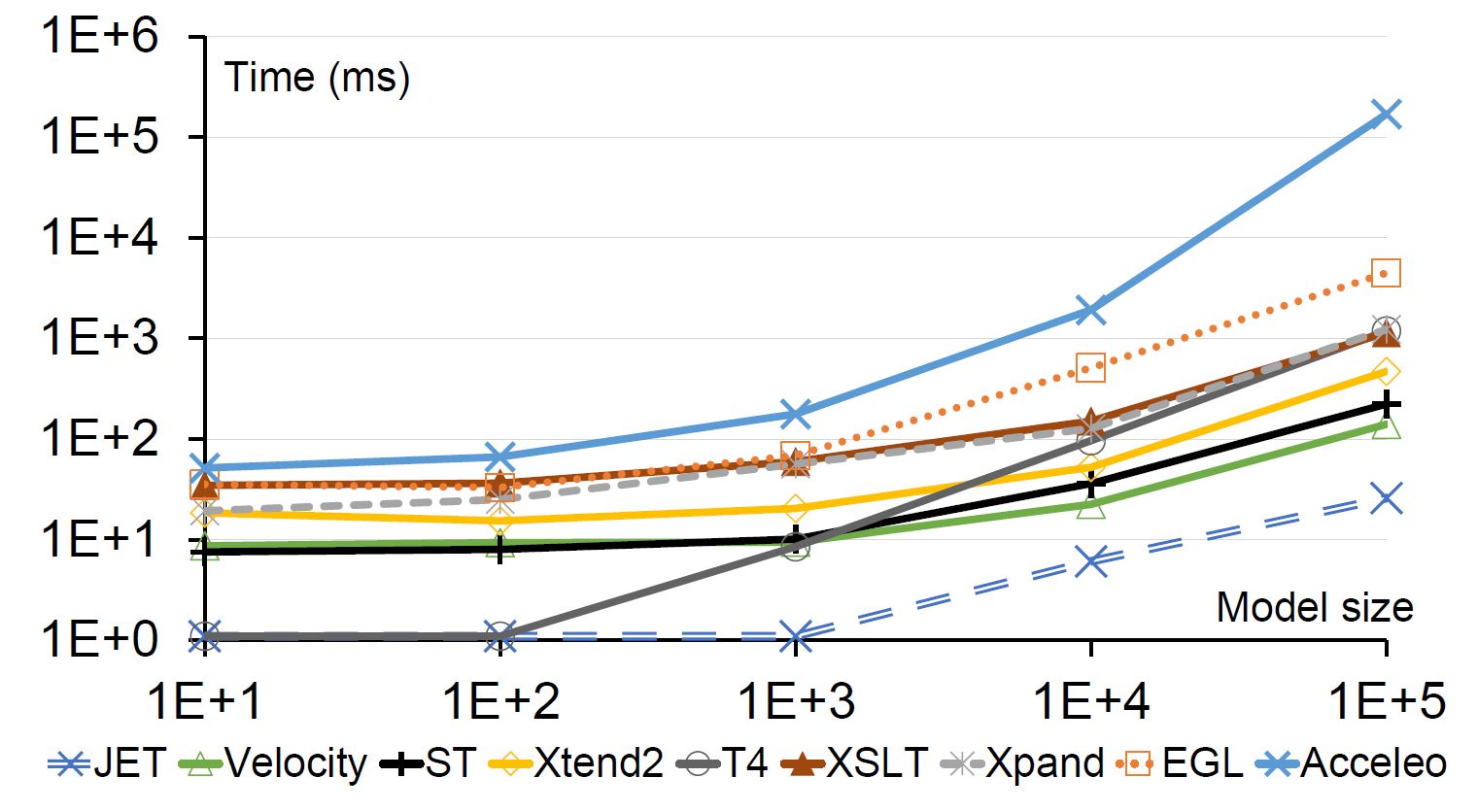
Over the years, many code generation tools and methods have been proposed. Template-based code generation (TBCG) of model-driven engineering (MDE) is arguably one of the most popular Model-to-Text techniques. Tools based on TBCG can be classified into two main groups: model-based and code-based tools. On one hand, model-based tools allow generating boilerplate code of an application from an abstract meta-model defined usually as UML diagrams. Different model-based tools have been proposed, such as Acceleo, Xpand, Xtend 2, and EGL. On the other hand, code-based tools take a textual model/template as an input to produce code in a chosen language as an output. As an example of such tools: JET, Apache Velocity, and FreeMarker. Model-based tools are the most capable of complex input data manipulations, providing adequate support for non-trivial patterns. While code-based tools have been proven to outperform the latter in many studies, especially when it comes to handling larger models. Such tools are widely used for boilerplate code generation, however, there are several others designed to perform transformation and code generation while adopting various Model-to-Text or Text-to-Text techniques. Some of these tools are code parsers that are better suited to intuitive, straightforward, and more specific code generations, such as ANTLR, Roaster, and JavaParser.
