
1. Strategic Context and Challenges
Modern answer engines look simple from the outside: a user asks a question, and the system returns a grounded answer. But before the language model can write anything useful, the system must first retrieve the right sources from the enterprise knowledge base. If the right sources are not selected, the answer engine is already limited, no matter how powerful the language model is.
In most enterprise RAG systems, this first step is handled by a search layer that combines embeddings, vector search, and sometimes lexical retrieval such as BM25. The goal is to bring the most relevant chunks into the context window of the language model. The difficulty is that business documentation is rarely written like user questions. Users ask in natural, incomplete, sometimes telegraphic language, while documents contain product names, legal terms, modules, procedure names, error codes, and domain-specific wording.
This is where generic embedding models can struggle. They are trained to capture broad semantic similarity, which is useful, but business search often requires finer distinctions. Two chunks may look semantically close while only one is operationally correct. For an answer engine, this difference is crucial: a near miss is still a miss if the correct source does not appear in the top retrieved results.
This article presents a lightweight approach to embedding adaptation for enterprise retrieval and RAG-ready search systems. Instead of fine-tuning the embedding model itself, the method learns a compact query-side transformation matrix that improves retrieval quality while preserving the existing document embeddings and vector index. Our experimental use case is French-language assistance for Berger-Levrault software. However, the method is independent of the use case and of the language: it can be applied to any corpus as long as embeddings can be produced and post-processed.
Figure 1 frames the initial problem: generic embeddings can be noisy, disconnected, and ambiguous for business search. The proposed adaptation makes the query representation more aligned with the enterprise domain, so the retrieval system has a better chance of surfacing the right sources before generation begins.

2. Why retrieval is the real bottleneck in RAG?
In Retrieval-Augmented Generation, retrieval is the gate through which knowledge enters the answer. The language model does not inspect every document. It only sees the small set of chunks selected by the retriever. If relevant chunks are missing from the top results, the model cannot reason over them, even if the model itself is highly capable.
Generic embedding models are trained for broad semantic similarity. This is useful, but enterprise search often requires more precise distinctions: the right procedure, the right error resolution, the right regulatory rule, or the right product documentation chunk. A semantically close but operationally wrong result is still a retrieval failure.
For example, a support question may mention a symptom, while the documentation describes the underlying configuration step. Or a user may refer to a business concept with informal wording, while the source uses a regulatory or product-specific term. A generic embedding model can understand that the texts are related, but it may not always rank the exact source high enough for a RAG system that only passes a few chunks to the generator.
Research question. Can we adapt the query embedding space enough to improve Top-K retrieval, without replacing the embedding model and without re-indexing the document corpus?
3. Why learn a matrix instead of fine-tuning a model?
Full embedding-model fine-tuning can be effective, but it is operationally heavy. It requires training infrastructure, governance around model versions, validation, and often re-embedding or re-indexing large document collections. This can become a blocker, especially when the embedding model is a commercial model provided by vendors such as OpenAI or Mistral AI.
The alternative explored here is lighter: learn a transformation matrix applied after the query embedding has been produced. The output of learning is not a new embedding model. It is a compact adaptation layer. This makes the approach compatible with both open models and commercial models. As long as the embedding vector can be post-processed, the learned matrix can be applied. In practice, learning this matrix is light enough to run on a CPU, which changes the economics of domain adaptation.
This direction is closely aligned with the Chroma Embedding Adapters report, which studies learned linear transformations above frozen embeddings to improve retrieval without changing the underlying embedding model (Sanjeev and Troynikov, 2024).
4. Method overview
The pipeline is deliberately modular and reproducible:
a. Generate synthetic questions from a representative sub-corpus.
b. Mine hard negatives through Weaviate instead of sampling random negatives.
c. Learn a linear query-side matrix from triplets: query, relevant chunk, hard negative chunk.
d. Run a second pass by using the first adapted queries to mine harder negatives.
e. Evaluate Top-4 coverage in dense retrieval and hybrid retrieval (dense + BM25).
f. Deploy query-only adaptation while keeping document embeddings and the vector index unchanged.
4.1. Synthetic data generation
The approach does not rely on manually labeled training data. Instead, synthetic questions are generated from enterprise chunks. Figure 2 illustrates the first module of the pipeline: enterprise chunks are converted into realistic synthetic questions, creating scalable supervision without requiring manually labeled user logs.
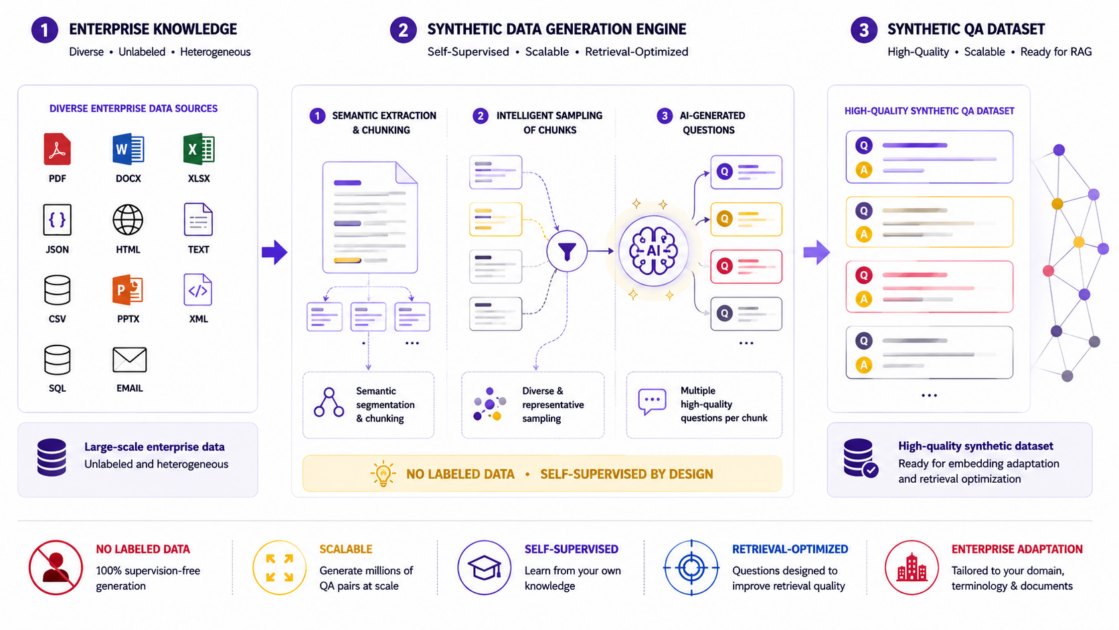
Two prompt strategies are used:
- Zero-shot generation: the model receives the chunk title, content, and keywords, then generates realistic support questions.
- Few-shot generation: the prompt includes real-style examples so the generated questions imitate the tone and style of actual user queries.
The prompt structure is important because it controls the quality of the supervision signal. It asks for questions that are natural, concrete, grounded in the source chunk, written in the same language as the source, and returned as strict JSON.
Prompt structure
System role:
You are a realistic customer-question generator.
Always follow the user's instructions and return only valid JSON.
Prompt anatomy:
Context:
- document title
- trusted content chunk
- extracted keywords
Objective:
- generate 4 distinct questions
- cover several intents: procedure, eligibility, troubleshooting, timing,
pricing, comparison
- keep the language natural and concrete
Constraints:
- answers must be inferable from the chunk
- do not mention "according to the document"
- no unsupported assumptions
- use the same language as the source content
Strict output:
{
"query1": "...",
"query2": "...",
"query3": "...",
"query4": "..."