Reverse engineering tools such as MoDisco can be beneficial in the context of code generation. The idea MoDisco was built on, which consists of the extraction of models from existing legacy systems can be helpful in handling their complexities. Thus, it provides useful support to reason about, reuse, and evolve the systems.
BL MOM Connector Generator
BL MOM connector generator is the name of our proposal for the automatic generation of entire/part of interoperability connectors to be used by our applications. The generator can produce based on configuration parameters: message publication/consumption modules, messages schema creators, message wrappers, and auto-configuration modules. The main purpose behind this is to ease the complexity of writing the code of new connectors and schema creators from scratch and reduce their global development time. More specifically, our tool can generate the context of interoperability once for several consumers and publishers, which consists of:
- An auto-configuration project to support configuration structures and auto-configuration;
- A message wrapper project for handling message types;
- A message schema definition project encapsulating message schemas libraries and specification (when Avro is used) and all elements that are common to all connectors of the same data exchange (business context). In addition, it generates skeletons of the consumer and publisher projects to be enriched by the developers.
Interoperability modules in BL are more often developed as Spring Boot applications, thus we have elected to employ certain Java APIs/tools that would allow generating customized skeletons of interoperability modules, and whole projects of message schema creators, message wrappers, and auto-configuration. Particularly, among other libraries, we use (i) Spring Initializr for generating Java project skeletons, (ii) Java Roaster for class code generating, and (iii) Apache Velocity for the generation of projects POMs, Html files for specification, and other files. In combination, these tools are used to generate ready-to-use Spring Boot applications, adapted to meet initial interoperability objectives. The choice of tools was made after assessing different model-based tools for code generation, as well as a few code-based and reverse engineering tools. We concluded that this kind of tool is not suited for our particular needs, consisting of the generation of repetitive code within our interoperability modules. In fact, we believe a solution based on tools such as Xtend2, Modisco, JHipster, etc would lack the desired flexibility, which is crucial for our perspectives. The optimal solution would be easily adaptable to meet different requirements old and new and would allow considering advanced use cases in the future, such as adapting existing connectors, message schemas, etc.
The first step, before proceeding to code generation, is to analyze the existing code of connector modules and message schema definition projects, to differentiate between redundant and variable elements in the code. The latter can represent the input data for the generation system that must be considered to customize each generated project to a given business context. To do this, we rely on a formalization at a meta-level describing the representation and the existing relationships between the variable elements that enable the configuration of a connector and a message schema definition module.