}4.2. Hard-negative mining
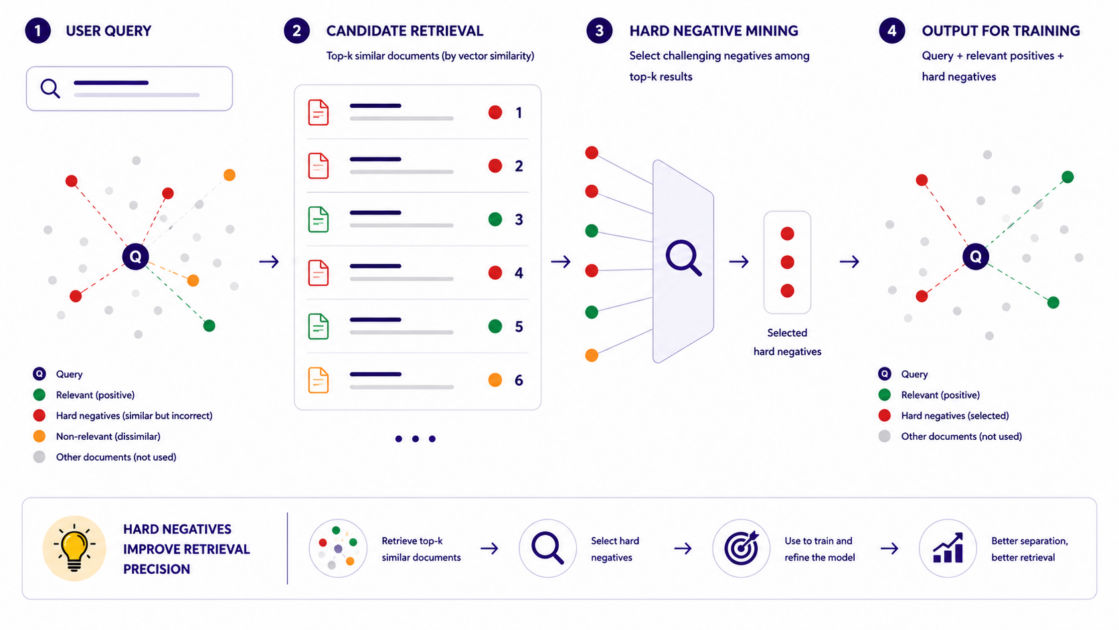
Random negatives are often too easy. They teach little because they are already far away from the query in embedding space. Instead, the method mines hard negatives: chunks that are semantically close to the query but are not the relevant source.
In pass 1, Weaviate is queried with the raw synthetic query. The true positive is removed, and the closest incorrect chunks are kept as negatives. In pass 2, Weaviate is queried with the already adapted query from the first learned matrix, which produces harder and more informative negatives.
Hard-negative mining is a central ingredient in modern retrieval model training; in our setting, it is reused in a lighter way to learn an embedding transformation rather than fine-tuning the full embedding model.
This is where NV-Retriever is especially relevant. Moreira et al. (2025, arXiv v2; first submitted in 2024) emphasize that the quality of hard negatives is central to contrastive retrieval training. In this work, the same principle is reused, but the training target is a lightweight transformation matrix rather than the full embedding model.
Figure 3 shows this hard-negative mining logic: for each query, the system keeps examples that are close enough to be confusing, but incorrect enough to teach the adapter sharper retrieval boundaries.
4.3. Learning the query-side transformation
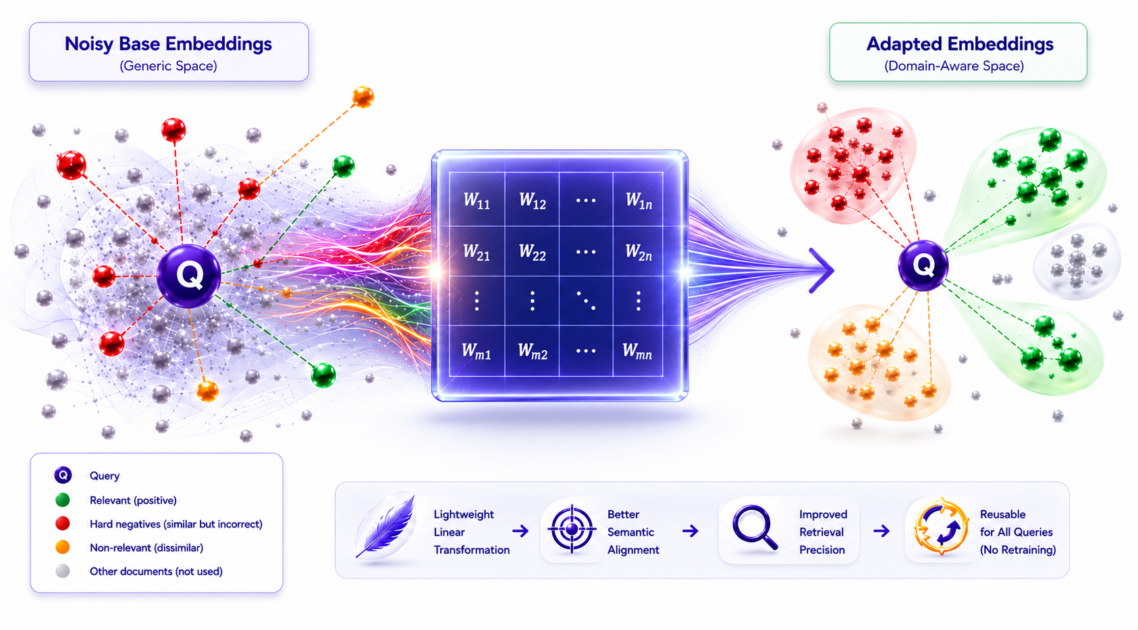
The learning problem is simple to state. For a query embedding q, a positive document embedding d+, and a hard negative embedding d-, learn a matrix W such that the adapted query qW is closer to d+ than to d- under cosine distance.