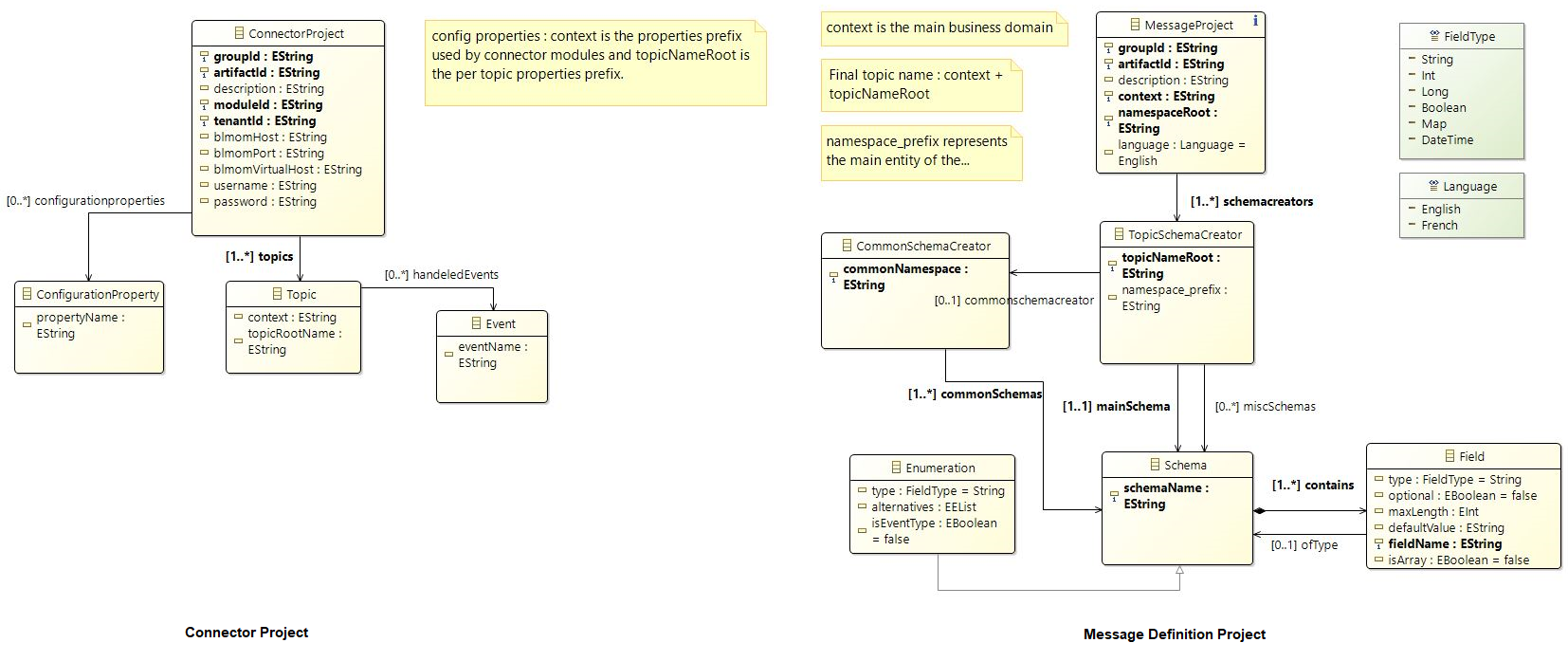
Each connector module has a set of predefined properties related to the java module to be generated, to the properties required as input by BL-MOM such as the module, tenantId, or to the connection credentials to the RabbitMQ server. It is also possible to have project-specific configuration properties. Each connector module is linked by publishing or subscribing to one or more Topics, each of which can convey a set of business events. The message schema definition modules allow the creation of Java libraries of Apache Avro messages, and to maintain documentation compatible with the code. In this case, the full code for this kind of project can automatically be generated from a definition of the message schemas to be included in the project. A message schema is characterized by a Topic of interest, a set of sub-schemas, and the definition of the fields making up each schema: the name, the maximum size, whether it is optional or not, and its type. The latter can itself be a sub-schema.
In order to initially generate a skeleton for the various kinds of interoperability modules projects, an instance of a Spring Initializr server is used. To interact with this server, we use the Spring Initializr REST API to be able to provide the configuration parameters of the project we desire to generate. The main advantage of using our own deployed Spring Initializr instance is that we could customize the generated skeletons according to our specific needs. For instance, by setting a specific version of Java, or by adding our own dependencies that would not be included in the public Spring Initializr.
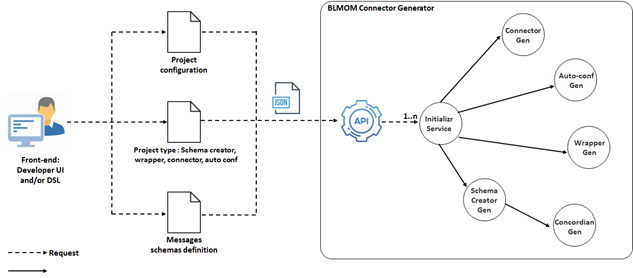
The architecture of BL MOM connector generator consists of a set of loosely coupled REST services, each performing specific generation tasks and communicating with each other through their endpoints to generate different types of projects, according to configuration parameters received from end-users in terms of JSON messages:
- The Initializr service is responsible for producing customized Spring projects skeletons by interacting with the Spring Initializr server.
- The schema creator generation service generates projects for creating Java libraries of Apache Avro messages. It also calls for the Concordian generation service to maintain Html specifications of these messages compatible with their code.
- The connector generation service oversees the generation of parts of message production and consumption modules of one or more existing Topics. These modules need to be completed to address business context-related code, in which we can specify for example what needs to be done after receiving a message.
- Finally, message wrapper and auto-configuration generation services generate modules that correspond to their respective names.
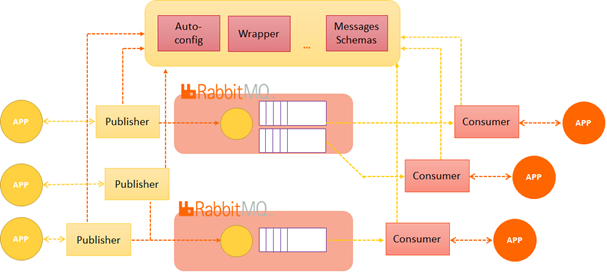
BL MOM connector generator makes it possible to automatically create not only message schema definition projects, message wrapper, and auto-configuration projects, but also as many publishers and consumers as needed for the same data exchange context. In other words, a wrapper is generated once for each interoperability context, and as many connectors as required are created for each new need.