The prototype uses triplet supervision rather than a binary classification signal. This matters for retrieval because the model must learn relative ranking, not simply whether an isolated pair is positive or negative.
Several stability choices are used:
- Identity initialization: the adapter starts as a no-op.
- L2 normalization: vectors are normalized for cosine distance.
- Regularization toward identity: the learned matrix is discouraged from distorting the space too much.
- Spectral norm control: the transformation is bounded to reduce instability.
- Mini-batch training: triplets are processed in batches to control memory usage.
Figure 4 visualizes the learned transformation: the matrix adapts only the query embedding so that it better points toward relevant domain clusters, while the document embeddings remain unchanged.
square matrix with m=n which is the number of embedding dimensions).5. Experimental use case: Berger-Levrault assistance
The experiment was conducted on a French-language assistance use case for Berger-Levrault software. The working subset used for question generation contained roughly 300 chunks from 56 documents. The larger base used for hard-negative mining contained more than 15,000 documents and 42,000 chunks.
From 300 chunks and four generated questions per chunk, the process creates around 1,200 query-positive pairs. By retrieving up to 100 hard negatives for each query, the triplet dataset reaches about 120,000 examples: 111,073 triplets for pass 1 and 116,686 triplets for pass 2.
Important nuance. The use case is French and product-specific, but the method is not. The same pipeline can be applied to another language, another corpus, or another embedding provider, because the adaptation layer only sees vectors.
6. Evaluation results
The main evaluation metric is Top-4 coverage: the proportion of reference chunks found in the first four retrieved results. This is especially relevant for RAG systems, where only a small number of chunks are usually passed to the generator. Figure 5 summarizes the evaluation visually, showing how the adapted settings improve dense retrieval and especially hybrid retrieval compared with the baseline.
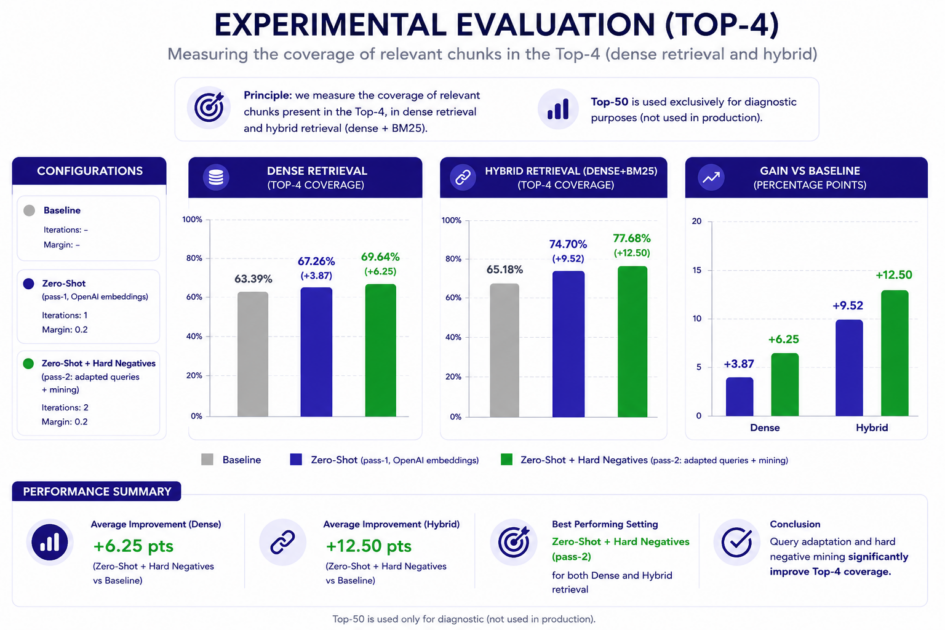
The strongest result is obtained with query adaptation plus hard-negative mining in hybrid retrieval. Top-4 coverage increases from 65.18% to 77.68%, a gain of 12.50 percentage points.
7. Positioning in the state of the art
The most accurate framing is not “we fine-tune embeddings”. It is: “we learn a lightweight query-side embedding transformation from retrieval supervision”.
This places the approach between three families of methods:
- Full embedding-model fine-tuning: powerful, but operationally expensive.
- Parameter-efficient adapters: smaller trainable modules that adapt a model while leaving most parameters frozen.
- Post-hoc vector-space adaptation: transformations applied after embeddings are produced.
Recent work supports this positioning. Chroma’s Embedding Adapters report is the closest practical reference, because it studies learned linear transformations above frozen embeddings for retrieval improvement (Sanjeev and Troynikov, 2024). Schopf, Schneider and Matthes (2023) show that adapter-based sentence embedding adaptation can approach full fine-tuning while training only a small fraction of the parameters. Moreira et al. (2025, arXiv v2) show the central role of hard-negative mining in modern retrieval model training.
Older work provides conceptual grounding. Faruqui et al. (2015) introduced retrofitting methods that specialize pre-trained vector spaces after initial training by injecting external semantic constraints. Yang et al. (2018) studied linear transformations between word embedding spaces, supporting the geometric intuition that a compact learned matrix can sometimes align useful semantic structure.
8. Limits and next steps
A linear matrix should not be presented as a universal replacement for fine-tuning. It is a pragmatic intermediate option when full embedding-model training is too costly, when document indexes are expensive to rebuild, or when the base embedding provider cannot be modified.
- Dense-only gains are meaningful but more modest than hybrid gains.
- Hard-negative mining provides most of its value early; too many iterations may lead to diminishing returns.
- Margins and learning rates remain sensitive and should be selected against validation data.
- Future work can explore InfoNCE objectives, Top-K reranking, MMR diversification, and public benchmark comparisons.
9. Conclusion
The core lesson is operational as much as technical: enterprise RAG teams can adapt retrieval behavior without owning or fine-tuning the embedding model itself. By learning a small query-side transformation from synthetic questions and hard negatives, the system becomes more domain-aware while staying deployable.
For the Berger-Levrault French assistance use case, this approach translated into a measurable hybrid Top-4 improvement of 12.50 percentage points, with no document re-indexing and no new embedding model to serve.
10. References
- Sanjeev, S. and Troynikov, A. (2024). “Embedding Adapters”. Chroma Technical Report.
- Moreira, G. de S. P., Osmulski, R., Xu, M., Ak, R., Schifferer, B. and Oldridge, E. (2025). “NV-Retriever: Improving Text Embedding Models with Effective Hard-Negative Mining”. arXiv:2407.15831v2, last revised 7 February 2025; first submitted 22 July 2024.
- Schopf, T., Schneider, D. N. and Matthes, F. (2023). “Efficient Domain Adaptation of Sentence Embeddings Using Adapters”. RANLP 2023 / arXiv:2307.03104.
- Yang, X., Ounis, I., McCreadie, R., Macdonald, C. and Fang, A. (2018). “On the Reproducibility and Generalisation of the Linear Transformation of Word Embeddings”. ECIR 2018.
- Faruqui, M., Dodge, J., Jauhar, S. K., Dyer, C., Hovy, E. and Smith, N. A. (2015). “Retrofitting Word Vectors to Semantic Lexicons”. NAACL-HLT 2015.



